 《Python基础语法全体系》系列博文第一篇,本篇博文讲解Python的基本语法元素,包括Python中的缩进与注释、变量与命名、输入与输出、关键字与内置函数等;接着介绍Python的数据类型,包括基本数据类型:数值类型、字符串类型。
《Python基础语法全体系》系列博文第一篇,本篇博文讲解Python的基本语法元素,包括Python中的缩进与注释、变量与命名、输入与输出、关键字与内置函数等;接着介绍Python的数据类型,包括基本数据类型:数值类型、字符串类型。
Python基本语法元素
缩进与注释
此部分我们主要介绍Python的缩进、注释、变量、命名和保留字。
Python是用缩进来标识语句块的。在Python中,是通过代码的缩进,来决定代码的逻辑的。通俗的说,Python中的代码的缩进,不是为了好看,而是表示代码的含义,代表着上下行代码之间的关系。强制缩进其实是Python保持代码风格统一且可读性良好的机制。如下面的代码:
# print absolute value of an integer:
a = 100
if a >= 0:
print(a)
else:
print(-a)
Python语言允许在任何地方插入空字符和字符串,但是不能插入到标识符和字符串中间。Python源代码的注释有两种形式:单行注释和多行注释。Python使用 # 表示单行注释的开始,跟在 # 号后面直到这行结束为止的代码都将被解释器忽略。多行注释是指一次性将程序中的多行代码都注释掉,在Python程序中使用三个单引号或三个双引号将注释的内容括起来。其实三个引号是Python的长字符串表达形式,后文会详解。
# 这是一行简单的注释
print("Hello World!")
'''
这里面的内容全部是多行注释
'''
# print("这行代码被注释了,将不会被编译、执行!")
"""
这是用三个双引号括起来的多行注释
Python同样是允许的。
"""
变量与命名
Python使用等号 ( = ) 作为赋值运算符,例如a = 20就是一条赋值语句,作用就是将20赋值给变量a。
Python是弱类型语言,弱类型语言有两个特征:
- 变量无需声明即可直接赋值:对一个不存在的变量赋值相当于定义了一个新变量。
- 变量的数据类型可以动态改变:同一个变量可以一会儿被赋值为整形,一会儿被赋值为字符串。
# 定义一个数值类型变量
a = 5
print(a)
# 重新将字符串值赋值给a变量
a = 'Hello, ZYZMZM'
print(a)
print(type(a))
程序将输出以下结果
5
Hello, ZYZMZM
<class 'str'>
接下来我们介绍变量的命名规则。Python需要使用标识符给变量命名,其实标识符就是用于给程序中变量、类、方法命名的符号。Python语言的标识符必须以字母、下划线开头,后边可以跟任意数目的字母、数字和下划线。此处的字母并不局限于大小写英文字母,可以包含中文字符、日文字符等。
由于Python 3支持UTF-8字符集,因此Python 3的标识符可以使用UTF-8所能表示的多种语言的字符。Python语言是区分大小写的,因此abc和ABC是两个不同的标识符。
在使用标识符时,需要注意如下规则:
- 标识符可以由字母、数字、下画线(_)组成,其中数字不能打头。
- 标识符不能是 Python 关键字,但可以包含关键字。
- 标识符不能包含空格。
例如下面变量,有些是合法的,有些是不合法的:
abc_xyz:合法。
HelloWorld:合法。
abc:合法。
xyz#abc:不合法,标识符中不允许出现“#”号。
abc1:合法。
1abc:不合法,标识符不允许数字开头。
关键字和内置函数
Python包含了如下表所示的关键字:
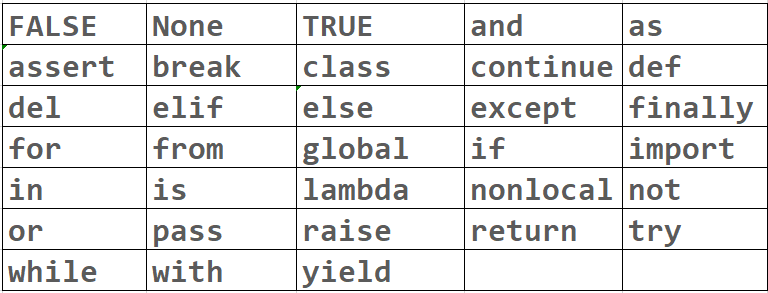
上面这些关键字都不可以作为变量名。
此外,Python 3还提供了如下表所示的内置函数:

上面这些内置函数名字也不应该作为标识符。
有关这些内置函数的具体作用可以查询:《Python内置函数》
输入和输出
Python使用print()函数向打印程序输出,采用input()函数接收程序输入。
print()函数的详细语法格式如下:
print(value, ..., sep = ' ', end = '\n', file = sys.stdout, flush = False)
'''
sep指定分隔符,end参数控制行尾,file指定输出目标,flush用于控制输出缓存
'''
