主成分分析PCA——人脸识别MATLAB实现
我在学习PCA降维以压缩数据的时候发现可以通过它来实现人脸识别,查阅了大量资料,除了矩阵求导具体推导没有太懂之外,弄懂了所由原理和技术细节,并在ORL_92x112人脸数据集实现了人脸识别。
这篇博客是相当于我的工程说明书,没有涉及PCA的具体原理,时间太紧1551,原理详解可能会在日后给出,fighting!
可以说的一点是PCA人脸识别关键是求出样本集的特征空间,在特征空间上相近的点可以认为是一类点。PS:我会在正文给上我写的一个算法原理流程图吧~
目录
3.主成分分析,即降维,dimension_reduction()函数
5.Knn最小邻近分类算法-人脸识别,find_person()函数
一、实现框架
1.算法流程图

2.go.m文件的内容,是我项目的大致框架
%default value
start=1;%读入开始位置
number=7;%每个人前7张照片作为样本集
testnum=3;%每个人的后3张照片作为测试集
rate=0.90;%贡献率为0.9
show=1;%允许算法过程中输出图像
condense=2;%新图像的一个像素用原图像的2*2的像素块的平均值代替
person=40;%读入40个人的图片
第一步:数据预处理
[trainset]=read(start,number,show,condense,person);
%trainset是压缩后的灰度double型的矩阵,行为样本(一行一个样本),列为样本的特征
%即像素,trainset即是用一个矩阵存储了整个样本集(这里把一个图片的所有像素展开成一
%行),所以可以用一个矩阵存储整个样本集
第二步:数据规范化
[trainset_normal,mu,sigma]=normalization(trainset,show,condense);
%trainset_normal是trainset去中心化并处以标准差即规范化的样本集
%mu是均值行向量,即每个像素在所有样本的平均值,mu的第几列就对应图像的第几个像素
%sigma是标准差行向量,即每个像素在所有样本的标准差,列的含义与mu同理
第三步:主成分分析,即降维
[U,S,V,k]=dimension_reduction(trainset_normal,rate);
%Cov是规范化的样本集trainset_normal产生的协方差矩阵;
%U是Cov的特征向量矩阵,其特征向量从左到右按特征值从大到小排列;
%S为Cov的特征值的对角阵,从左到右其特征值从大到小;
%V没有用到(奇异值分解产生的的另一个矩阵);
%k为满足贡献率rate值的最小特征值数,也即去U中前k个特征向量构成矩阵Uk,代表该
%样本集训练出来的特征空间,即人脸图像降维所降至的空间
[Uk,Z,test_norm,testset]=get_z(U,k,mu,sigma,show,start,number,testnum,condense,person);
%Uk即是降维矩阵(特征向量矩阵)U的前k维(前k列)构成的矩阵
%Z测试集降维后在特征空间的坐标矩阵,行为一个测试实例,列为特征空间对应基上的坐标
%test_norm即测试集矩阵testset规范化后的矩阵
%testset即读入测试集压缩后的灰度double型的矩阵,行为测试实例,列为像素(特征)
第四步:重构
[train_re,test_re]=reconstruction(Z,Uk,trainset_normal,mu,sigma,start,number,testnum,condense,person);
%train_re,test_re这两个矩阵是重构后在原空间上的坐标,即重构的图形,没有用到
第五步:在特征空间利用knn最邻近分类算法进行人脸识别
[result,right,accuracy_rate]=find_person(Z,Uk,trainset_normal,number,testnum,person,trainset,testset,condense);
%result是列向量,存储识别结果。在本例中,共有40人,每人10照片,每个人前7张照片
%作为样本集,后3张照片作为测试集。故样本集有280行,测试集有120行。这里i表示第
%i行测试集,result(i)存的是与第i行测试集在特征空间最近的第result(i)行样本
%集。如result(1)=3.即算法得出第1张测试集照片与第3张样本集图片在特征空间上最
%近,从而认为他们是一个人。
%right是列向量,存储0或1.right(i)=1代表测试集第i张照片识别正确。
%accuracy_rate是算法得到的人脸识别正确率。
二、实现流程
1.预处理,read()函数
read()函数可以从每个人10张照片的start处读入m张图片并存在压缩后的灰度double型的矩阵trainset,并且可以选择是否显示这些图片
function[trainset]=read(start,m,show,condense,person)
%read images from file,m is the number of training images
%strat is the initial position
%m is number of samples
%show =1 enable show
%condense=2,4,8 etc. convey that the rate of picture condense
k=condense;
trainset = zeros(person*m, 112 * 92/k^2); % image size is : 112*92
for j = 1:person
for i = start : start+m-1
fprintf('in reading:%d\n',10*(j-1)+i);
name=strcat('C:\ORL_92x112\s',int2str(j),'_',int2str(i),'.bmp');
img = imread(name);
%gray = rgb2gray(img);
gray = double(img);
gray64 = imresize(gray,[112/k,92/k]);
if show==1
figure(10*(j-1)+i);
subplot(2,2,1);
imshow(img);
subplot(2,2,2);
imshow(uint8(gray));
subplot(2,2,3);
imshow(uint8(gray64));
end
trainset(m*(j-1)+i-start+1, :) = gray64(:);
%every row is a gray picture
end
end
2.数据规范化,normalization()函数
normalization()函数实现了trainset_normal是trainset去中心化并处以标准差即规范化的样本集,并得到行向量mu和sigma
function[trainset_normal,mu,sigma]=normalization(trainset,show,condense)
fprintf('in normalization\n');
k=condense;
mu=mean(trainset);
sigma=std(trainset);
trainset_normal=bsxfun(@minus,trainset,mu);
trainset_normal=bsxfun(@rdivide,trainset_normal,sigma);
%sigma is std. bsxfun is matlab inline fun. trainset-mu.
%show mean picture
if show==1
figure(521)
imwrite(uint8(reshape(mu, 112/k, 92/k)), 'mean_picture.jpg');
imshow('mean_picture.jpg');
end
3.主成分分析,即降维,dimension_reduction()函数
3.1dimension_reduction()函数
主要是得到了特征向量矩阵U和特征向量S
function[U,S,V,k]=dimension_reduction(trainset_normal,rate)
fprintf('in dimension_reduction\n');
