译者注:
本文的目的是让读者能够通过必要的数学证明来详细了解主成分分析。
在现实世界的数据分析任务中,我们面对的数据通常较为复杂,例如多维数据。我们绘制数据并希望从中找到各种模式,或者使用数据来训练机器学习模型。一种看待维度(dimensions )的方法是假设你有一个数据点
x
x
x 译者注:这里的视图应该是和三视图中的视图是一个概念 )的基础(basis of view ),就像从横轴或者纵轴观察数据时的位置。
随着数据维度的增长,可视化数据的难度和数据计算量也随之增长。所以,如何减少数据维度?
break1
首先来理解一些术语:
方差(Variance ) :它是数据离散程度的一个度量方法。数学上来说,就是数据与其平均值的误差平方和的平均。我们使用如下的公式来计算方差
v
a
r
(
x
)
var(x)
v a r ( x )
v
a
r
(
x
)
=
Σ
(
x
i
−
x
ˉ
)
2
N
var(x) = \frac{\Sigma(x_i-\bar{x})^2}{N}
v a r ( x ) = N Σ ( x i − x ˉ ) 2
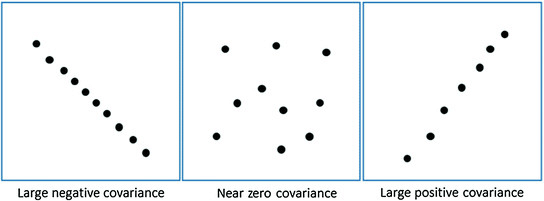
协方差(Covariance) :它衡量两组有序数据中相应元素在同一方向上移动的程度(译者注:或者通俗的来讲,就是表示两个变量的变化趋势 )。两个变量
x
x
x
y
y
y
c
o
v
(
x
,
y
)
cov(x,y)
c o v ( x , y )
c
o
v
(
x
,
y
)
=
Σ
(
x
i
−
x
ˉ
)
(
y
i
−
y
ˉ
)
N
cov(x,y) = \frac{\Sigma(x_i-\bar{x})(y_i-\bar{y})}{N}
c o v ( x , y ) = N Σ ( x i − x ˉ ) ( y i − y ˉ )
其中,
x
i
x_i
x i
x
x
x
i
i
i 译者注:注意和 Python 中的多维列表中的「维」做区分,数学上来说,这里的
x
x
x ),
x
ˉ
\bar{x}
x ˉ
y
ˉ
\bar{y}
y ˉ
协方差的一种理解方式是两个数据集是如何相关关联的。
正协方差意味着
X
X
X
Y
Y
Y
X
X
X
Y
Y
Y
X
X
X
Y
Y
Y
Continue break1
现在让我们来考虑一下数据分析的需求。
由于我们想要找到数据中的模式,所以我们希望数据分布在每个维度上。同时,我们也希望各个维度之间是独立的。这样的话如果数据在某些
n
n
n
n
n
n
n
n
n
那么,主成分分析(PCA)是干什么的?
PCA 试图寻找一组新的维度(或者叫一组基础视图),使得所有维度都是正交的(所以线性无关),并根据数据在他们上面的方差进行排序。这就意味着越重要的成分越会排在前面(越重要 = 更大方差/数据分布更广)
PCA 的步骤如下:
计算数据点的协方差矩阵
X
X
X
计算特征向量和相应的特征值
根据特征值,降序排列对应的特征向量
选择前
k
k
k
k
k
k
将原始的
n
n
n
k
k
k
为了理解 PCA 的详细计算过程,你需要对特征向量(eigen vectors )和特征值(eigen values )有所了解,你可以参考这个对特征值和特征向量的直观解释 。
确保在继续阅读之前你已经理解了特征向量和特征值。
[
C
o
v
a
r
i
a
n
c
e
m
a
t
r
i
x
]
⋅
[
E
i
g
e
n
v
e
c
t
o
r
]
=
[
e
i
g
e
n
v
a
l
u
e
]
⋅
[
E
i
g
e
n
v
e
c
t
o
r
]
[Covariance matrix] \cdot [Eigenvector] = [eigenvalue] \cdot [Eigenvector]
[ C o v a r i a n c e m a t r i x ] ⋅ [ E i g e n v e c t o r ] = [ e i g e n v a l u e ] ⋅ [ E i g e n v e c t o r ]
假设我们已经了解了方差和协方差,然后我们来看下协方差矩阵是什么样的:
[
V
a
C
a
,
b
C
a
,
c
C
a
,
d
C
a
,
e
C
a
,
b
V
b
C
b
,
c
C
b
,
d
C
b
,
e
C
a
,
c
C
b
,
c
V
c
C
c
,
d
C
c
,
e
C
a
,
d
C
b
,
d
C
c
