 《Python基础语法全体系》系列博文第三篇,本篇博文将详细深入地讲解Python的组合数据类型,包括集合类型及其常用操作,序列类型:列表与元组常用操作,以及映射类型:字典的常用操作。
《Python基础语法全体系》系列博文第三篇,本篇博文将详细深入地讲解Python的组合数据类型,包括集合类型及其常用操作,序列类型:列表与元组常用操作,以及映射类型:字典的常用操作。
其中列表元组和字典这三大数据结构对于Python编程而言是非常重要的,都是python编程中必不可少的内容。本文整理自疯狂python编程、Python语言程序设计基础。
文章目录
综述
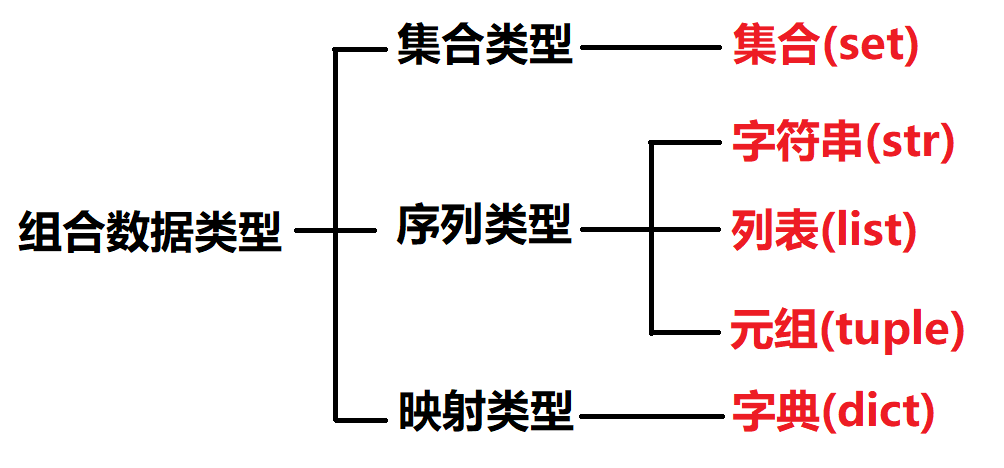
组合数据类型能够将多个同类型或不同类型的数据组织起来,通过单一的表示使数据更有序、更容易。根据数据之间的关系,组合数据类型可以分为三类组合数据类型分3类:集合类型、序列类型和映射类型。
- 集合类型是一个元素集合,元素之间无序,相同元素在集合中唯一存在。
- 序列类型是一个元素向量,元素之间存在先后关系,通过序号访问,元素之间不排他。
- 映射类型是“键-值”数据项的组合,每个元素是一个键值对,表示为(key,value)。
组合数据类型的分类如下:
集合类型
集合类型与数学中集合的概念一致,即包含0个或多个数据项的无序组合。集合中的元素不可重复,元素类型只能是固定数据类型,例如整数、浮点数、字符串、元组等,列表、字典和集合类型本身都是可变数据类型,不能作为集合的元素出现。
Python编译器中界定固定数据类型与否主要考察类型是否能够进行hash运算,能够进行hash运算的类型都可以作为集合元素。Python提供了一种同名的具体数据类型——集合(set)。
hash运算可以将任意长度的二进制值映射为较短的固定长度的二进制值,称谓哈希值。哈希值对数据的一种有损且紧凑的表示形式。Python提供了一个内置的哈希运算函数hash(),它可以对大多数数据类型产生一个hash值。
print(hash("PYTHON")) # -8040420733345289521
print(hash("ZYZMZM")) # 579977139141966686
这些哈希值与哈希前的内容无关,也和这些内容的组合无关。可以说,hash是数据在另一个数据维度的体现。
集合的常用操作与方法
由于集合是无序组合,它没有索引和位置的概念,不能分片,集合中元素可以动态增加或删除。集合用大括号 { } 表示,可以用赋值语句生成一个集合:
s = {1200, "zyzmzm", "24w+", ("blog", 2)}
print(s)
# {1200, '24w+', ('blog', 2), 'zyzmzm'}
从上述程序的运行结果可以看出,由于集合元素是无序的,集合的打印效果与定义顺序可以不一致。由于集合元素独一无二,使用集合类型能够过滤掉重复元素。
set(x)函数可以用于生成集合,输入的参数可以使任何组合数据类型,返回的结果是一个无重复且排序任意的集合:
w = set("zyzmzm")
print(w) # {'y', 'm', 'z'}
v = set(("cat","dog","tiger","human"))
print(v) # {'human', 'cat', 'tiger', 'dog'}
集合类型有10个操作符:
| 操 作 符 | 描 述 |
|---|---|
| S - T 或 S.difference(T) | 返回一个新集合,包括在集合S中但不在集合T中的元素 |
| S -= T 或 S.difference_update(T) | 更新集合S,包括在集合S中但不在集合T中的元素 |
| S & T 或 S.intersection(T) | 返回一个新集合,包括同时在集合S和T中的元素 |
| S &= T 或 S.intersection_update(T) | 更新集合S,包括同时在集合S和T中的元素 |
| s ^ T 或 S.symmetric-difference(T) | 返回一个新集合,包括集合S和T中的元素,但不包括同时在其中的元素 |
| s =^ T 或 S.symmetric-difference_update(T) | 更新集合S,包括集合S和T中的元素,但不包括同时在其中的元素 |
| S | T 或 S.union(T) | 返回一个新集合,包括集合S和T中的所有元素 |
| S =| T 或 S.update(T) | 更新集合S,包括集合S和T中的所有元素 |
| S <= T 或 S.update(T) | 如果S和T相同或S是T的子集,返回True,否则返回False,可以用S>T判断S是否是T的真子集 |
| S >= T 或 S.issuperset(T) | 如果S和T相同或S是T的超集,返回True,否则返回False,可以用S>T判断S是否是T的真超集 |
上述操作符表达了集合的4种基本操作:交集(&)、并集(|)、差集(-)、补集(^),操作逻辑与数学定义相同。

集合类型有10个操作函数或方法,如下表所示:
| 操作函数或方法 | 描述 |
|---|---|
| S.add(x) | 如果数据项x不在集合s中,将x增加到s |
| S.clear(x) | 移除S中所有数据项 |
| S.copy() | 返回集合S的一个副本 |
| S.pop() | 随机返回集合S中的一个元素,如果S为空,产生KeyError异常 |
| S.discard(x) | 如果x在集合S中,移除该元素,如果x不在集合S中,不报错 |
| S.remove(x) | 如果x在集合S中,移除该元素,不在则产生KeyError异常 |
| S.isdisjoint(T) | 如果集合S与T没有相同元素,返回True |
| len(S) | 返回集合S元素个数 |