从上面的语法格式可以看出,value函数可以接受任意多个变量或值,因此print函数完全可以输出多个值。如下:
user_name = 'ZYZMZM'
user_age = 21
# 同时输出多个变量和字符串
print("读者名:" , user_name, "年龄:", user_age)
程序输出如下结果:读者名: ZYZMZM 年龄: 21
从输出结果来看,使用print()函数输出多个变量时,print()函数默认以空格隔开多个变量,如果我们希望改变默认的分隔符,可以通过sep参数进行设置:
# 同时输出多个变量和字符串,指定分隔符
print("读者名:" , user_name, "年龄:", user_age, sep='|')
运行结果:读者名:|ZYZMZM|年龄:|21
在默认情况下,print()函数输出之后总会换行,这是因为print()函数的end()参数的默认值是“\n”。若希望print()函数执行后不换行,那么重设end参数即可。使用end="",如下:
# 指定end参数,指定输出之后不再换行
print(40, '\t', end="")
print(50, '\t', end="")
print(60, '\t', end="")
运行结果:40 50 60
file参数指定 print() 函数的输出目标,file 参数的默认值为 sys.stdout,该默认值代表了系统标准输出,也就是屏幕,因此 print() 函数默认输出到屏幕。实际上,完全可以通过改变该参数让 print() 函数输出到特定文件中,例如如下代码:
f = open("poem.txt", "w") # 打开文件以便写入
print('沧海月明珠有泪', file=f)
print('蓝田日暖玉生烟', file=f)
f.close()
print() 函数的 flush 参数用于控制输出缓存,该参数一般保持为 False 即可,这样可以获得较好的性能。
Python3.x 中 input() 函数接受一个标准输入数据,返回为 string 类型。
在 Python3.x 中 raw_input() 和 input() 进行了整合,去除了 raw_input( ),仅保留了input( )函数,其接收任意任性输入,将所有输入默认为字符串处理,并返回字符串类型。
a = input("input:") # 输入整数123
print((type(a)))
a = input("input:") #输入字符串 abcdef
print((type(a)))
输出如下:
input:123456
<class 'str'>
input:abcdef
<class 'str'>
因此,当我们接受用户输入,并进行数学计算时,要将用户输入转换为数字格式。在这里我们简单介绍一个Python非常有用的内置函数eval(),它的作用是返回传入字符串的表达式的结果,我们便可以与input()函数连用,实现方便的数值计算。
num = eval(input("input: "))
print(num)
num = eval(input("input: "))
print(f"{num} + 2 = {num + 2}")
运行结果如下:
input: 3 + 2
5
input: 3
3 + 2 = 5
Python基本数据类型
Python数据类型部分我们详细讲解Python的两大类基本数据类型:数值类型、字符串类型,三大类组合数据类型:集合类型、序列类型和字典类型
数值类型:整型、浮点型、复数
Python 3的整形支持各种整数值,不管是小的整数值,还是大的整数值,Python都能轻松处理。
# 定义变量a,赋值为56
a = 56
print(a)
# 为a赋值一个大整数
a = 9999999999999999999999
print(a)
# type()函数用于返回变量的类型
print(type(a))
结果如下:
56
9999999999999999999999
<class 'int'>
根据上述结果,我们将大整数9999999999999999999999赋值给变量a,程序也不会发生溢出并且运行正常。整数类型理论上取值范围是[-∞, +∞],实际上的取值范围受限于运行Python程序的计算机内存大小。除极大数的运算外,一般认为整数类型没有取值范围限制。
Python的整型支持None值(空值),空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。如下:
a = None
print(a)
