 《Python基础语法全体系》系列博文第二篇,本篇博文将详细深入讲解Python的字符串类型。包括转义字符、字符串格式化、序列相关方法及常用操作:大小写、删除空白、查找与替换、分割与连接等。整理自疯狂Python讲义。
《Python基础语法全体系》系列博文第二篇,本篇博文将详细深入讲解Python的字符串类型。包括转义字符、字符串格式化、序列相关方法及常用操作:大小写、删除空白、查找与替换、分割与连接等。整理自疯狂Python讲义。
转义字符
之前我们提到,在字符串中可以使用反斜线进行转义;如果字符串本身包含反斜线,则需要使用“\\”表示,“\\”就是转义字符。Python所支持的转义字符如下表所示:
| 转义字符 | 说明 |
|---|---|
| \b | 退格符 |
| \n | 换行符 |
| \r | 回车符 |
| \t | 制表符 |
| \’’ | 双引号 |
| \’ | 单引号 |
| \\ | 反斜线 |
s = 'Hello\nZYZMZM\nGood\nMorning'
print(s)
结果如下:
Hello
ZYZMZM
Good
Morning
也可以使用制表符进行分隔:
s2 = '博客名称\t\t粉丝\t\t阅读\t\t点赞'
s3 = 'ZYZMZM技术博客\t1300\t\t25w+\t\t1100'
print(s2)
print(s3)
结果如下:

字符串格式化
% 格式化
Python提供了“%”对各种类型的数据进行格式化输出:
price = 100
print("the book's price is %s" % price)
# 输出 the book's price is 100
如上,“%s”作为转换说明符,其作用实际上是一个占位符,被之后的变量或表达式的值代替,中间使用“%”作为分隔符。
如果格式化字符串中包含多个“%s”占位符,那么之后应该对应地提供多个变量,并且使用圆括号将这些变量括起来:
user = "ZYZMZM"
age = 21
# 格式化字符串有两个占位符,第三部分提供2个变量
print("%s is a %s years old boy" % (user , age))
# 输出 ZYZMZM is a 21 years old boy
Python提供了如下表所示的转换说明符:
| 转换说明符 | 说明 |
|---|---|
| %d,%i | 转换为带符号的十进制形式的整数 |
| %o | 转换为带符号的八进制形式的整数 |
| %x,%X | 转换为带符号的十六进制形式的整数 |
| %e | 转化为科学计数法表示的浮点数(e 小写) |
| %E | 转化为科学计数法表示的浮点数(E 大写) |
| %f,%F | 转化为十进制形式的浮点数 |
| %g | 智能选择使用 %f 或 %e 格式 |
| %G | 智能选择使用 %F 或 %E 格式 |
| %c | 格式化字符及其 ASCII 码 |
| %r | 使用 repr() 将变量或表达式转换为字符串 |
| %s | 使用 str() 将变量或表达式转换为字符串 |
当使用上面的转换说明符时可指定转换后的最小宽度:
num = -28
print("num is: %6i" % num)
print("num is: %6d" % num)
print("num is: %6o" % num)
print("num is: %6x" % num)
print("num is: %6X" % num)
print("num is: %6s" % num)
运行结果:
num is: -28
num is: -28
num is: -34
num is: -1c
num is: -1C
num is: -28
有结果可见,指定了字符串的最小宽度为6,因此程序转换数值时总宽度为6,自动在数值前面补充了三个空格。
默认情况下,转换出来的字符串是右对齐的,不够宽度时左边补充空格,Python中支持如下标志:
- - :指定左对齐
- +:表示数值总要带着符号
- 0:表示不补充空格,而是补充0
num2 = 88
# 最小宽度为0,左边补0
print("num2 is: %06d" % num2)
# 最小宽度为6,左边补0,总带上符号
print("num2 is: %+06d" % num2)
# 最小宽度为6,右对齐
print("num2 is: %-6d" % num2)
运行结果:
num2 is: 000088
num2 is: +00088
num2 is: 88
对于转换浮点数,Python还允许指定小数点后的数字位数;如果是字符串,Python允许指定转换后的字符串的最大字符数,成为精度值,该精度值被放在最小宽度之后,中间使用(.)隔开:
my_value = 3.001415926535
# 最小宽度为8,小数点后保留3位
print("my_value is: %8.3f" % my_value)
# 最小宽度为8,小数点后保留3位,左边补0
print("my_value is: %08.3f" % my_value)
# 最小宽度为8,小数点后保留3位,左边补0,始终带符号
print("my_value is: %+08.3f" % my_value)
the_name = "ZYZMZM"
# 只保留3个字符
print("the name is: %.3s" % the_name) # 输出ZYZ
# 只保留2个字符,最小宽度10
print("the name is: %10.2s" % the_name)
结果如下:
my_value is: 3.001
my_value is: 0003.001
my_value is: +003.001
the name is: ZYZ
the name is: ZY
format 格式化
相对基本格式化输出采用‘%’的方法,format()功能更强大,该函数把字符串当成一个模板,通过传入的参数进行格式化,并且使用大括号‘{}’作为特殊字符代替‘%’
字符串format()方法的基本使用格式如下:
<模板字符串>.format(<逗号分隔的参数>)
format()方法可以非常方便地连接不同类型的变量或内容,如果需要输出大括号,采用{{…}}。
下面讲解format的基础用法 —— 位置匹配。
- 不带编号,即“{}”
- 带数字编号,可调换顺序,即“{1}”、“{2}”
- 带关键字,即“{name}”、“{num}”
# 不带编号位置匹配
print("{}{}{}".format("圆周率",3.1415926,"..."))