X = trainset_normal; % just for convience
[m, n] = size(X);
% U = zeros(n);
% S = zeros(n);
Cov = 1 / m*X'*X;
[U, S, V] = svd(Cov);
fprintf('compute cov done.\n');
k=choose_k(S,rate);
fprintf('k is %d\n',k);
3.2choose_k()函数
则是根据贡献率rate选出前k个贡献率最大的特征值,返回k
function[k]=choose_k(S,rate)
fprintf('in choosing k\n');
[m,n]=size(S);
k=1;
total=sum(sum(S));
current=S(1,1);
for i=1:n-1
p=current/total;
if p>rate
break
else
current=current+S(i+1,i+1);
k=k+1;
end
end
3.3get_z()函数
读入测试集testset,规范化得test_norm,并由Uk计算其在特征空间的坐标Z
function[Uk,Z,test_norm,testset]=get_z(U,k,mu,sigma,show,start,number,testnum,condense,person)
fprintf('in test:getting Z\n');
testset=read(start+number,testnum,show,condense,person);
% test set need to do normalization
test_norm=bsxfun(@minus,testset,mu);
test_norm=bsxfun(@rdivide,test_norm,sigma);
% reduction
Uk = U(:, 1:k);
Z = test_norm * Uk;
fprintf('reduce done.\n');
4.重构,reconstruction()函数
reconstruction()函数分别将特征空间中的样本集合测试集通过Uk还原回来并且显示
function[train_re,test_re]=reconstruction(Z,Uk,trainset_normal,mu,sigma,start,number,testnum,condense,person)
% reconstruction
trainset_re = trainset_normal * Uk; %sample reduction
trainset_re = trainset_re * Uk'; %sample reconstruction
fprintf('show reconstructed %d training pictures\n',number*person);
for j = 1:person
for i = start:start+number-1
fprintf('show reconstructed training pictures:%d\n',10*(j-1)+i);
train = trainset_re(number*(j-1)+i-start+1, :);
train = train .* sigma;
train = train + mu;
train_re = uint8(reshape(train, 112/condense, 92/condense));
figure(10*(j-1)+i-start+1);
subplot(2,2,4);
imshow(train_re);
end
end
Xp = Z * Uk';%test reconstruction
% show reconstructed picture
fprintf('show reconstructed %d test pictures\n',testnum*person);
for j = 1:person
for i = 1:testnum
fprintf('show reconstructed test pictures:%d\n',10*(j-1)+start+number+i-1);
pic = Xp(testnum*(j-1)+i-start+1, :) .*sigma;
pic = pic + mu;
test_re = uint8(reshape((pic), 112/condense, 92/condense));
figure(10*(j-1)+start+number+i-1);
subplot(2,2,4);
imshow(test_re);
end
end
fprintf('end reconstruct\n');
5.Knn最小邻近分类算法-人脸识别,find_person()函数
find_person()函数本质上就是先选取测试集一张图片,然后和所以样本集图片在特征空间上算距离,取距离最小的样本,认为该测试图片和该样本图片来源于同一个人,即1nn算法。
function[result,right,accuracy_rate]=find_person(Z,Uk,trainset_normal,number,testnum,person,trainset,testset,condense)
train_coordinate=trainset_normal * Uk;
%样本集在特征空间的坐标
test_coordinate=Z;
%测试集在特征空间的坐标
result=zeros(person*testnum,1);
%40*3个测试集实例,存放结果的列向量result
for i=1:person*testnum
%遍历40*3个测试集实例
distance=ones(1,person*number)*256;
%256是初始最远距离(最大像素)
for j=1:person*number
%遍历40*7个测试集实例
temp=train_coordinate(j,:)-test_coordinate(i,:);
temp=temp.*temp;
distance(j)=sum(temp);
%计算特征空间上两者的欧氏距离
end
[num,result(i)]=min(distance);
%找到距离最小者的样本集位置,存入result(i)中
end
right=zeros(person*testnum,1);
%40*3个测试集实例,存放0、1的列向量right
for i=1:person*testnum
if floor((i-1)/testnum)==floor((result(i)-1)/number)
%注意这里向下取整之前要减1
right(i)=1;
end
figure(400+i);
strans=strcat('right=',int2str(right(i)));
two=strcat('pitture',int2str(10*floor((i-1)/testnum)+number+mod(i,testnum)),'and
picture');
%这里坐标的转换要推导一下,原图片编号是第一个人10张图片从1到10,然后是第二个人的编号,以此类推。如395就是第39个人的第五张照片。样本集有280张照片,每7张照照片是一个人的;测试集有120张照片,每3张是一个人的。
two_person=strcat(two,int2str(10*floor((result(i)-1)/number)+mod(i,number)));
subplot(1,2,1);
imshow(uint8(reshape(testset(i,:),112/condense,92/condense)));
title(two_person);
subplot(1,2,2);
imshow(uint8(reshape(trainset(result(i),:),112/condense,92/condense)));
title(strans);
end
accuracy_rate=sum(right)/(person*testnum);
fprintf('accuracy rate is :%d\n',accuracy_rate);
三、结果分析
1.平均脸
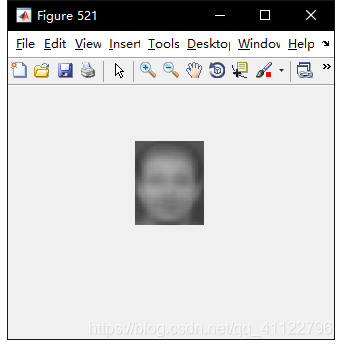
2.重构结果
样本集重构结果(右下角)

