#3-5-4聚类算法的对比与评估
import mglearn
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from numpy.core.umath_tests import inner1d
from mpl_toolkits.mplot3d import Axes3D,axes3d
from scipy.cluster.hierarchy import dendrogram,ward
from sklearn.cluster import KMeans,AgglomerativeClustering,DBSCAN
from sklearn.datasets import load_breast_cancer,make_moons,make_circles,make_blobs
from sklearn.datasets import load_iris,fetch_lfw_people,load_digits
from sklearn.decomposition import NMF,PCA
from sklearn.ensemble import RandomForestClassifier,GradientBoostingClassifier
from sklearn.svm import SVC,LinearSVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.manifold import TSNE
from sklearn.metrics import accuracy_score
from sklearn.metrics.cluster import adjusted_rand_score,silhouette_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import MinMaxScaler,StandardScaler
x,y = make_moons(n_samples=200,noise=0.05,random_state=0)
scaler = StandardScaler() #平均值为0,方差为1
scaler.fit(x)
x_scaled = scaler.transform(x)
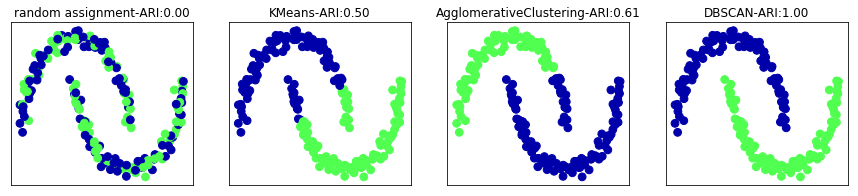
fig,axes = plt.subplots(1,4,figsize=(15,3),subplot_kw={'xticks':(),'yticks':()})
algorithms = [KMeans(n_clusters=2),AgglomerativeClustering(n_clusters=2),DBSCAN()]
random_state = np.random.RandomState(seed=0)
random_clusters = random_state.randint(low=0,high=2,size=len(x))
axes[0].scatter(x_scaled[:,0],x_scaled[:,1],c=random_clusters,cmap=mglearn.cm3,s=60)
axes[0].set_title('random assignment-ARI:{:.2f}'.format(adjusted_rand_score(y,random_clusters)))
for ax,algorithm in zip(axes[1:],algorithms): #绘制簇分配和簇中心
clusters = algorithm.fit_predict(x_scaled)
ax.scatter(x_scaled[:,0],x_scaled[:,1],c=clusters,cmap=mglearn.cm3,s=60)
ax.set_title('{}-ARI:{:.2f}'.format(algorithm.__class__.__name__,adjusted_rand_score(y,clusters)))
cluster1 = [0,0,1,1,0] #这两种标签对应于相同的聚类
cluster2 = [1,1,0,0,1]
print('accuracy:{:.2f}'.format(accuracy_score(cluster1,cluster2))) #错误评估
print('ARI:{:.2f}'.format(adjusted_rand_score(cluster1,cluster2)))
accuracy:0.00
ARI:1.00
x,y = make_moons(n_samples=200,noise=0.05,random_state=0)
scaler = StandardScaler()
scaler.fit(x)
x_scaled = scaler.transform(x)
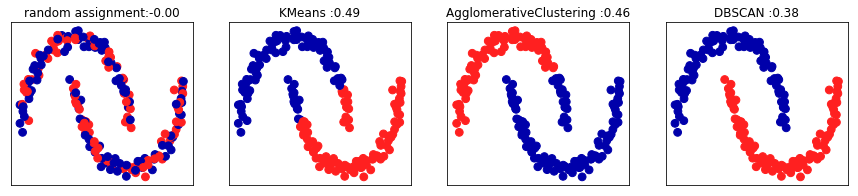
fig,axes = plt.subplots(1,4,figsize=(15,3),subplot_kw={'xticks':(),'yticks':()})
random_state = np.random.RandomState(seed=0)
random_clusters = random_state.randint(low=0,high=2,size=len(x))
axes[0].scatter(x_scaled[:,0],x_scaled[:,1],c=random_clusters,cmap=mglearn.cm2,s=60)
axes[0].set_title('random assignment:{:.2f}'.format(silhouette_score(x_scaled,random_clusters)))
algorithms = [KMeans(n_clusters=2),AgglomerativeClustering(n_clusters=2),DBSCAN()]
for ax,algorithm in zip(axes[1:],algorithms): #绘制簇分配和簇中心
clusters = algorithm.fit_predict(x_scaled)
ax.scatter(x_scaled[:,0],x_scaled[:,1],c=clusters,cmap=mglearn.cm2,s=60)
ax.set_title('{} :{:.2f}'.format(algorithm.__class__.__name__,silhouette_score(x_scaled,clusters)))
#人脸数据集的文件路径(deepin)->file:///home/s/scikit_learn_data/lfw_home,网址:https://ndownloader.figshare.com/files/5976015
people = fetch_lfw_people(min_faces_per_person=20,resize=0.7) #灰度图像,按最小比例缩小以加快处理速度
image_shape = people.images[0].shape
#counts = np.bincount(people.target) #计算每个目标出现的次数
mask = np.zeros(people.target.shape,dtype=np.bool)
for target in np.unique(people.target):
mask[np.where(people.target == target)[0][:50]] = 1 #每个人只取50张照片
x_people = people.data[mask]
y_people = people.target[mask]
x_people = x_people / 255
pca = PCA(n_components=100,whiten=True,random_state=0)
pca.fit_transform(x_people)
x_pca = pca.transform(x_people)
dbscan = DBSCAN()
labels = dbscan.fit_predict(x_pca)
print('unique labels:{}'.format(np.unique(labels)))
unique labels:[-1]
dbscan = DBSCAN(min_samples=3)
labels = dbscan.fit_predict(x_pca)
print('unique labels:{}'.format(np.unique(labels)))
unique labels:[-1]
dbscan = DBSCAN(min_samples=3,eps=15)
labels = dbscan.fit_predict(x_pca)
print('unique labels:{}'.format(np.unique(labels)))
unique labels:[-1 0]
#计算簇的点数,第一个为噪声点,+1是因为不能有负值
print('number of points per cluster:{}'.format(np.bincount(labels+1)))
noise = x_people[labels==-1] #噪声的图像
fig,axes = plt.subplots(3,9,subplots_kw={'xticks':(),'yticks':()},figsize=(12,4))
for image,ax in zip(noise,axes.ravel()):
ax.imshow(image.reshape(image_shape),vmin=0,vmax=1)

