一、Given Label
均一性homogeneity:一个簇中只包含一个类别样本,Precision
完整性completeness:同类别样本被归到同一个簇中,Recall
将均一性h和完整性c进行结合(二者加权平均)得到V-Measure,,β为权重
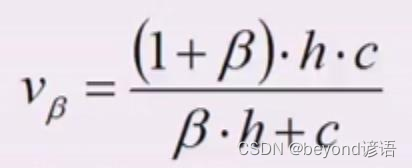
代码实现
from sklearn import metrics
if __name__ == "__main__":
y = [0, 0, 0, 1, 1, 1]#正确的分类
y_hat = [0, 0, 1, 1, 2, 2]#生成的分类
h = metrics.homogeneity_score(y, y_hat)
c = metrics.completeness_score(y, y_hat)
print(u'同一性(Homogeneity):', h)
print(u'完整性(Completeness):', c)
v2 = 2 * c * h / (c + h)
v = metrics.v_measure_score(y, y_hat)
print(u'V-Measure:', v2, v)
y = [0, 0, 0, 1, 1, 1]
y_hat = [0, 0, 1, 3, 3, 3]
h = metrics.homogeneity_score(y, y_hat)
c = metrics.completeness_score(y, y_hat)
v = metrics.v_measure_score(y, y_hat)
print(u'同一性(Homogeneity):', h)
print(u'完整性(Completeness):', c)
print(u'V-Measure:', v)
# 允许不同值
y = [0, 0, 0, 1, 1, 1]
y_hat = [1, 1, 1, 0, 0, 0]
h = metrics.homogeneity_score(y, y_hat)
c = metrics.completeness_score(y, y_hat)
v = metrics.v_measure_score(y, y_hat)
print(u'同一性(Homogeneity):', h)
print(u'完整性(Completeness):', c)
print(u'V-Measure:', v)
"""
y = [0, 0, 1, 1]
y_hat = [0, 1, 0, 1]
ari = metrics.adjusted_rand_score(y, y_hat)
print(ari)
y = [0, 0, 0, 1, 1, 1]
y_hat = [0, 0, 1, 1, 2, 2]
ari = metrics.adjusted_rand_score(y, y_hat)
print(ari)
"""
二、ARI评估
已知类别的情况下,看看聚类算法是否对这样的数据集有效
评判聚类结果Y和实际结果X相关性
n11是共同的,a1是X1簇中的样本数量,b1是Y1簇中样本个数
Rand Index Adjusted Rand index(调整兰德指数)(ARI):表示数据集中可以组成的对数,RI取值范围为[0,1],值越大意味着聚类结果与真实情况越吻合
ARI取值范围为[−1,1],值越大意味着聚类结果与真实情况越吻合。从广义的角度来讲,ARI衡量的是两个数据分布的吻合程度
任意取两个是属于某一个类别的概率一样
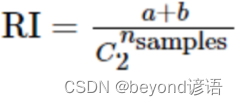
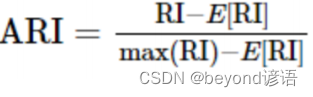

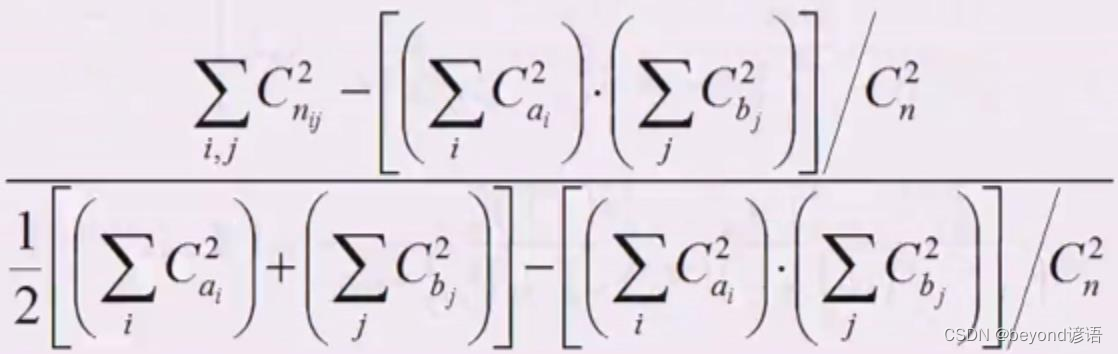
三、AMI
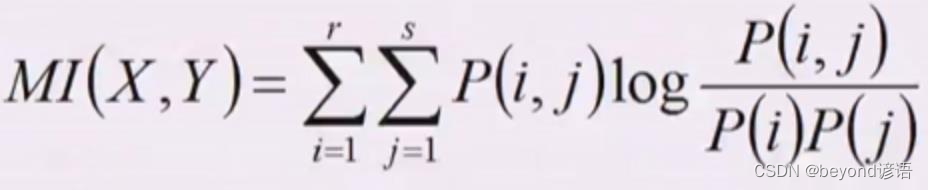
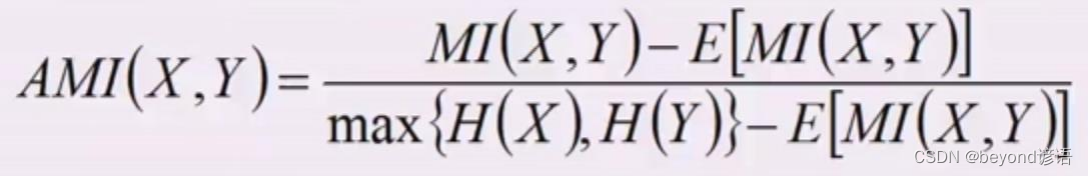
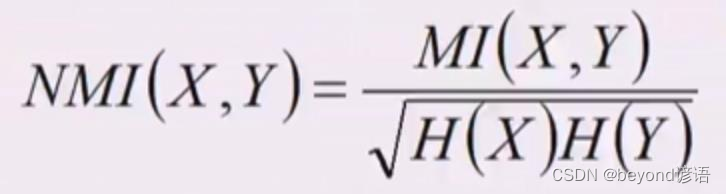
四、轮廓系数
计算同簇内每一个样本到同簇内样本的平均距离,可以度量这个样本和其他同簇样本的相似性
计算一个簇内每一个样本到不同簇内所有样本的距离,不同簇的那些样本距离求平均,然后求最小的那个距离,是不相似性
第一个值很小,第二个值很大,那这个就是簇内很典型性的样本
如果相反,按道理应该属于另外一个簇了
轮廓系数是要照顾到每一个样本的
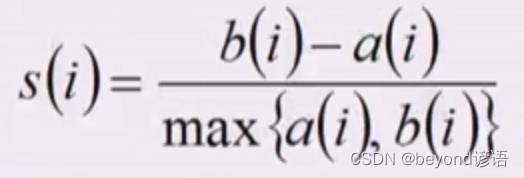
Si接近1说明样本i聚类合理,Si接近-1说明样本更应该分到其他簇
Si接近0说明在簇分界上