测试集重构结果(右下角)

3.识别结果
准确率为

识别数为120

正确115,知有五张错误
错误位置为

正确结果举例:

错误结果为:




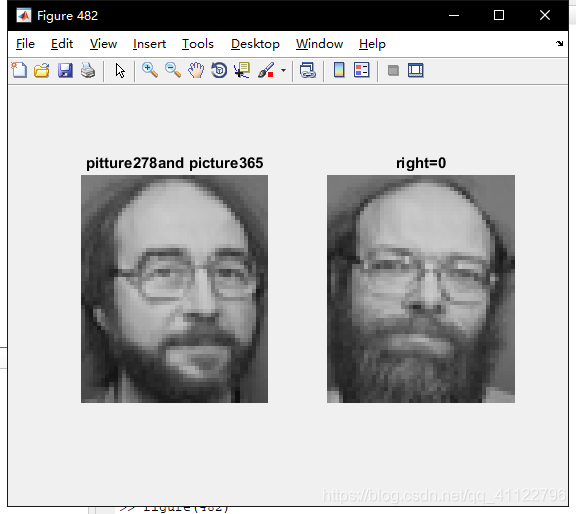
有些照片是不是很像呢?提高准确率可以通过
1.增加训练集
2.增加贡献率(现在是90%)
3.从1nn算法变为knn算法,选取合适的k
4.时间耗费