,
d
V
d
C
d
,
e
C
a
,
e
C
b
,
e
C
c
,
e
C
d
,
e
V
e
]
\begin{bmatrix} V_a & C_{a,b} & C_{a,c} & C_{a,d} & C_{a,e} \\ C_{a,b} & V_b & C_{b,c} & C_{b,d} & C_{b,e} \\ C_{a,c} & C_{b,c} & V_c & C_{c,d} & C_{c,e} \\ C_{a,d} & C_{b,d} & C_{c,d} & V_d & C_{d,e} \\ C_{a,e} & C_{b,e} & C_{c,e} & C_{d,e} & V_e \\ \end{bmatrix}
⎣ ⎢ ⎢ ⎢ ⎢ ⎡ V a C a , b C a , c C a , d C a , e C a , b V b C b , c C b , d C b , e C a , c C b , c V c C c , d C c , e C a , d C b , d C c , d V d C d , e C a , e C b , e C c , e C d , e V e ⎦ ⎥ ⎥ ⎥ ⎥ ⎤
上面的矩阵即是一个 5 维数据集的协方差矩阵(译者注:原文说是 4 维,我觉得有可能笔误,我这里更正为 5 维 ),a、b、c、d 和 e。其中
V
a
V_a
V a
C
a
,
b
C_{a,b}
C a , b
如果我们有一个
m
×
n
m \times n
m × n
n
n
n
m
m
m 译者注:这是原文的说法,暂且将数据点理解为样本,我个人觉得,一般是以行表示样本,列表示特征,而这里的说法正好相反 ),然后协方差矩阵可以如下计算:
C
x
=
1
n
−
1
(
X
−
X
ˉ
)
(
X
−
X
ˉ
)
T
C_x = \frac{1}{n-1}(X-\bar{X})(X-\bar{X})^T
C x = n − 1 1 ( X − X ˉ ) ( X − X ˉ ) T
其中
X
T
X^T
X T
X
X
X
需要注意的是,协方差矩阵包括:
每个维度上的方差作为主对角线元素
每两个维度之间的协方差作为非对角线元素
而且,协方差矩阵是对称的。正如我们之前说的那样,我们希望数据分布的更广,即它应该在某个维度上具有高方差。我们也想要去除相关性高的维度,即维度之间的协方差应该为 0(他们应该是线性无关的)。因此,我们的协方差矩阵应该具有:
我们称之为对角阵(diagonal matrix )。
所以我们必须变换原始数据点,才能使得他们的协方差矩阵为对角阵。把一个矩阵变换为对角阵的过程称为对角化 (diagonalization )。
在进行 PCA 之前记得归一化(normalize )你的数据,因为如果我们使用不同尺度的数据(即这里的特征),我们会得到误导性的成分。如果特征尺度不同,那么我们也可以简单地使用相关性矩阵而不是协方差矩阵。为了简化这篇文章,我假设我们已经归一化了数据。
让我们来定义一下 PCA 的目标:
找到可以无损地表示原始数据的线性无关的维度(或者基础视图)
这些新找到的维度应该能够让我们预测或者重建原始维度,同时应该最小化重建或者投影误差
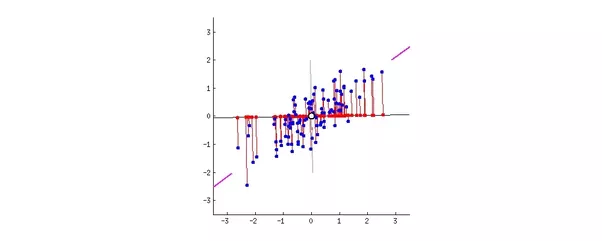
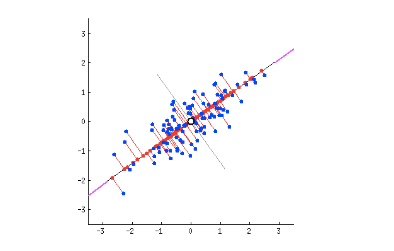
让我们来理解一下我所说的投影误差。假设我们要把一个 2 维数据变换成 1 维。所以我们就需要找到一条直线然后把数据点投影到上面(一条直线就是 1 维的)。我们可以找到很多条直线,让我们来看下其中两种:
假设洋红色(magenta )线就是我们的新维度。
如果你看到了红色线(连接蓝色点的投影和洋红色线),那么这每个数据点到直线的垂直距离就是投影误差。所有数据点的误差的和就是总投影误差(译者注:这里每个数据点的误差可以是绝对值形式或者平方误差形式 )。
我们的新数据点就是原始蓝色数据点的投影(红点)。正如我们所看到的,我们将 2 维数据投影到 1 维空间,从而将他们变换成 1 维数据。那条洋红色的线被称为主轴 (principal axis )。由于我们是投影到一个维度,所有我们只有一个主轴。
很明显,我们选择的第二条直线就比较好,因为
投影误差比第一条直线小
与第一种情况相比,投影后的数据点分布更广,即方差更大
上面提到的两点是有联系的,即如果我们最小化重建误差,那么方差也会增大。
为什么?