| x in S | 如果x是S的元素,返回True,否则返回False |
| x not in S | 如果x不是S的元素,返回True,否则返回False |
集合类型主要用于3个场景:成员关系测试、元素去重和删除数据项:
# 成员关系测试
print("BIT" in {"PYTHON","BIT",123,"GOOD"}) # True
# 元素去重
tup = {"PYTHON","BIT",123,"GOOD",123}
print(set(tup)) # {123, 'GOOD', 'PYTHON', 'BIT'}
# 去重同时删除重复项
newtup = tuple(set(tup)-{"PYTHON"})
print(newtup) # (123, 'GOOD', 'BIT')
集合类型与其他类型最大的不同在于它不包含重复元素,因此,当需要对一维数据进行去重或进行数据重复处理时,一般通过集合来完成。
序列类型
所谓序列,指的是一种包含多项数据的结构,序列包含的多个数据项(也叫成员)按顺序排列,可通过索引来访问成员。
Python 的常见序列类型包括字符串、列表和元组。之前我们介绍过的字符串,其实就是一种常见的序列,通过索引访问字符串内的字符程序就是序列的示范程序。
本篇博文我们所讲解的序列主要是指列表和元组,这两种类型看起来非常相似,最主要的区别在于:元组是不可变的,元组一旦构建出来,程序就不能修改元组所包含的成员(就像字符串也是不可变的,程序无法修改字符串所包含的字符序列);但列表是可变的,程序可以修改列表所包含的元素。
在具体的编程过程中,如果只是固定地保存多个数据项,则不需要修改它们,此时就应该使用元组;反之,就应该使用列表。此外,在某些时候,程序需要使用不可变的对象,比如 Python 要求字典的 key 必须是不可变的,此时程序就只能使用元组。
列表和元组的关系就是可变和不可变的关系。
创建列表和元组
创建列表和元组的语法也有点相似,区别只是创建列表使用方括号,创建元组使用圆括号,并在括号中列出元组的元素,元素之间以英文逗号隔开。
- 创建列表的语法格式如下:[ele1,ele2,ele3,…]
- 创建元组的语法格式如下:(ele1,ele2,ele3,…)
# 使用方括号定义列表
my_list = ['ZYZMZM', 21, 'Python']
print(my_list) # ['ZYZMZM', 21, 'Python']
# 使用圆括号定义元组
my_tuple = ('ZYZMZM', 21, 'Python')
print(my_tuple) # ('ZYZMZM', 21, 'Python')
列表和元组的通用方法
列表和元组非常相似,它们都可包含多个元素,多个元素也有各自的索引。程序可通过索引来操作这些元素,只要不涉及改变元素的操作,列表和元组的用法是通用的。
通过索引使用元素
列表和元组都可以使用索引来访问元素,包括正向递增索引和反向递减索引。列表的元素相当于一个变量,程序既可以使用它的值,也可对元素进行赋值;而元组的元素相当于一个常量,程序只能使用它的值,不能对它重新赋值。
a_tuple = ('ZYZMZM', 1200, 21, 'blog', -17)
print(a_tuple) # ('ZYZMZM', 1200, 21, 'blog', -17)
# 访问第1个元素
print(a_tuple[0]) # ZYZMZM
# 访问第2个元素
print(a_tuple[1]) # 1200
# 访问倒数第1个元素
print(a_tuple[-1]) # -17
# 访问倒数第2个元素
print(a_tuple[-2]) # blog
子序列
与我们之前介绍的字符串类似的是,列表和元组同样也可以使用索引获取中间一段,这种用法被称为slice(分片或切片)。slice的完整语法格式如下:[start: end: step]
上面语法中 start、end 两个索引值都可使用正数或负数,其中负数表示从倒数开始。该语法表示从 start 索引的元素开始(包含),到 end 索引的元素结束(不包含)的所有元素。step 表示步长,因此 step 使用负数没有意义。
a_tuple = ('ZYZMZM', 1200, 21, 'blog', -17)
# 访问从第2个到倒数第4个(不包含)所有元素
print(a_tuple[1: 3]) # (1200, 21)
# 访问从倒数第3个到倒数第1个(不包含)所有元素
print(a_tuple[-3: -1]) # (21, 'blog')
# 访问从第2个到倒数第2个(不包含)所有元素
print(a_tuple[1: -2]) # (1200, 21)
# 访问从倒数第3个到第5个(不包含)所有元素
print(a_tuple[-3: 4]) # (21, 'blog')
如果指定step参数,则可间隔step个元素再取元素:
b_tuple = (1, 2, 3, 4, 5, 6, 7, 8, 9)
# 访问从第3个到第9个(不包含)、间隔为2的所有元素
print(b_tuple[2: 8: 2]) # (3, 5, 7)
# 访问从第3个到第9个(不包含)、间隔为3的所有元素
print(b_tuple[2: 8: 3]) # (3, 6)
# 访问从第3个到倒数第2个(不包含)、间隔为3的所有元素
print(b_tuple[2: -2: 2]) # (3, 5, 7)
加法
列表和元组支持加法运算,加法的和就是两个列表或元组所包含的元素的总和。
需要指出的是,列表只能和列表相加;元组只能和元组相加;元组不能直接和列表相加。
a_tuple = ('ZYZMZM' , 21, -1.2)
b_tuple = (127, 'ZYZMZM', 'blog', 3.33)