注意:程序总运行时间虽然只有164小于其他程序运行时间之和,这个现象是合理的。因为我笔记本处理器是多核多线程的,不同程序之间可以并发运行。
五、源代码
function[trainset]=read(start,m,show,condense,person)
%read images from file,m is the number of training images
%strat is the initial position
%m is number of samples
%show =1 enable show
%condense=2,4,8 etc. convey that the rate of picture condense
k=condense;
trainset = zeros(person*m, 112 * 92/k^2); % image size is : 112*92
for j = 1:person
for i = start : start+m-1
fprintf('in reading:%d\n',10*(j-1)+i);
name=strcat('C:\ORL_92x112\s',int2str(j),'_',int2str(i),'.bmp');
img = imread(name);
%gray = rgb2gray(img);
gray = double(img);
gray64 = imresize(gray,[112/k,92/k]);
if show==1
figure(10*(j-1)+i);
subplot(2,2,1);
imshow(img);
subplot(2,2,2);
imshow(uint8(gray));
subplot(2,2,3);
imshow(uint8(gray64));
end
trainset(m*(j-1)+i-start+1, :) = gray64(:);
%every row is a gray picture
end
end
function[trainset_normal,mu,sigma]=normalization(trainset,show,condense)
fprintf('in normalization\n');
k=condense;
%
mu=mean(trainset);
sigma=std(trainset);
trainset_normal=bsxfun(@minus,trainset,mu);
trainset_normal=bsxfun(@rdivide,trainset_normal,sigma);
%sigma is std. bsxfun is matlab inline fun. trainset-mu.
%show mean picture
if show==1
figure(521)
imwrite(uint8(reshape(mu, 112/k, 92/k)), 'mean_picture.jpg');
imshow('mean_picture.jpg');
end
function[U,S,V,k]=dimension_reduction(trainset_normal,rate)
fprintf('in dimension_reduction\n');
X = trainset_normal; % just for convience
[m, n] = size(X);
% U = zeros(n);
% S = zeros(n);
Cov = 1 / m*X'*X;
[U, S, V] = svd(Cov);
fprintf('compute cov done.\n');
k=choose_k(S,rate);
fprintf('k is %d\n',k);
function[k]=choose_k(S,rate)
fprintf('in choosing k\n');
[m,n]=size(S);
k=1;
total=sum(sum(S));
current=S(1,1);
for i=1:n-1
p=current/total;
if p>rate
break
else
current=current+S(i+1,i+1);
k=k+1;
end
end
function[Uk,Z,test_norm,testset]=get_z(U,k,mu,sigma,show,start,number,testnum,condense,person)
fprintf('in test:getting Z\n');
testset=read(start+number,testnum,show,condense,person);
% test set need to do normalization
test_norm=bsxfun(@minus,testset,mu);
test_norm=bsxfun(@rdivide,test_norm,sigma);
% reduction
Uk = U(:, 1:k);
Z = test_norm * Uk;
fprintf('reduce done.\n');
function[train_re,test_re]=reconstruction(Z,Uk,trainset_normal,mu,sigma,start,number,testnum,condense,person)
% reconstruction
trainset_re = trainset_normal * Uk; %sample reduction
trainset_re = trainset_re * Uk'; %sample reconstruction
fprintf('show reconstructed %d training pictures\n',number*person);
for j = 1:person
for i = start:start+number-1
fprintf('show reconstructed training pictures:%d\n',10*(j-1)+i);
train = trainset_re(number*(j-1)+i-start+1, :);
train = train .* sigma;
train = train + mu;
train_re = uint8(reshape(train, 112/condense, 92/condense));
figure(10*(j-1)+i-start+1);
subplot(2,2,4);
imshow(train_re);
end
end
Xp = Z * Uk';%test reconstruction
% show reconstructed picture
fprintf('show reconstructed %d test pictures\n',testnum*person);
for j = 1:person
for i = 1:testnum
fprintf('show reconstructed test pictures:%d\n',10*(j-1)+start+number+i-1);
pic = Xp(testnum*(j-1)+i-start+1, :) .*sigma;
pic = pic + mu;