for eps in [1,3,5,7,9,11,13]: #尝试不同的簇
print('eps={}'.format(eps))
dbscan = DBSCAN(eps=eps,min_samples=3)
label = dbscan.fit_predict(x_pca)
print('cluster present:{}'.format(np.unique(labels)))
print('cluster sizes:{}'.format(np.bincount(labels+1)))
eps=1
cluster present:[-1 0]
cluster sizes:[ 32 2031]
eps=3
cluster present:[-1 0]
cluster sizes:[ 32 2031]
eps=5
cluster present:[-1 0]
cluster sizes:[ 32 2031]
eps=7
cluster present:[-1 0]
cluster sizes:[ 32 2031]
eps=9
cluster present:[-1 0]
cluster sizes:[ 32 2031]
eps=11
cluster present:[-1 0]
cluster sizes:[ 32 2031]
eps=13
cluster present:[-1 0]
cluster sizes:[ 32 2031]
dbscan = DBSCAN(min_samples=3,eps=7)
labels = dbscan.fit_predict(x_pca)
for cluster in range(max(labels)+1):
mask = labels == cluster
n_images = np.sum(mask)
fig,axes = plt.subplots(1,n_images,figsize=(n_images * 1.5,4),subplot_kw={'xticks':(),'yticks':()})
for image,label,ax in zip(x_people[mask],y_people[mask],axes):
ax.imshow(image.reshape(image_shape),vmin=0,vmax=1)
ax.set_title(people.target_names[label].split()[-1])




km = KMeans(n_clusters=10,random_state=0)
labels_km = km.fit_predict(x_pca)
print('cluster sizes k-means:{}'.format(np.bincount(labels_km)))
cluster sizes k-means:[155 175 238 75 358 257 91 219 323 172]
fig,axes = plt.subplots(2,5,subplot_kw={'xticks':(),'yticks':()},figsize=(12,4))
for center,ax in zip(km.cluster_centers_,axes.ravel()):
ax.imshow(pca.inverse_transform(center).reshape(image_shape),vmin=0,vmax=1)

mglearn.plots.plot_kmeans_faces(km,pca,x_pca,x_people,y_people,people.target_names)

#用ward凝聚聚类提取簇
agglomerative = AgglomerativeClustering(n_clusters=10)
labels_agg = agglomerative.fit_predict(x_pca)
print('cluster sizes agglomerative clustering:{}'.format(np.bincount(labels_agg)))
cluster sizes agglomerative clustering:[169 660 144 329 217 85 18 261 31 149]
print('ARI:{:.2f}'.format(adjusted_rand_score(labels_agg,labels_km)))
ARI:0.09
linkage_array = ward(x_pca)
plt.figure(figsize=(20,5))
dendrogram(linkage_array,p=7,truncate_mode='level',no_labels=True)
plt.xlabel('sample index')
plt.ylabel('cluster distance')

#凝聚聚类
n_cluster = 10
for cluster in range(n_cluster):
mask = labels_agg == cluster
fig,axes = plt.subplots(1,10,subplot_kw={'xticks':(),'yticks':()},figsize=(15,8))
axes[0].set_ylabel(np.sum(mask))
for image,label,asdf,ax in zip(x_people[mask],y_people[mask],labels_agg[mask],axes):
ax.imshow(image.reshape(image_shape),vmin=0,vmax=1)
ax.set_title(people.target_names[label].split()[-1],fontdict={'fontsize':9})


agglomerative = AgglomerativeClustering(n_clusters=40)
labels_agg = agglomerative.fit_predict(x_pca)
print('cluster sizes Agglomerative clustering:{}'.format(np.bincount(labels_agg)))
n_cluster = 40
for cluster in [10,13,19,22,36]:
mask = labels_agg == cluster
fig,axes = plt.subplots(1,15,subplot_kw={'xticks':(),'yticks':()},figsize=(15,8))
cluster_size = np.sum(mask)
axes[0].set_ylabel('#{}:{}'.format(cluster,cluster_size))
for image,label,asdf,ax in zip(x_people[mask],y_people[mask],labels_agg[mask],axes):
ax.imshow(image.reshape(image_shape),vmin=0,vmax=1)
ax.set_title(people.target_names[label].split()[-1],fontdict={'fontsize':9})
for i in range(cluster_size,15):
axes[i].set_visible(False)
cluster sizes Agglomerative clustering:[ 43 120 100 194 56 58 127 22 6 37 65 49 84 18 168 44 47 31
78 30 166 20 57 14 11 29 23 5 8 84 67 30 57 16 22 12
29 2 26 8]