# 计算元组相加
sum_tuple = a_tuple + b_tuple
print(sum_tuple) # ('ZYZMZM', 21, -1.2, 127, 'ZYZMZM', 'blog', 3.33)
print(a_tuple) # a_tuple并没有改变
print(b_tuple) # b_tuple并没有改变
# 两个元组相加
print(a_tuple + (-20 , -30)) # ('ZYZMZM', 21, -1.2, -20, -30)
# 下面代码报错:元组和列表不能直接相加
#print(a_tuple + [-20 , -30])
a_list = [20, 30, 50, 100]
b_list = ['a', 'b', 'c']
# 计算列表相加
sum_list = a_list + b_list
print(sum_list) # [20, 30, 50, 100, 'a', 'b', 'c']
print(a_list + ['blog']) # [20, 30, 50, 100, 'blog']
乘法
列表和元组可以和整数执行乘法运算,列表和元组乘法的意义就是把它们包含的元素重复 N 次,N就是被乘的倍数。
a_tuple = ('ZYZMZM' , 21)
# 执行乘法
mul_tuple = a_tuple * 3
print(mul_tuple) # ('ZYZMZM', 21, 'ZYZMZM', 21, 'ZYZMZM', 21)
a_list = [30, 'Python', 2]
mul_list = a_list * 3
print(mul_list) # [30, 'Python', 2, 30, 'Python', 2, 30, 'Python', 2]
当然,也可以对列表、元组同时进行加法、乘法运算。例如,把用户输入的日期翻译成英文表示形式,即添加英文的“第”后缀。对于 1、2、3 来说,英文的“第”后缀分别用 st、nd、rd 代表,其他则使用 th 代表。
# 同时对元组使用加法、乘法
order_endings = ('st', 'nd', 'rd')\
+ ('th',) * 17 + ('st', 'nd', 'rd')\
+ ('th',) * 7 + ('st',)
# 将会看到 st、nd、rd、17个th、st、nd、rd、7个th、st
# print(order_endings)
while True:
day = input("输入日期(1-31):")
if day == "-1":
break
# 将字符串转成整数
day_int = int(day)
print(day + order_endings[day_int - 1])
运行结果:
输入日期(1-31):1
1st
输入日期(1-31):2
2nd
输入日期(1-31):3
3rd
输入日期(1-31):27
27th
注意:(‘th’) 只是字符串加上圆括号,并不是元组,也就是说,(‘th’) 和 ‘th’ 是相同的。为了表示只有一个元素的元组,必须在唯一的元组元素之后添加英文逗号。
in运算符
in 运算符用于判断列表或元组是否包含某个元素:
a_tuple = ('ZYZMZM' , 21, -1.2)
print(21 in a_tuple) # True
print(1.2 in a_tuple) # False
print('blog' not in a_tuple) # True
长度、最大值和最小值
Python 提供了内置的len()、max()、min()全局函数来获取元组或列表的长度、最大值和最小值。由于 max()、min() 要对元组、列表中的元素比较大小,因此程序要求传给 max()、min() 函数的元组、列表的元素必须是相同类型且可以比较大小。
# 元素都是数值的元组
a_tuple = (20, 10, -2, 15.2, 102, 50)
# 计算最大值
print(max(a_tuple)) # 102
# 计算最小值
print(min(a_tuple)) # -2
# 计算长度
print(len(a_tuple)) # 6
# 元素都是字符串的列表
b_list = ['ZYZMZM', 'blog', 'Python', 'csdn']
# 计算最大值(依次比较每个字符的ASCII码值,
# 先比较第一个字符,若相同,继续比较第二个
# 字符,以此类推)
print(max(b_list)) # csdn(26个小写字母的ASCII码为97~122)
# 计算最小值
print(min(b_list)) # Python (26个大写字母的ASCII码为65~90)
# 计算长度
print(len(b_list)) # 4
序列封包与序列解包
Python 还提供了序列封包(Sequence Packing)和序列解包(Sequence Unpacking)的功能。简单来说,Python 允许支持以下两种赋值方式:
- 程序把多个值赋给一个变量时,Python 会自动将多个值封装成元组。这种功能被称为序列封包。
- 程序允许将序列(元组或列表等)直接赋值给多个变量,此时序列的各元素会被依次赋值给每个变量(要求序列的元素个数和变量个数相等)。这种功能被称为序列解包。
# 序列封包:将10、20、30封装成元组后赋值给vals
vals = 10, 20, 30
print(vals) # (10, 20, 30)
print(type(vals)) # <class 'tuple'>
print(vals[1]) # 20
a_tuple = tuple(range(1, 10, 2))
# 序列解包: 将a_tuple元组的各元素依次赋值给a、b、c、d、e变量
a, b, c, d, e = a_tuple