print(type(a))
输出:
None
<class 'NoneType'>
Python的整型数值有4种表达形式:
- 十进制形式:最普通的整数就是十进制形式的整数。
- 二进制形式:以 0b 或 0B 开头的整数就是二进制形式的整数。
- 八进制形式:以 0o 或 0O 开头的整数就是八进制形式的整数(第二个字母是大写或小写的 O)。
- 十六进制形式:以 0x 或 0X 开头的整数就是十六进制形式的整数,其中 10~15 分别以 a~f( 此处的 a~f 不区分大小写)来表示。
# 以0x或0X开头的整数数值是十六进制的整数
hex_value1 = 0x13
hex_value2 = 0XaF
print("hexValue1的值为:", hex_value1)
print("hexValue2的值为:", hex_value2)
# 以0b或0B开头的整数数值是二进制的整数
bin_val = 0b111
print('bin_val的值为:', bin_val)
bin_val = 0B101
print('bin_val的值为:', bin_val)
# 以0o或0O开头的整数数值是二进制的整数
oct_val = 0o54
print('oct_val的值为:', oct_val)
oct_val = 0O17
print('oct_val的值为:', oct_val)
运行结果:
hexValue1的值为: 19
hexValue2的值为: 175
bin_val的值为: 7
bin_val的值为: 5
oct_val的值为: 44
oct_val的值为: 15
为了提高数值(包括浮点型)的可读性,Python 3.x 允许为数值(包括浮点型)增加下划线作为分隔符。这些下画线并不会影响数值本身。例如如下代码:
# 在数值中使用下画线
one_million = 1_000_000
print(one_million)
price = 234_234_234 # price实际的值为234234234
android = 1234_1234 # android实际的值为12341234
接下来我们介绍 浮点型数据。
浮点型数值用于保存带小数点的数值,Python的浮点数有两种表示形式。
- 十进制形式:这种形式就是平常简单的浮点数,如5.20、520.0。
- 科学计数形式:只有浮点型数值才可以使用科学计数形式。例如52000是一个整型值,但520E2则是浮点数值。
示例程序如下:
af1 = 5.2345556
print("af1的值为:", af1)
af2 = 25.2345
print("af2的类型为:", type(af2))
f1 = 5.20e2
print("f1的值为:", f1)
f2 = 5e3
print("f2的值为:", f2)
print("f2的类型为:", type(f2)) # 类型为float
运行结果如下:
af1的值为: 5.2345556
af2的类型为: <class 'float'>
f1的值为: 520.0
f2的值为: 5000.0
f2的类型为: <class 'float'>
浮点数间的运算存在不确定尾数,这并不是Python预言的bug,在很多编程语言都普遍存在。也就是当某个浮点数并不能被2进制精确表示的时候,就会出现不确定尾数。
因为十进制数和二进制数之间不存在一一映射的关系,所以某些十进制数是不能被二进制精确表示的,而只能近似表示,这样就造成了计算的二进制结果是十进制结果的一个近似数。如0.1表示为二进制的数时,是无限的,可以无限接近0.1但不等于0.1。
print(0.1+0.2)
运算结果是:0.30000000000000004
因此语句0.1+0.2 == 0.3,判断结果为False。此时可以使用Python的内置函数round(x[,d])对x四舍五入,d是小数保留的位数。默认取整,[,d]表示可有可无。
print(0.1+0.2 == 0.3) # False
print(round(0.1+0.2, 1) == 0.3) #True
接下来我们介绍最后一种数值类型——复数类型。
Python支持复数,复数的虚部用 j 或 J 来表示。
如果需要在程序中对复数进行计算,可导入Python的cmath模块(c代表complex),在该模块下包含了各种支持复数运算的函数。另外采用eval()函数对程序输入的复数可以进行一系列运算。
ac1 = 3 + 0.2j
print(ac1)
print(type(ac1)) # 输出 complex类型