#带数字编号位置匹配
print("圆周率{{{1}{2}}}是{0}".format("无理数",3.1415926,"..."))
# 大括号本身是字符串的一部分
s = "圆周率{{{1}{2}}}是{0}"
# 调用format时解析大括号
print(s.format("无理数",3.1415926,"..."))
# 带关键字位置匹配
print('{name} {num} {singal}'.format(name='圆周率',num=3.1415926,singal="..."))
运行结果:
圆周率3.1415926...
圆周率{3.1415926...}是无理数
圆周率{3.1415926...}是无理数
圆周率3.1415926...
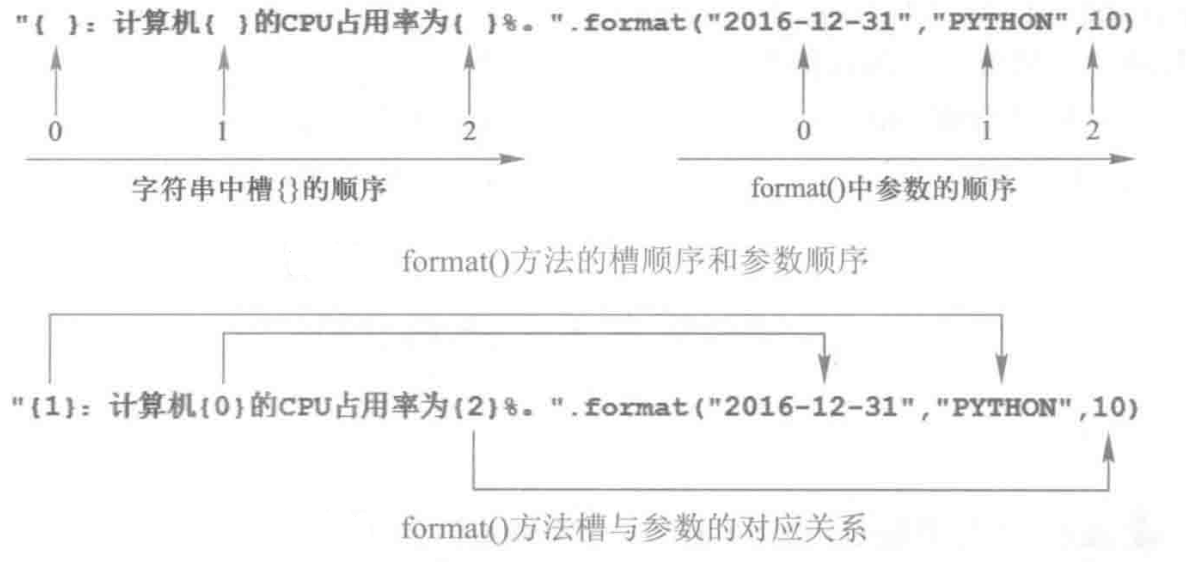
format()方法中<模板字符串>的槽除了包括参数序号,还可以包括格式控制信息。此时,槽的内部样式如下:
{<参数序号>: <格式控制标记>}
其中,<格式控制标记>用来控制参数显示时的格式,格式内容如下图:

格式控制标记包括:<填充>、<对齐>、<宽度>、<.精度>、<类型>6 个字段,这些字段都是可选的,可以组合使用,逐一介绍如下。
宽度:指当前槽的设定输出字符宽度,如果该槽对应的format()参数长度比<宽度>设定值大,则使用参数实际长度。如果该值的实际位数小于指定宽度,则位数将被默认以空格字符补充。
对齐:指参数在<宽度>内输出时的对齐方式,分别使用<、> 和 ^三个符号表示左对齐、右对齐和居中对齐。
填充:指<宽度>内除了参数外的字符采用什么方式表示,默认采用空格,可以通过<填充>更换。
s = "PYTHON"
print("{0:30}".format(s)+"!") # 默认左对齐
print("{0:>30}".format(s)+"!") # 右对齐
print("{0:*^30}".format(s)+"!") # 居中且使用*填充
print("{0:-^30}".format(s)+"!") # 居中且使用-填充
print("{0:3}".format(s)+"!") # 宽度小于实际位数,使用参数实际长度
运行结果如下:
PYTHON !