print(a, b, c, d, e) # 1 3 5 7 9
a_list = ['blog', 'ZYZMZM']
# 序列解包: 将a_list序列的各元素依次赋值给a_str、b_str变量
a_str, b_str = a_list
print(a_str, b_str) # blog ZYZMZM
如果在赋值中同时运用序列封包和序列解包机制,就可以让赋值运算符支持同时将多个值赋给多个变量。使用这种语法也可以实现交换变量的值。
# 将10、20、30依次赋值给x、y、z
x, y, z = 10, 20, 30
print(x, y, z) # 10 20 30
# 将y,z, x依次赋值给x、y、z
x, y, z = y, z, x
print(x, y, z) # 20 30 10
在序列解包时也可以只解出部分变量,剩下的依然使用列表变量保存。为了使用这种解包方式,Python 允许在左边被赋值的变量之前添加“*”,那么该变量就代表一个列表,可以保存多个集合元素。
# first、second保存前2个元素,rest列表包含剩下的元素
first, second, *rest = range(10)
print(first) # 0
print(second) # 1
print(rest) # [2, 3, 4, 5, 6, 7, 8, 9]
# last保存最后一个元素,begin保存前面剩下的元素
*begin, last = range(10)
print(begin) # [0, 1, 2, 3, 4, 5, 6, 7, 8]
print(last) # 9
# first保存第一个元素,last保存最后一个元素,middle保存中间剩下的元素
first, *middle, last = range(10)
print(first) # 0
print(middle) # [0, 1, 2, 3, 4, 5, 6, 7, 8]
print(last) # 9
列表的常用方法
之前我们已经提到,列表和元组最大的区别就在于:元组是不可变的,列表是可变的。元组支持的操作,列表基本上都支持。列表支持对元素的修改,而元组这不支持。从这个角度看,可以认为列表是增强版的元组。
创建列表
除了使用前面介绍的方括号语法创建列表之外,Python语言还提供了一个内置的list()函数创建列表,list()函数可用于将元组、区间(range)等对象转换为列表。
a_tuple = ('zyzmzm', 21, -1.2)
# 将元组转换成列表
a_list = list(a_tuple)
print(a_list) # ['zyzmzm', 21, -1.2]
# 使用range()函数创建区间(range)对象
a_range = range(1, 5)
print(a_range) # range(1, 5)
# 将区间转换成列表
b_list = list(a_range)
print(b_list) #[1, 2, 3, 4]
# 创建区间时还指定步长
c_list = list(range(4, 20, 3))
print(c_list) # [4, 7, 10, 13, 16, 19]
与list()对应的是,Python也提供了一个tuple()函数,该函数可用于将列表、区间(range)等对象转换为元组。
a_list = ['zyzmzm', 21, -1.2]
# 将列表转换成元组
a_tuple = tuple(a_list)
print(a_tuple) # ('zyzmzm', 21, -1.2)
# 使用range()函数创建区间(range)对象
a_range = range(1, 5)
print(a_range) # range(1, 5)
# 将区间转换成元组
b_tuple = tuple(a_range)
print(b_tuple) # (1, 2, 3, 4)
# 创建区间时还指定步长
c_tuple = tuple(range(4, 20, 3))
print(c_tuple) # (4, 7, 10, 13, 16, 19)
增加列表元素
为列表增加元素可以调用列表的append()方法,该方法会把传入的参数追加到列表的最后面。
append()方法既可以接收单个值,也可接收元组、列表等,但该方法只是把元组、列表当成单个元素,这样就会形成在列表中嵌套列表、嵌套元组的情形。
a_list = ['zyzmzm', 21, -2]
# 追加元素
a_list.append('blog')
print(a_list) # ['zyzmzm', 21, -2, 'blog']
a_tuple = (3.4, 5.6)
# 追加元组,元组被当成一个元素
a_list.append(a_tuple)
print(a_list) # ['zyzmzm', 21, -2, 'blog', (3.4, 5.6)]
# 追加列表,列表被当成一个元素
a_list.append(['a', 'b'])
print(a_list) # ['zyzmzm', 21, -2, 'blog', (3.4, 5.6), ['a', 'b']]
从上述结果可以看出,当列表追加另一个列表时,Python会将被追加的列表当成一个整体的元素,而不是追加目标列表中的元素。如果希望被追加的列表不当成一个整体,而只是追加列表中的元素,则可使用列表的extend()方法。
b_list = ['a', 30]
# 追加元组中的所有元素
b_list.extend((-2, 3.1))
print(b_list) # ['a', 30, -2, 3.1]
# 追加列表中的所有元素
b_list.extend(['C', 'R', 'A'])
print(b_list) # ['a', 30, -2, 3.1, 'C', 'R', 'A']