ac2 = 4 - 0.1j
print(ac2)
# 复数运行
print(ac1 + ac2) # 输出 (7+0.1j)
# 导入cmatch模块
import cmath
# sqrt()是cmath模块下的函数,用于计算平方根
ac3 = cmath.sqrt(-1)
print(ac3) # 输出 1j
# 采用eval对输入的复数进行解析
complexStr = eval(input("input: "))
print(complexStr ** 2) # 输出(5+12j)
运行结果如下:
(3+0.2j)
<class 'complex'>
(4-0.1j)
(7+0.1j)
1j
input: 3 + 2j
(5+12j)
字符串类型
字符串是Python中非常重要的数据类型之一,我们分两部分来讲,一部分是字符串与编码基础,另一部分讲解字符串的高级使用、内置函数、处理操作:《Python基础语法全体系 | 深入剖析字符串类型及其操作》
Python 3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言。对于单个字符的编码,Python提供了解两个重要的函数:
ord()函数获取字符的整数表示chr()函数把编码转换为对应的字符
num = ord('B')
print(num) # 66
ch = chr(num + 2)
print(ch) # D
讲完了字符编码,接下来我们简单谈谈字符串。
在Python中,字符串的内容几乎可以包含任何字符,英文字符和中文字符都可以。字符串可以用单引号、双引号、三引号括起来,没有任何区别。
str1 = 'ZYZMZM'
str2 = "blog"
str3 = '''CSDN'''
print(str1, str2, str3) # ZYZMZM blog CSDN
但是如果字符串内容本身包含了单引号或双引号,此时就需要进行特殊处理:
- 使用不同的引号将字符串括起来
- 对引号进行转义
# way1:使用不同引号
str1 = "I'm a student"
str2 = 'you are "panda"'
str3 = '''I'm a "student"'''
# way2:对引号进行转义"
str4 = "I\'m a \"student\""
print(str1) # I'm a student
print(str2) # you are "panda"
print(str3) # I'm a "student"
print(str4) # I'm a "student"
接下来讲解拼接字符串。
Python 3使用字符串 ’ + ’ 作为的字符串的拼接运算符:
str1 = 'ZYZMZM'
str2 = " blog"
str3 = ''' CSDN'''
str4 = str1 + str2 + str3
# 使用 + 拼接字符串
print(str4) # ZYZMZM blog CSDN
接下来我们讲解字符串与数值的拼接,Python不允许直接拼接数值和字符串,程序必须将数值转换成字符串。
将数值转换成字符串,可以使用str() 或 repr() 函数:
s1 = "这本书的价格是:"
p = 99.8
# 字符串直接拼接数值,程序报错
# print(s1 + p)
# 使用str()将数值转换成字符串
print(s1 + str(p))
# 使用repr()将数值转换成字符串
print(s1 + repr(p))
repr()还有一个功能,就是它会以Python表达式的形式来表示值。
st = "I will play my fife"
print(st)
print(repr(st))
结果如下:
I will play my fife
'I will play my fife'
通过上面的输出可以看出,直接使用print()函数输出字符串,只能看到字符串内容,没有引号;但如果先使用repr()函数对字符串进行处理,然后再使用print()执行输出,可以看到带引号的字符串——这就是字符串的Python表达式形式。
前文中有提到Python的多行注释使用三个引号来包含多行注释的内容,其实这是长字符串的写法,只是由于在长字符串中可以防止任何内容,包括放置单引号、双引号都可以。如果所定义的长字符串没有赋值给任何变量,那么这个字符串就相当于被解释器忽略掉了,也就是相当于注释掉了。
实际上,使用是三个引号括起来的长字符串完全可以赋值给变量:
str = '''ZYZMZM \
BLOG \
CSDN'''