test_re = uint8(reshape((pic), 112/condense, 92/condense));
figure(10*(j-1)+start+number+i-1);
subplot(2,2,4);
imshow(test_re);
end
end
fprintf('end reconstruct\n');
%
function[result,right,accuracy_rate]=find_person(Z,Uk,trainset_normal,number,testnum,person,trainset,testset,condense)
train_coordinate=trainset_normal * Uk;
%样本集在特征空间的坐标
test_coordinate=Z;
%测试集在特征空间的坐标
result=zeros(person*testnum,1);
%40*3个测试集实例,存放结果的列向量result
for i=1:person*testnum
%遍历40*3个测试集实例
distance=ones(1,person*number)*256;
%256是初始最远距离(最大像素)
for j=1:person*number
%遍历40*7个测试集实例
temp=train_coordinate(j,:)-test_coordinate(i,:);
temp=temp.*temp;
distance(j)=sum(temp);
%计算特征空间上两者的欧氏距离
end
[num,result(i)]=min(distance);
%找到距离最小者的样本集位置,存入result(i)中
end
right=zeros(person*testnum,1);
%40*3个测试集实例,存放0、1的列向量right
for i=1:person*testnum
if floor((i-1)/testnum)==floor((result(i)-1)/number)
%注意这里向下取整之前要减1
right(i)=1;
end
figure(400+i);
strans=strcat('right=',int2str(right(i)));
two=strcat('pitture',int2str(10*floor((i-1)/testnum)+number+mod(i,testnum)),'and picture');
%这里坐标的转换要推导一下,原图片编号是第一个人10张图片从1到10,然后是第二个人的编号,以此类推。如395就是第39个人的第五张照片。样本集有280张照片,每7张照照片是一个人的;测试集有120张照片,每3张是一个人的。
two_person=strcat(two,int2str(10*floor((result(i)-1)/number)+mod(i,number)));
subplot(1,2,1);
imshow(uint8(reshape(testset(i,:),112/condense,92/condense)));
title(two_person);
subplot(1,2,2);
imshow(uint8(reshape(trainset(result(i),:),112/condense,92/condense)));
title(strans);
end
accuracy_rate=sum(right)/(person*testnum);
fprintf('accuracy rate is :%d\n',accuracy_rate);
go,m文件存的是运行算法的命令行
%default value
start=1;%读入开始位置
number=7;%每个人前7张照片作为样本集
testnum=3;%每个人的后3张照片作为测试集
rate=0.90;%贡献率为0.9
show=1;%允许算法过程中输出图像
condense=2;%新图像的一个像素用原图像的2*2的像素块的平均值代替
person=40;%读入40个人的图片
%第一步:数据预处理
[trainset]=read(start,number,show,condense,person);
%trainset是压缩后的灰度double型的矩阵,行为样本(一行一个样本),列为样本的特征
%即像素,trainset即是用一个矩阵存储了整个样本集(这里把一个图片的所有像素展开成一
%行),所以可以用一个矩阵存储整个样本集
%第二步:数据规范化
[trainset_normal,mu,sigma]=normalization(trainset,show,condense);
%trainset_normal是trainset去中心化并处以标准差即规范化的样本集
%mu是均值行向量,即每个像素在所有样本的平均值,mu的第几列就对应图像的第几个像素
%sigma是标准差行向量,即每个像素在所有样本的标准差,列的含义与mu同理
%第三步:主成分分析,即降维
[U,S,V,k]=dimension_reduction(trainset_normal,rate);
%Cov是规范化的样本集trainset_normal产生的协方差矩阵;
%U是Cov的特征向量矩阵,其特征向量从左到右按特征值从大到小排列;
%S为Cov的特征值的对角阵,从左到右其特征值从大到小;
%V没有用到(奇异值分解产生的的另一个矩阵);
%k为满足贡献率rate值的最小特征值数,也即去U中前k个特征向量构成矩阵Uk,代表该
%样本集训练出来的特征空间,即人脸图像降维所降至的空间
[Uk,Z,test_norm,testset]=get_z(U,k,mu,sigma,show,start,number,testnum,condense,person);
%Uk即是降维矩阵(特征向量矩阵)U的前k维(前k列)构成的矩阵
%Z测试集降维后在特征空间的坐标矩阵,行为一个测试实例,列为特征空间对应基上的坐标
%test_norm即测试集矩阵testset规范化后的矩阵
%testset即读入测试集压缩后的灰度double型的矩阵,行为测试实例,列为像素(特征)
%第四步:重构
[train_re,test_re]=reconstruction(Z,Uk,trainset_normal,mu,sigma,start,number,testnum,condense,person);
%train_re,test_re这两个矩阵是重构后在原空间上的坐标,即重构的图形,没有用到
%第五步:在特征空间利用knn最邻近分类算法进行人脸识别
[result,right,accuracy_rate]=find_person(Z,Uk,trainset_normal,number,testnum,person,trainset,testset,condense);
%result是列向量,存储识别结果。在本例中,共有40人,每人10照片,每个人前7张照片
%作为样本集,后3张照片作为测试集。故样本集有280行,测试集有120行。这里i表示第
%i行测试集,result(i)存的是与第i行测试集在特征空间最近的第result(i)行样本
%集。如result(1)=3.即算法得出第1张测试集照片与第3张样本集图片在特征空间上最
%近,从而认为他们是一个人。
%right是列向量,存储0或1.right(i)=1代表测试集第i张照片识别正确。
%accuracy_rate是算法得到的人脸识别正确率。