# 追加区间中的所有元素
b_list.extend(range(97, 100))
print(b_list) # ['a', 30, -2, 3.1, 'C', 'R', 'A', 97, 98, 99]
此外,如果希望在列表中间增加元素,则可使用列表的insert()方法,使用insert()方法时要指定将元素插入列表的哪个位置上:
c_list = list(range(1, 6))
print(c_list) # [1, 2, 3, 4, 5]
# 在索引3处插入字符串
c_list.insert(3, 'ZYZMZM' )
print(c_list) # [1, 2, 3, 'ZYZMZM', 4, 5]
# 在索引3处插入元组,元组被当成一个元素
c_list.insert(3, tuple('zyzmzm'))
print(c_list) # [1, 2, 3, ('z', 'y', 'z', 'm', 'z', 'm'), 'ZYZMZM', 4, 5]
删除列表元素
删除列表元素使用del语句。del语句是Python的一种语句,专门用于执行删除操作,不仅可用于删除列表的元素,也可用于删除变量等。
使用del语句即可删除列表中的单个元素,也可直接删除列表的中间一段。
a_list = ['zyzmzm', 21, -2.4, (3, 4), 'blog']
# 删除第3个元素
del a_list[2]
print(a_list) # ['zyzmzm', 21, (3, 4), 'blog']
# 删除第2个到第4个(不包含)元素
del a_list[1: 3]
print(a_list) # ['zyzmzm', 'blog']
b_list = list(range(1, 10))
# 删除第3个到倒数第2个(不包含)元素,间隔为2
del b_list[2: -2: 2]
print(b_list) # [1, 2, 4, 6, 8, 9]
# 删除第3个到第5个(不包含)元素
del b_list[2: 4]
print(b_list) # [1, 2, 8, 9]
使用del语句不仅可以删除列表元素,也可以删除普通变量:
name = 'zyzmzm'
print(name) # zyzmzm
# 删除name变量
del name
#print(name) # NameError
除了使用del语句之外,Python还提供了remove()方法来删除列表元素,该方法并不是根据索引来删除元素的,而是根据元素本身来执行删除操作的。该方法只删除第一个找到的元素,如果找不到,该方法会引发ValueError错误。
c_list = [21, 'zyzmzm', 30, -4, 'zyzmzm', 3.4]
# 删除第一次找到的30
c_list.remove(30)
print(c_list) # [21, 'zyzmzm', -4, 'zyzmzm', 3.4]
# 删除第一次找到的'zyzmzm'
c_list.remove('zyzmzm')
print(c_list) # [21, -4, 'zyzmzm', 3.4]
列表还包含一个clear()方法,该方法用于清空列表的所有元素:
c_list.clear()
print(c_list) # []
修改列表元素
列表的元素相当于变量,因此程序可以对列表的元素赋值,这样便可以修改列表的元素。
a_list = [2, 4, -3.4, 'zyzmzm', 21]
# 对第3个元素赋值
a_list[2] = 'blog'
print(a_list) # [2, 4, 'blog', 'zyzmzm', 21]
# 对倒数第2个元素赋值
a_list[-2] = 1027
print(a_list) # [2, 4, 'blog', 1027, 21]
此外,程序也可以通过slice()语法对列表其中一部分赋值,在执行这个操作时并不要求新赋值的元素个数与原来的元素个数相等。
b_list = list(range(1, 5))
print(b_list)
# 将第2个到第4个(不包含)元素赋值为新列表的元素
b_list[1: 3] = ['a', 'b']
print(b_list) # [1, 'a', 'b', 4]
如果对列表中空的slice赋值,就变成了为列表插入元素:
# 将第3个到第3个(不包含)元素赋值为新列表的元素,就是插入
b_list[2: 2] = ['x', 'y']
print(b_list) # [1, 'a', 'x', 'y', 'b', 4]
如果将列表其中一段赋值为空列表,就变成了从列表中删除元素。
# 将第3个到第6个(不包含)元素赋值为空列表,就是删除
b_list[2: 5] = []
print(b_list) # [1, 'a', 4]
对列表使用slice语法赋值时,不能使用单个值;如果使用字符串赋值,Python会自动把字符串当成序列处理,其中每个字符都是一个元素。
# Python会自动将str分解成序列
b_list[1: 3] = 'ZYZMZM'
print(b_list) # [1, 'Z', 'Y', 'Z', 'M', 'Z', 'M']
在使用slice语法赋值时,也可指定step参数。但是如果指定了step参数,则要求所赋值的列表元素个数与所替换的列表元素个数相等。
c_list = list(range(1, 10))
# 指定step为2,被赋值的元素有4个,因此用于赋值的列表也必须有4个元素
c_list[2: 9: 2] = ['a', 'b', 'c', 'd']
print(c_list) # [1, 2, 'a', 4, 'b', 6, 'c', 8, 'd']
列表的其他常用方法