print(str) # ZYZMZM BLOG CSDN
上面程序中我们也使用了转义字符(\)对换行符进行转义,转义之后的换行符不会“中断”字符串,因此可以把字符串写成多行。
Python不是自由格式的语言,因此Python程序的换行、缩进都有其规定的语法。因此,Python表达式不允许随便换行。如果程序需要对Python表达式换行,同样需要使用转义字符(\)进行转义:
num = 20 + 3 / 4 + \
2 * 3
print(num) # 26.75
接下来我们讲解原始字符串。
由于字符串中的反斜线都有特殊的作用,因此当字符串中包含反斜线时,就需要对其进行转义。
# 下面的windows路径写法在Python中是Error的
path1 = G:\publish\codes
# 可以下成下面这种格式
path2 = G:\\publish\\codes
虽然我们可以再使用转义字符解决这个问题,但是这样的写法非常繁琐,我们可以借助于原始字符串来解决这个问题,原始字符串以‘r’开头,不会把反斜线当成特殊字符。因此上面的windows路径可以直接写为r'G:\publish\codes'
Python 3中新增了bytes类型,字符串有多个字符组成,以字符为单位进行操作;bytes由多个字节组成,以字节为单位进行操作。
bytes 和 str 除操作的数据单元不同之外,它们支持的所有方法都基本相同,bytes 也是不可变序列。
bytes 对象只负责以字节(二进制格式)序列来记录数据,至于这些数据到底表示什么内容,完全由程序决定。如果采用合适的字符集,字符串可以转换成bytes 对象;反过来,bytes 对象也可以恢复成对应的字符串。
由于 bytes 保存的就是原始的字节(二进制格式)数据,因此 bytes 对象可用于在网络上传输数据,也可用于存储各种二进制格式的文件,比如图片、音乐等文件。
如果希望将一个字符串转换成 bytes 对象,有如下三种方式:
- 如果字符串内容都是 ASCII 字符,则可以通过直接在字符串之前添加 b 来构建bytes 对象。
- 调用 bytes() 函数(其实是 bytes 的构造方法)将字符串按指定字符集转换成bytes 对象,如果不指定字符集,默认使用 UTF-8 字符集。
- 调用字符串本身的
encode()方法将字符串按指定字符集转换成字节串,如果不指定字符集,默认使用 UTF-8 字符集。
# 创建一个空的bytes
b1 = bytes()
# 创建一个空的bytes值
b2 = b''
# 通过b前缀指定hello是bytes类型的值
b3 = b'hello'
print(b3)
print(b3[0])
print(b3[2:4])
# 调用bytes方法将字符串转成bytes对象
b4 = bytes('zyzmzm-技术博客',encoding='utf-8')
print(b4)
# 利用字符串的encode()方法编码成bytes,默认使用utf-8字符集
b5 = "Python语言程序设计".encode('utf-8')
print(b5)
运行结果如下:
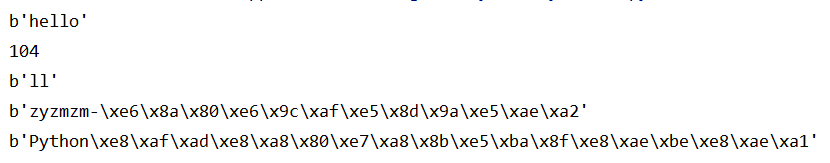
如果程序获得了bytes对象,也可调用bytes对象的decode()方法将其解码成字符串,在上述程序中添加如下代码:
# 将bytes对象解码成字符串,默认使用utf-8进行解码。
st = b5.decode('utf-8')
print(st) # Python语言程序设计
接下来讲解字符集、字符编码。
在Python 3里面,所有的字符串均是以Unicode码存储的。
简单介绍一下字符集的概念。计算机底层并不能保存字符,但程序总是需要保存各种字符的,那该怎么办呢?计算机“科学家”就想了一个办法:为每个字符编号,当程序要保存字符时,实际上保存的是该字符的编号;当程序读取字符时,读取的其实也是编号,接下来要去查“编号一字符对应表”(简称码表)才能得到实际的字符。
因此,所谓的字符集,就是所有字符的编号组成的总和。早期美国人给英文字符、数字、标点符号等字符进行了编号,他们认为所有字符加起来顶多 100 多个,只要 1 字节(8 位,支持 256 个字符编号)即可为所有字符编号一一这就是 ASCII 字符集。
