版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/yulei_qq/article/details/82498462
1、 将一个普通的RDD转换为键值对RDD时,可以通过调用map()函数来实现,传递的函数需要返回键值对。
scala 版:
scala> val lines =sc.parallelize(List("pandas","i like pandas"));
lines: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> val pairs = lines.map(x => (x.split(" ")(0),x))
pairs: org.apache.spark.rdd.RDD[(String, String)] = MapPartitionsRDD[1] at map at <console>:25
Java 版:
需要专门的Spark 函数来创建pari RDD 。例如,要使用 mapToPair() 函数来代替基础版的map()函数。
public class Test2 {
public static void main(String[] args) {
SparkConf conf =new SparkConf();
conf.setMaster("local") ;
conf.setAppName("test");
JavaSparkContext sc= new JavaSparkContext(conf);
//得到一个RDD
JavaRDD<String> rdd1 = sc.textFile("d:/logs/*");
//将普通的RDD换换为键值对RDD
JavaPairRDD<String,String> rdd2 = rdd1.mapToPair(new PairFunction<String, String, String>() {
@Override
public Tuple2<String, String> call(String s) throws Exception {
return new Tuple2(s.split(" ")[0],s);
}
});
//获取rdd2中的所有数据
List<Tuple2<String,String>> list= rdd2.collect();
//打印数据
for (Tuple2<String,String> tuple2:list){
System.out.println(tuple2._1+" :"+tuple2._2);
}
}
}以上代码就是将文本每一个行的第一个元素作为key ,然后打印输出.
测试文件下载地址:两个文本文件
打印出的结果如下:
hello :hello ssss world
hello :hello tmo byees
wolrd :wolrd sss asdfd
hello :hello tomles lovely
hello :hello ssss world
hello :hello tmo byees
wolrd :wolrd sss asdfd Java 从内存数据集创建pair RDD的话,则需要使用SparkContext.parallelizePairs()。
2、Pair RDD的相关转化操作
由于pair RDD中包含二元组,所以需要传递的函数应当操作二元组而不是独立的元素。以下表记录了pair RDD的一些转化操作。



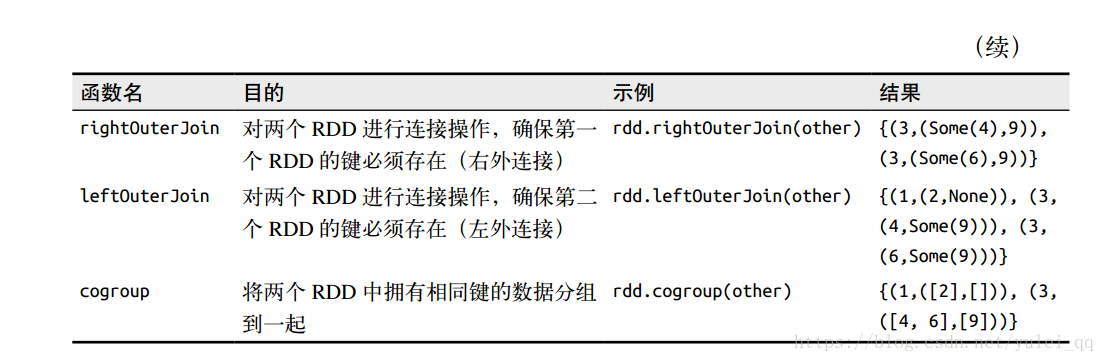
聚合操作---combineByKey
def combineByKey[C](createCombiner: (V) => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RD- createCombiner: combineByKey() 会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就
和之前的某个元素的键相同。如果这是一个新的元素, combineByKey() 会使用一个叫作 createCombiner() 的函数来创建
那个键对应的累加器的初始值 - mergeValue: 如果这是一个在处理当前分区之前已经遇到的键, 它会使用 mergeValue() 方法将该键的累加器对应的当前值与这个新的值进行合并
- mergeCombiners: 由于每个分区都是独立处理的, 因此对于同一个键可以有多个累加器。如果有两个或者更
多的分区都有对应同一个键的累加器, 就需要使用用户提供的 mergeCombiners() 方法将各
个分区的结果进行合并。
如下是一个求平均数的例子
package com.study;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import scala.Serializable;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* @author : yulei
* @data : 2018/9/7 17:44
* @Version : 1.0
**/
public class TestCombinKey {
static class AvgCount implements Serializable {
public int total_;
public int num_;
public AvgCount(int total_, int num_) {
this.total_ = total_;
this.num_ = num_;
}
public float avg(){
return total_/num_;
}
}
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("TestCombinKey").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
Tuple2<String,Integer> t1= new Tuple2("coffee",1);
Tuple2<String,Integer> t2= new Tuple2("coffee",2);
Tuple2<String,Integer> t3= new Tuple2("panda",1);
Tuple2<String,Integer> t4= new Tuple2("coffee",9);
List list =new ArrayList<Tuple2>();
list.add(t1);
list.add(t2);
list.add(t3);
list.add(t4);
JavaPairRDD<String ,Integer> rdd1= sc.parallelizePairs(list,2);
//相当于createCombiner
Function<Integer,AvgCount> createAcc = new Function<Integer, AvgCount>() {
@Override
public AvgCount call(Integer x) throws Exception {
return new AvgCount(x,1);
}
};
// 相当于mergeValue
Function2<AvgCount,Integer,AvgCount> addAndCount = new Function2<AvgCount, Integer, AvgCount>() {
@Override
public AvgCount call(AvgCount a, Integer x) throws Exception {
a.total_+=x;
a.num_+=1;
return a;
}
};
//mergeCombiners
Function2<AvgCount,AvgCount,AvgCount> combine = new Function2<AvgCount, AvgCount, AvgCount>() {
@Override
public AvgCount call(AvgCount a, AvgCount b) throws Exception {
a.total_+=b.total_;
a.num_+=b.num_;
return a;
}
};
AvgCount initial = new AvgCount(0,0);
JavaPairRDD<String,AvgCount> avgCounts = rdd1.combineByKey(createAcc,addAndCount,combine);
Map<String, AvgCount> countMap = avgCounts.collectAsMap();
for (Map.Entry<String, AvgCount> entry : countMap.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue().avg());
}
}
}
运行后得到的结果:
coffee:4.0
panda:1.0数据分组----- 比如查看一个顾客的所有订单
对于一个由类型K的键和类型V的值组成的RDD,所得到的结果类型会是[K , Iterable[V] ]