PYTHON!
************PYTHON************!
------------PYTHON------------!
PYTHON!
格式控制标记中的逗号(,)用于显示数字类型的千位分隔符:
print("{0:-^20}".format(1234567890))
print("{0:-^20,}".format(1234567890))
print("{0:-^20,}".format(123456.7890
运行结果:
-----1234567890-----
---1,234,567,890----
----123,456.789-----
<.精度>表示两个含义,由小数点(.)开头。对于浮点数,精度表示小数部分输出的有效位数。对于字符串,精度表示输出的最大长度。
print("{0:.2f}".format(12345.67890))
print("{0:H^20.3f}".format(12345.67890))
print("{0:H^20,.3f}".format(12345.67890))
print("{0:.4}".format("PYTHON"))
运行结果:
12345.68
HHHHH12345.679HHHHHH
HHHHH12,345.679HHHHH
PYTH
<类型>表示输出整数和浮点数类型的格式规则。对于整数类型,输出格式包括以下6种:
- b: 输出整数的二进制方式
- c: 输出整数对应的 Unicode 字符
- d: 输出整数的十进制方式
- o: 输出整数的八进制方式
- x: 输出整数的小写十六进制方式
- X: 输出整数的大写十六进制方式
print("{0:b},{0:c},{0:d},{0:o},{0:x},{0:X}".format(425))
# 110101001,Ʃ,425,651,1a9,1A9
对于浮点数类型,输出格式包括以下4 种:
- e: 输出浮点数对应的小写字母 e 的指数形式
- E: 输出浮点数对应的大写字母 E 的指数形式
- f: 输出浮点数的标准浮点形式
- %: 输出浮点数的百分形式。
浮点数输出时尽量使用<.精度>表示小数部分的宽度,有助于更好控制输出格式。
print("{0:e},{0:E},{0:f},{0:%}".format(3.14))
# 输出:'3.14e+00,3.14E+00,3.14,314.00%'
print("{0:.2e},{0:.2E},{0:.2f},{0:.2%}".format(3.14))
# 输出:'3.14e+00,3.14E+00,3.14,314.00%'
序列相关方法
字符串本质上就是由多个字符组成的,因此程序允许通过索引来操作字符,比如获取指定索引处的字符,获取指定字符在字符串中的位置等。Python字符串直接在方括号([])中使用索引即可获取对应的字符。
Python字符串的索引分为正向递增和反向递减两种。

s = 'zyzmzm.blog is very good'
# 获取s中索引2处的字符
print(s[2]) # 输出z
# 获取s中从右边开始,索引4处的字符
print(s[-4]) # 输出g
除获取单个字符外,也可以使用范围来获取字符串的子串:
# 获取s中从索引3处到索引5处(不包含)的子串
print(s[3: 5]) # 输出mz
# 获取s中从索引3处到倒数第5个字符的子串
print(s[3: -5]) # 输出mzm.blog is very
# 获取s中从倒数第6个字符到倒数第3个字符的子串
print(s[-6: -3]) # 输出y g
Python还允许省略起始索引或结束索引。如果省略起始索引,相当于从字符串开始处开始截取;如果省略结束索引,相当于截取到字符串的结束处:
# 获取s中从索引5处到结束的子串
print(s[5: ]) # 输出m.blog is very good
# 获取s中从倒数第6个字符到结束的子串
print(s[-6: ]) # 输出y good
# 获取s中从开始到索引5处的子串
print(s[: 5]) # 输出zyzmz
# 获取s中从开始到倒数第6个字符的子串
print(s[: -6]) #输出zyzmzm.blog is ver
此外,Python字符串还支持用in运算符判断是否包含某个子串:
# 判断s是否包含'zy'子串
print('zy' in s) # True
print('yb' in s) # False
要想获得字符串的长度,可以使用Python的内置函数len():
# 输出s的长度
print(len(s)) # 24
# 输出'test'的长度
print(len('test')) # 4
还可以使用全局内置的min()和max()函数获取字符串中最小字符和最大字符:
# 输出s字符串中最大的字符
print(max(s)) # z
# 输出s字符串中最大的字符
print(min(s)) # 空格
大小写相关方法
Python字符串由内建的str类代表,我们首先介绍两个帮助函数:
- dir():列出指定类或模块包含的全部内容(包括方法、函数、类、变量等)。
- help():查看某个函数或方法的帮助文档
>>> dir(str)
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__',
'__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__',
'__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__',
'__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__',
'__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__',
'__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize',
'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find',
'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii',
'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric',
'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower',
'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust',
'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith',
'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
上面列出了str类提供的所有方法,其中以“__”开头结尾的方法被约定为私有成员方法,不希望被外部直接调用。
如果希望查看某个方法的调用,可以使用help()函数:
 在str类中与大小写相关的常用方法如下:
在str类中与大小写相关的常用方法如下:
- title():将每个单词的首字母改为大写
- lower():将整个字符串改为小写
- upper():将整个字符串改为大写
a = 'Zyzmzm.blog is very good'
# 每个单词首字母大写
print(a.title())
# 每个单词首字母小写
print(a.lower())
# 每个单词首字母大写
print(a.upper())
运行结果:
Zyzmzm.Blog Is Very Good
zyzmzm.blog is very good
ZYZMZM.BLOG IS VERY GOOD
删除空白
str提供了如下常用的方法来删除空白:
- strip():删除字符串前后的空白
- lstrip():删除字符串前面(左边)的空白
- rstrip():删除字符串后边(右边)的空白
注意:Python的str是不可变的,因此上述三个方法只是返回字符串前面或者后面空白被删除之后的副本,并没有改变字符串本身。
s = ' this is a blog '
# 删除左边的空白
print(s.lstrip())
# 删除右边的空白
print(s.rstrip())
# 删除两边的空白
print(s.strip())
# 再次输出s,将会看到s并没有改变
print(s)
另外,上述三个方法也可以传入参数,可以删除字符串前后指定字符:
s2 = 'i think it is a scarecrow'
# 删除左边的i、t、o、w字符
print(s2.lstrip('itow'))
# 删除右边的i、t、o、w字符
print(s2.rstrip('itow'))
# 删除两边的i、t、o、w字符
print(s2.strip('itow'))
运行结果:
think it is a scarecrow
i think it is a scarecr
think it is a scarecr
查找与替换
str提供了如下常用的执行查找、替换等操作的方法:
- startswith():判断字符串是否以指定子串开头
- endswith():判断字符串是否以指定子串结尾
- find():查找指定子串在字符串中出现的位置,如果没有找到指定子串,则返回-1
- index():查找指定子串在字符串中出现的位置 ,如果没有找到,则引发ValueError错误
- replace():使用指定子串替换字符串中的目标子串
- translate():使用指定翻译映射表对字符串执行替换
s = 'zyzmzm.blog is a good site'
# 判断s是否以zyzmzm开头
print(s.startswith('zyzmzm')) # True
# 判断s是否以site结尾
print(s.endswith('site')) # True
# 查找s中'blog'的出现位置
print(s.find('blog')) # 7
# 查找s中'blog'的出现位置
print(s.index('blog')) # 7
# 从索引为9处开始查找'blog'的出现位置
print(s.find('blog', 9)) # -1
# 从索引为9处开始查找'org'的出现位置
#print(s.index('blog', 9)) # 引发错误
# 将字符串中所有g替换成G
print(s.replace('g', 'G')) # zyzmzm.bloG is a Good site
# 将字符串中1个g替换成G
print(s.replace('g', 'G', 1)) # zyzmzm.bloG is a good site
# 定义替换表:97(a)->945(α),98(b)->945(β),116(t)->964(τ),
table = {97: 945, 98: 946, 116: 964}
print(s.translate(table)) # zyzmzm.βlog is α good siτe
str的translate()方法需要根据翻译映射表对字符串进行查找、替换,但是我们是自己填入了字符编码,Python为str类提供了一个maketrans()方法,通过该方法可以非常方便地创建翻译映射表。
s = 'zyzmzm.blog is a good site'
# 定义a->α、b->β、t->τ的映射
table = str.maketrans('abt','αβτ')
print(s.translate(table)) # zyzmzm.βlog is α good siτe
分割、连接方法
Python语言还为str提供了分割和连接方法。
- split():将字符串按指定分隔符分割成多个短语
- join():将多个短语连接成字符串。
s = 'zyzmzm.blog is a good site'
# 使用空白对字符串进行分割
print(s.split()) # 输出 ['zyzmzm.blog', 'is', 'a', 'good', 'site']
# 使用空白对字符串进行分割,最多只分割前2个单词
print(s.split(None, 2)) # 输出 ['zyzmzm.blog', 'is', 'a good site']
# 使用点进行分割
print(s.split('.')) # 输出 ['zyzmzm', 'blog is a good site']
mylist = s.split()
# 使用'/'为分割符,将mylist连接成字符串
print('/'.join(mylist)) # 输出 zyzmzm.blog/is/a/good/site
# 使用','为分割符,将mylist连接成字符串
print(','.join(mylist)) # 输出 zyzmzm.blog,is,a,good,site
从上面的运行结果可以看出,str的split()和join()方法互为逆操作——split()方法用于将字符串分割成多个短语;而join()方法则用于将多个短语连接成字符串。