后来,亚洲国家纷纷为本国文字进行编号,即制订本国的字符集,但这些字符集并不兼容。于是美国人又为世界上所有书面语言的字符进行了统一编号,这次他们用了两个字节(16 位,支持 65536 个字符编号),这就是 Unicode 字符集。实际使用的 UTF-8, UTF-16 等其实都属于 Unicode 字符集。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。ASCII编码是1个字节,而Unicode编码通常是2个字节。
如果文本基本上全部是英文的话,Unicode编码比ASCII编码需要多一倍的存储空间,因此,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果文本包含大量英文字符,用UTF-8编码就能节省空间。
下面我们总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。

用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
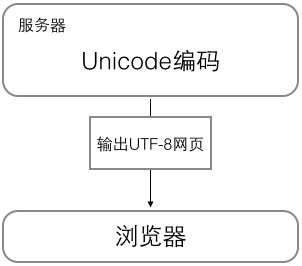
所以我们会看到很多网页的源码上会有类似的信息,表示该网页正是用的UTF-8编码。
以上我们简单介绍了Python字符串的基础知识,有关Python字符串的深入讲解,请大家阅读博文:《Python基础语法全体系 | 深入剖析字符串类型及其操作》
运算符
Python语言使用运算符将一个或多个操作数连接成可执行语句,用来实现特定功能。
Python语言中的运算符可分为如下几种:
- 赋值运算符:=
- 算术运算符:+,-,*,/,//,%,**
- 位运算符:&,|,^,~,<<,>>
- 索引运算符:[ ]
- 比较运算符:>,>=,<,<=,==,!=,is,is not
- 逻辑运算符:and,or,not
- 三目运算符、in运算符(in、not in)
上述运算符的详细功能这里不做过多介绍,大家可参考《Python运算符》进行查阅了解。
我们单独提出下面几个拥有特殊功能的运算符:
- + 除了作为加法运算符,也可以作为连接运算符
- - 除了作为减法运算符,也可以作为求负运算符
- * 除了作为乘法运算符,也可以作为连接运算符
Python 可通过if语句来实现三目运算符的功能,语法格式如下:
True_statements if expression else False_statements
三目运算符的规则是:先对逻辑表达式expression求值,如果为True,则执行并返回True_statements的值,否则执行并返回expression的值。
a = 5
b = 3
# 输出“a大于b”
print("a 大于 b") if a > b else print("a 不大于 b")
Python允许在三目运算符的 True_statements 或 False_statements 中放置多条语句。Python 主要支持以下两种放置方式:
- 多条语句以英文逗号隔开:每条语句都会执行,程序返回多条语句的返回值组成的元组。
- 多条语句以英文分号隔开:每条语句都会执行,程序只返回第一条语句的返回值。
a = 5; b = 3
# 第一个返回值部分使用两条语句,逗号隔开
st = print("crazyit"), 'a大于b' if a > b else "a不大于b" # crazyit
print(st) # (None, 'a大于b')
# 第一个返回值部分使用两条语句,分号隔开
st = print("crazyit"); x = 20 if a > b else "a不大于b" # crazyit
print(st) # None,print("crazyit")的返回值
print(x) # 20
三目运算符 支持嵌套,通过嵌套三目运算符,可以执行更复杂的判断:
# 下面将输出c等于d
print("c大于d") if c > d else (print("c小于d") if c < d else print("c等于d"))
Python 提供了in运算符,用于判断某个成员是否位于序列中,例如之前介绍的字符串就是一个序列,因此程序可以使用in运算符判断字符串是否包含特定子串:
s = 'zhaoyang.blog.csdn.net'
print('zhaoyang' in s) # True
print('zhaoyang' not in s) # True
print('http' in s) # False
print('http' not in s) # True
使用in运算符除了可以判断字符串是否包含特定子串之外,还可以判断是否包含子序列。关于序列的知识我们会在后续博文中进行讲解。
运算符的结合性和优先级:
