1.关于K折交叉验证
https://scikit-learn.org/stable/modules/cross_validation.html#k-fold 这里有好多好多种啊,我看了也根本记不住,所以只选择最简单的第一个来学习
2折交叉验证:
import numpy as np from sklearn.model_selection import KFold X = ["a", "b", "c", "d",'e','f','g']#当有7个元素时 kf = KFold(n_splits=2) for train, test in kf.split(X): print("%s %s" % (train, test))
分的结果是这样:
[4 5 6] [0 1 2 3] [0 1 2 3] [4 5 6] #有4个元素: [2 3] [0 1] [0 1] [2 3] #8个元素 [4 5 6 7] [0 1 2 3] [0 1 2 3] [4 5 6 7]
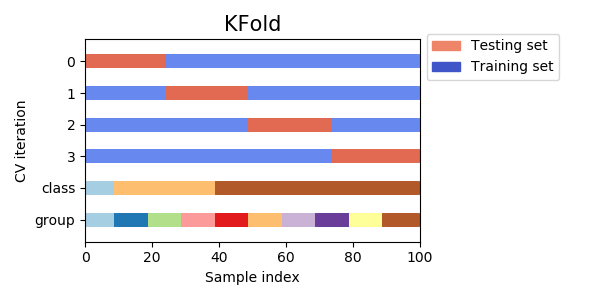
从上面的图片中就很好理解,如果是4折交叉验证的话,那么就是其中有一折,分别做测试和训练集。
但是有疑问的是,如果是在DL代码中,就需要每个epoch建立不同的Dataloader吗?因为需要对fullDataset做分割来形成Train和Test了。
import numpy as np from sklearn.model_selection import KFold X = np.array([[0., 0.], [1., 1.], [-1., -1.], [2., 2.]]) y = np.array([0, 1, 0, 1]) kf=KFold(n_splits=2) for train,test in kf.split(X): X_train, X_test, y_train, y_test = X[train], X[test], y[train], y[test] print(X_train, X_test, y_train, y_test) #下面又说到,它是直接根据下标就可以获取到训练和测试集,因为split的结果就是index
输出:
[[-1. -1.] [ 2. 2.]] [[0. 0.] [1. 1.]] [0 1] [0 1] [[0. 0.] [1. 1.]] [[-1. -1.] [ 2. 2.]] [0 1] [0 1]