除了我们上述介绍的增加元素、删除元素、修改元素方法之外,列表还包含了一些常用的方法。列表还包含如下常用方法可以使用:
- count():用于统计列表中某个元素出现的次数
- index():用于判断某个元素在列表中出现的位置
- pop():用于将列表当成“栈”使用,实现元素出栈功能
- reverse():用于将列表中的元素反向存放
- sort():用于对列表元素排序。
count()方法的示例代码如下:
a_list = [2, 30, 'a', [5, 30], 30]
# 计算列表中30的出现次数
print(a_list.count(30)) # 2
# 计算列表中[5, 30]的出现次数
print(a_list.count([5, 30])) # 1
index()方法用于定位某个元素在列表中出现的位置,如果该元素没有出现,则会引发ValueError错误。在使用index()方法时还可以传入start、end参数,用于在列表的指定范围内搜索元素。
a_list = [2, 30, 'a', 'b', 'crazyit', 30]
# 定位元素30的出现位置
print(a_list.index(30)) # 1
# 从索引2处开始、定位元素30的出现位置
print(a_list.index(30, 2)) # 5
# 从索引2处到索引4处之间定位元素30的出现位置,找不到该元素
print(a_list.index(30, 2, 4)) # ValueError
pop()方法用于实现元素出栈功能。栈是一种特殊的数据结构,它可以实现先入后出(FILO)功能。
stack = []
# 向栈中“入栈”3个元素
stack.append("blog")
stack.append("zhaoyang")
stack.append("ZYZMZM")
print(stack) # ['blog', 'zhaoyang', 'ZYZMZM']
# 第一次出栈:最后入栈的元素被移出栈
print(stack.pop()) # ZYZMZM
print(stack) # ['blog', 'zhaoyang']
# 再次出栈
print(stack.pop()) # zhaoyang
print(stack) # ['blog']
resverse()方法将列表中所有元素的顺序反转。
a_list = list(range(1, 8))
# 将a_list列表元素反转
a_list.reverse()
print(a_list) # [7, 6, 5, 4, 3, 2, 1]
sort()方法用于对列表元素进行排序。
a_list = [3, 4, -2, -30, 14, 9.3, 3.4]
# 对列表元素排序
a_list.sort()
print(a_list) # [-30, -2, 3, 3.4, 4, 9.3, 14]
b_list = ['Python', 'Swift', 'Ruby', 'Go', 'C++', 'Java']
# 对列表元素排序:默认按字符串包含的字符的编码大小比较
b_list.sort()
print(b_list) # ['C++', 'Go', 'Java', 'Python', 'Ruby', 'Swift']
sort()方法除支持默认排序之外,还可传入key和reverse两个参数,而且这两个参数必须通过参数名指定(这种参数叫关键字参数)。key参数用于为每个元素都生成一个比较大小的“键”;reverse参数则用于执行是否需要反转排序——默认是从小到大排序;如果该参数设置为True,将会改为从大到小排序:
# 指定key为len,指定使用len函数对集合元素生成比较的键,
# 也就是按字符串的长度比较大小
b_list.sort(key=len)
print(b_list) # ['Go', 'C++', 'Java', 'Ruby', 'Swift', 'Python']
# 指定反向排序
b_list.sort(key=len, reverse=True)
print(b_list) # ['Python', 'Swift', 'Java', 'Ruby', 'C++', 'Go']
映射类型
字典及其相关操作
字典也是Python提供的一种常用的数据结构,它用于存放具有映射关系的数据。
字典相当于保存了两组数据,其中一组数据是关键数据,被称为key;另一组数据可通过key来访问,被称为value。由于字典中的key是非常关键的数据,而且程序需要通过key来访问value,因此字典中的key不允许重复。
创建字典
程序即可以使用花括号语法来创建字典,也可以使用函数dict()函数来创建字典。实际上,dict是一种类型,它就是Python中的字典类型。
在使用花括号语法创建字典时,花括号中应包含多个key-value对,key与value之间用英文冒号隔开;多个key-value对之间用英文逗号隔开。
scores = {'语文': 89, '数学': 92, '英语': 93}
print(scores)
# 空的花括号代表空的dict
empty_dict = {}
print(empty_dict)
# 使用元组作为dict的key
dict2 = {(20, 30):'good', 30:'bad'}
需要指出的是,元组可以作为dict的key,但列表不能作为元组的key。这是由于dict要求key必须是不可变类型,但是列表是可变类型,因此列表不能作为元组的key。
使用dict()函数创建字典时,可以传入多个列表或元组参数作为key-value对,每个列表或元组将被当成一个key-value对,因此这些列表或元组都只能包含两个元素。
vegetables = [('celery', 1.58), ('brocoli', 1.29), ('lettuce', 2.19)]
