reduceByKey()
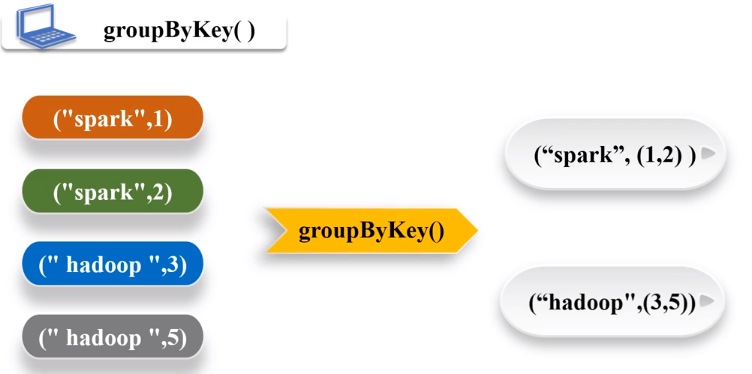
groupByKey() 对具有相同键的值进行分组
package com.zwq
import org.apache.spark.{SparkConf, SparkContext}
object PairsRDD extends App {
val conf = new SparkConf().setAppName("testPartitioner").setMaster("local")
var sc = new SparkContext(conf)
var words = Array("one", "two", "two", "three", "three", "three")
val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
val wordCountsWithReduce = wordPairsRDD.reduceByKey(_ + _)
val wordCountsWithGroup = wordPairsRDD.groupByKey().map(t => (t._1, t._2.sum))
wordCountsWithGroup.collect().map(println)
}
keys() 把Pair RDD中的key返回形成一个新的RDD
values()
sortByKey() true 升序 false降序
sortBy(func)
mapValues(func) 对键值对RDD中的每个value都应用一个函数,key不会发生变化
join 把几个RDD当中元素key相同的进行连接
package com.zwq
import org.apache.spark.{SparkConf, SparkContext}
object PairRDDJoin extends App{
val conf = new SparkConf().setAppName("testPartitioner").setMaster("local")
var sc = new SparkContext(conf)
val pairRDD1 = sc.parallelize(Array(("spark", 1), ("spark", 2), ("hadoop", 3), ("hadoop", 5)))
val pairRDD2 = sc.parallelize(Array(("spark", "fast")))
pairRDD1.join(pairRDD2).foreach(println)
}
结果