证明:https://stats.stackexchange.com/questions/32174/pca-objective-function-what-is-the-connection-between-maximizing-variance-and-m/136072#136072
到现在为止我们做的有:
我们已经计算了原始数据矩阵
X
X
X
现在我们要变换原始数据点,使得变换后的数据协方差矩阵为对角阵。那么如何做呢?
Y
=
P
X
Y=PX
Y = P X
其中,
X
X
X
Y
Y
Y
为了简便,我们忽略平均项并且假设数据已经中心化(be centered ),即
X
=
(
X
−
X
ˉ
)
X = (X - \bar{X})
X = ( X − X ˉ )
C
x
=
1
n
X
X
T
C
y
=
1
n
Y
Y
T
=
1
n
(
P
X
)
(
P
X
)
T
=
1
n
P
X
X
T
P
T
=
P
(
1
n
X
X
T
)
P
T
=
P
C
x
P
T
\begin{aligned} C_x &= \frac{1}{n}XX^T \\ C_y &= \frac{1}{n}YY^T \\ &= \frac{1}{n}(PX)(PX)^T \\ &= \frac{1}{n}PXX^TP^T \\ &= P(\frac{1}{n}XX^T)P^T \\ &= PC_xP^T \end{aligned}
C x C y = n 1 X X T = n 1 Y Y T = n 1 ( P X ) ( P X ) T = n 1 P X X T P T = P ( n 1 X X T ) P T = P C x P T
这就是其中的原理:如果我们能找到
C
x
C_x
C x
P
P
P
P
P
P
X
X
X
Y
Y
Y
C
y
C_y
C y
Y
Y
Y
现在,如果我们想要将数据变换为
k
k
k
C
x
C_x
C x
k
k
k
P
P
P
如果我们有
m
m
m
n
n
n
X
:
m
×
n
X:m \times n
X : m × n
P
:
k
×
m
P:k \times m
P : k × m
Y
=
P
X
:
(
k
×
m
)
(
m
×
n
)
=
(
k
×
n
)
Y=PX:(k \times m)(m \times n)=(k \times n)
Y = P X : ( k × m ) ( m × n ) = ( k × n )
所以,我们变换后的矩阵将是
n
n
n
k
k
k
但是为什么这个原理有效呢?
证明:
首先让我们来看一些定理:
定理 1:正交矩阵的逆是其转置,为什么?
令
A
A
A
m
×
n
m \times n
m × n 译者注:根据定义 ,正交矩阵一定是方阵,此处应
m
=
n
m=n
m = n ),
a
i
a_i
a i
i
i
i
A
T
A
A^TA
A T A
i
j
ij
i j
(
A
T
A
)
i
j
=
a
i
T
a
j
=
{
1
,
if
i
=
j
0
,
otherwise
\begin{aligned} (A^TA)_{ij} &= a_i^Ta_j \\\\ &= \begin{cases} 1, & \text{if $i$ = $j$} \\\\ 0, & \text{otherwise} \end{cases} \end{aligned}
( A T A ) i j = a i T a j = ⎩ ⎪ ⎨ ⎪ ⎧ 1 , 0 , if i = j otherwise
即
A
T
A
=
I
A^TA = I
A T A = I
A
−
1
=
A
T
A^{-1} = A^T
A − 1 = A T
定理 2:
令
A
A
A
λ
1
,
λ
2
,
⋯
 
,
λ
k
\lambda_1,\lambda_2,\cdots,\lambda_k
λ 1 , λ 2 , ⋯ , λ k
A
A
A
u
i
∈
R
n
u_i \in R^n
u i ∈ R n
1
≤
i
≤
k
1 \leq i \leq k
1 ≤ i ≤ k
u
1
,
u
2
,
⋯
 
,
u
k
{u_1,u_2,\cdots,u_k}
u 1 , u 2 , ⋯ , u k orthonormal set )。
证明:
对于
i
≠
j
i \neq j
i ̸ = j
1
≤
i
,
j
≤
k
1 \leq i,j \leq k
1 ≤ i , j ≤ k
A
T
=
A
A^T = A
A T = A
λ
i
⟨
u
i
,
u
j
⟩
=
⟨
λ
i
u
i
,
u
j
⟩
=
⟨
A
u
i
,
u
j
⟩
=
⟨
u
i
,
A
T
u
j
⟩
=
⟨
u
i
,
A
u
j
⟩
=
λ
j
⟨
u
i
,
u
j
⟩
\begin{aligned} \lambda_i \langle u_i,u_j \rangle &= \langle \lambda_iu_i,u_j \rangle \\\\ &= \langle Au_i,u_j \rangle \\\\ &= \langle u_i,A^Tu_j \rangle \\\\ &= \langle u_i,Au_j \rangle \\\\ &= \lambda_j \langle u_i,u_j \rangle \\\\ \end{aligned}
λ i ⟨ u i , u j ⟩ = ⟨ λ i u i , u j ⟩ = ⟨ A u i , u j ⟩ = ⟨ u i , A T u j ⟩ = ⟨ u i , A u j ⟩ = λ j ⟨ u i , u j ⟩
由于
i
≠
j
i \neq j
i ̸ = j
λ
i
≠
λ
j
\lambda_i \neq \lambda_j
λ i ̸ = λ j
⟨
u
i
,
u
j
⟩
=
0
\langle u_i, u_j \rangle = 0
⟨ u i , u j ⟩ = 0
定理 3:
令
A
A
A
n
×
n
n \times n
n × n
P
P
P
P
−
1
A
P
=
D
P^{-1}AP=D
P − 1 A P = D
D
D
D
A
A
A
证明:
令
A
A
A
λ
1
,
λ
2
,
⋯
 
,
λ
n
\lambda_1,\lambda_2,\cdots,\lambda_n
λ 1 , λ 2 , ⋯ , λ n
u
i
∈
R
n
u_i \in R^n
u i ∈ R n
∣
u
i
∣
=
1
|u_i| = 1
∣ u i ∣ = 1
A
u
i
=
λ
i
u
i
Au_i=\lambda_iu_i
A u i = λ i u i
1
≤
i
≤
n
1 \leq i \leq n
1 ≤ i ≤ n
P
=
[
u
1
,
u
2
,
⋯
 
,
u
n
]
P=[u_1,u_2,\cdots,u_n]
P = [ u 1 , u 2 , ⋯ , u n ]
P
−
1
A
P
=
D
P^{-1}AP=D
P − 1 A P = D
(
u
1
,
u
2
,
⋯
 
,
u
n
)
(u_1,u_2,\cdots,u_n)
( u 1 , u 2 , ⋯ , u n )
P
P
P
有了这些定理,我们可以说:
一个对称阵可以通过其正交特征向量进行对角化。正交规范向量(orthonormal vectors )只是规范化的正交向量(orthogonal )。
译者注:关于 orthonormal vectors 和 orthogonal6.3 Orthogonal and orthonormal vectors - UCL ,我摘抄部分如下:
Definition. We say that 2 vectors are orthogonal if they are perpendicular to each other. i.e. the dot product of the two vectors is zero.
Definition. A set of vectors S is orthonormal if every vector in S has magnitude 1 and the set of vectors are mutually orthogonal.
C
y
=
P
C
x
P
T
=
P
(
E
D
E
)
P
T
=
P
(
P
T
D
P
)
P
T
=
(
P
P
T
)
D
(
P
P
T
)
=
(
P
P
−
1
)
D
(
P
P
−
1
)
C
Y
=
D
\begin{aligned} C_y &= PC_xP^T \\\\ &= P(E^DE)P^T \\\\ &= P(P^TDP)P^T \\\\ &= (PP^T)D(PP^T) \\\\ &= (PP^{-1})D(PP^{-1}) \\\\ C_Y &= D \end{aligned}
C y C Y = P C x P T = P ( E D E ) P T = P ( P T D P ) P T = ( P P T ) D ( P P T ) = ( P P − 1 ) D ( P P − 1 ) = D
很明显是
P
P
P
C
y
C_y
C y
P
P
P
C
y
C_y
C y
X 的主成分是
C
x
C_x
C x
C
y
C_y
C y
i
i
i
X
X
X
i
i
i
总结:
[
new data
]
k
×
n
=
[
top
k
eigenvectors
]
k
×
m
[
original data
]
m
×
n
[\text{new data}]_{k\times n} = [\text{top $k$ eigenvectors}]_{k \times m}[\text{original data}]_{m \times n}
[ new data ] k × n = [ top k eigenvectors ] k × m [ original data ] m × n
Note:PCA 是一种分析方法。你可以使用 SVD 做 PCA,或者使用特征分解(就像我们这里做的一样)做 PCA,或者使用其他方法做 PCA。SVD 只是另一种数值方法。所以不要混淆 PCA 和 SVD 这两个术语。但是有时我们会因为性能因素选择 SVD 而不是特征分解或者其他方法(这个不用关心),我们会在接下来的文章中探索 SVD。
译者注:关于 SVD,有兴趣的话可以参考我写的另一篇文章:奇异值分解 SVD 的数学解释 。