# 创建包含3组key-value对的字典
dict3 = dict(vegetables)
print(dict3) # {'celery': 1.58, 'brocoli': 1.29, 'lettuce': 2.19}
cars = [['BMW', 8.5], ['BENS', 8.3], ['AUDI', 7.9]]
# 创建包含3组key-value对的字典
dict4 = dict(cars)
print(dict4) # {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
如果不为dict()函数传入任何参数创建字典,则代表创建一个空的字典;还可通过为dict()指定关键字参数创建字典,此时字典的key不允许使用表达式:
# 创建空的字典
dict5 = dict()
print(dict5) # {}
# 使用关键字参数来创建字典
dict6 = dict(spinach = 1.39, cabbage = 2.59)
print(dict6) # {'spinach': 1.39, 'cabbage': 2.59}
字典的基本用法
之前讲到,key是字典的关键数据,因此程序对字典的操作都是基于key的。
- 通过key访问value
- 通过key添加key-value对
- 通过key删除key-value对
- 通过key修改key-value对
- 通过key判断指定key-value对是否存在
scores = {'语文': 89}
# 通过key访问value
print(scores['语文'])
# 对不存在的key赋值,就是增加key-value对
scores['数学'] = 93
scores['英语'] = 57
print(scores) # {'语文': 89, '数学': 93, '英语': 57}
# 使用del语句删除key-value对
del scores['语文']
del scores['数学']
print(scores) # {'英语': 57}
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
# 对存在的key-value对赋值,改变key-value对
cars['BENS'] = 4.3
cars['AUDI'] = 3.8
print(cars) # {'BMW': 8.5, 'BENS': 4.3, 'AUDI': 3.8}
# 判断cars是否包含名为'AUDI'的key
print('AUDI' in cars) # True
# 判断cars是否包含名为'PORSCHE'的key
print('PORSCHE' in cars) # False
print('LAMBORGHINI' not in cars) # True
通过上面的介绍可以看出,字典的key是它的关键。换个角度看,字典的key就相当于它的索引,只不过这些索引不一定是整数类型,它可以是任意不可变类型。
可以这样说,字典相当于索引是任意不可变类型的列表;而列表则相当于key只能是整数的字典。如果程序中要使用的字典的key都是整数类型,则可以考虑转换成列表。
此外,列表的索引总是总0开始连续递增的,但是字典的索引即使是整数类型,也不强制从0开始,而且不需要连续。因此列表不允许对不存在的索引赋值,但是字典允许直接对不存在的key赋值,这样就会为字典增加一个key-value对。
字典的常用方法
下面介绍dict的一些方法:
clear()方法用于清空字典中所有的key-value对,对一个字典执行clear()方法之后,该字典就会变成空字典。
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
print(cars) # {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
# 清空cars所有key-value对
cars.clear()
print(cars) # {}
get()方法根据key来获取value,它相当于方括号的语法增强版——当时用方括号语法访问并不存在的key时,字典会引发KeyError错误;但如果使用get()方法访问不存在的key,该方法会简单地返回None,不会导致错误。
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
# 获取'BMW'对应的value
print(cars.get('BMW')) # 8.5
print(cars.get('PORSCHE')) # None
print(cars['PORSCHE']) # KeyError
update()方法可使用一个字典所包含的key-value对来更新已有的字典。在执行update()方法时,如果被更新的字典中已包含对应的key-value对,那么原value会被覆盖;如果更新的字典中不包含对应的key-value对,则该key-value对被添加进去。
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
cars.update({'BMW':4.5, 'PORSCHE': 9.3})
print(cars) # {'BMW': 4.5, 'BENS': 8.3, 'AUDI': 7.9, 'PORSCHE': 9.3}
items()、keys()、values()分别用于获取字典中的所有key-value对、所有key、所有value。这三个方法依次返回dict_items、dict_keys、dict_values对象,Python不希望用户直接操作这几个方法,但可通过list()函数把它们转换成列表。
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
# 获取字典所有的key-value对,返回一个dict_items对象
ims = cars.items()
print(type(ims)) # <class 'dict_items'>
# 将dict_items转换成列表
print(list(ims)) # [('BMW', 8.5), ('BENS', 8.3), ('AUDI', 7.9)]
# 访问第2个key-value对
print(list(ims)[1]) # ('BENS', 8.3)
# 获取字典所有的key,返回一个dict_keys对象
kys = cars.keys()
print(type(kys)) # <class 'dict_keys'>
# 将dict_keys转换成列表
print(list(kys)) # ['BMW', 'BENS', 'AUDI']
# 访问第2个key
print(list(kys)[1]) # 'BENS'
# 获取字典所有的value,返回一个dict_values对象
vals = cars.values()
# 将dict_values转换成列表
print(type(vals)) # [8.5, 8.3, 7.9]
# 访问第2个value
print(list(vals)[1]) # 8.3
pop()方法用于获取指定key所对应的value,并删除这个key-value对。
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
print(cars.pop('AUDI')) # 7.9
print(cars) # {'BMW': 8.5, 'BENS': 8.3}
popitem()方法用于随机弹出字典中的一个key-value对。其实这里说的是随机,其实是弹出底层存储的最后一个key-value对,但是字典存储key-value对的顺序是不可知的,所以达到了随机的效果。
cars = {'AUDI': 7.9, 'BENS': 8.3, 'BMW': 8.5}
print(cars)
# 弹出字典底层存储的最后一个key-value对
print(cars.popitem()) # ('AUDI', 7.9)
print(cars) # {'BMW': 8.5, 'BENS': 8.3}
# 将弹出项的key赋值给k、value赋值给v
k, v = cars.popitem()
print(k, v) # BENS 8.3
setdefault()方法也用于根据key来获取对应的value值,但是有一个额外的功能,就是当程序要获取的key在字典中不存在时,该方法会先为这个不存在key设置一个默认的value,然后再返回该key对应的value。
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
# 设置默认值,该key在dict中不存在,新增key-value对
print(cars.setdefault('PORSCHE', 9.2)) # 9.2
print(cars) # {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9, 'PORSCHE': 9.2}
# 设置默认值,该key在dict中存在,不会修改dict内容
print(cars.setdefault('BMW', 3.4)) # 8.5
print(cars) # {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9, 'PORSCHE': 9.2}
fromkeys()方法使用给定的多个key创建字典,这些key对应的value默认都是None,也可以额外传入一个参数作为默认的value。
# 使用列表创建包含2个key的字典
a_dict = dict.fromkeys(['a', 'b'])
print(a_dict) # {'a': None, 'b': None}
# 使用元组创建包含2个key的字典
b_dict = dict.fromkeys((13, 17))
print(b_dict) # {13: None, 17: None}
# 使用元组创建包含2个key的字典,指定默认的value
c_dict = dict.fromkeys((13, 17), 'good')
print(c_dict) # {13: 'good', 17: 'good'}
使用字典格式化字符串
之前我们介绍格式化字符串,如果要格式化的字符串模板包含多个变量,后面就需要按照顺序给出多个变量,这种方式对于字符串模板中包含少量变量的情形是合适的,但是如果字符串模板包含大量变量,这种按照顺序提供变量的方式则有些不合适。
可改为在字符串模板中按key指定变量,然后通过字典为字符串模板中的key设置值。
# 字符串模板中使用key
temp = '博客是:%(name)s, 专栏价格是:%(price)010.2f, 作者是:%(author)s'
book = {'name':'ZYZMZM', 'price': 99.99, 'author': 'zhaoyang'}
# 使用字典为字符串模板中的key传入值
print(temp % book) # 博客是:ZYZMZM, 专栏价格是:0000099.99, 作者是:zhaoyang
book = {'name':'ZYZMZM', 'price': 99.99, 'author': 'zhaoyang'}
# 使用字典为字符串模板中的key传入值
print(temp % book) # 博客是:ZYZMZM, 专栏价格是:0000099.99, 作者是:zhaoyang
