9.4.5 非聚集索引建立的原则和方法-指针

非聚集索引是一种与存储在表中的数据相分离的索引结构,可对一个或多个选定列重新排序。 非聚集索引通常可帮助您通过比搜索基础表更快的速度查找数据;有时可以完全由非聚集索引中的数据回答查询,或非聚集索引可将 数据库引擎 指向基础表中的行。
一般来说,创建非聚集索引是为了提高聚集索引不涵盖的频繁使用的查询的性能,或在没有聚集索引的表(称为堆)中查找行。 可以对表或索引视图创建多个非聚集索引。
1 非聚集索引的体系结构
非聚集索引包含索引键值和指向表数据存储位置的行定位器。 可以对表或索引视图创建多个非聚集索引。 通常,设计非聚集索引是为改善经常使用的、没有建立聚集索引的查询的性能。
非聚集索引与聚集索引具有相同的 B 树结构,它们之间的显著差别在于以下两点:
基础表的数据行不按非聚集键的顺序排序和存储。
非聚集索引的叶级别是由索引页而不是由数据页组成。
非聚集索引行中的行定位器或是指向行的指针,或是行的聚集索引键,如下所述:
如果表是堆(意味着该表没有聚集索引),则行定位器是指向行的指针。 该指针由文件标识符 (ID)、页码和页上的行数生成。 整个指针称为行 ID (RID)。
如果表有聚集索引或索引视图上有聚集索引,则行定位器是行的聚集索引键。
2 非聚集索引设计原则
1 数据库注意事项
更新要求较低但包含大量数据的数据库或表可以从许多非聚集索引中获益从而改善查询性能。
联机事务处理 (OLTP) 应用程序和包含经常更新的表的数据库应避免过多索引。 此外,索引应该是窄的,即列越少越好。
2 查询注意事项
包含经常包含在查询的搜索条件(例如返回完全匹配的 WHERE 子句)中的列。
使用 JOIN 或 GROUP BY 子句。应为联接和分组操作中所涉及的列创建多个非聚集索引,为任何外键列创建一个聚集索引。
3 列注意事项
覆盖查询。
或者当索引包含查询中的所有列时,性能可以提升。 查询优化器可以找到索引内的所有列值;不会访问表或聚集索引数据,这样就减少了磁盘 I/O 操作。 使用具有包含列的索引来添加覆盖列,而不是创建宽索引键。
大量非重复值。如果只有很少的非重复值,例如仅有 1 和 0,则大多数查询将不使用索引,因为此时表扫描通常更有效。
3 带有包含列的索引 INCLUDE 非聚集索引
重新设计索引键大小较大的非聚集索引,以便只有用于搜索和查找的列为键列。 将覆盖查询的所有其他列设置为包含性非键列。 这样,将具有覆盖查询所需的所有列,但索引键本身较小,而且效率高。

4 如何创建非聚集
1 无索引
dbcc showcontig(L05TEST)
已执行 TABLE 级别的扫描。
- 扫描页数................................: 1789027
DBCC DROPCLEANBUFFERS
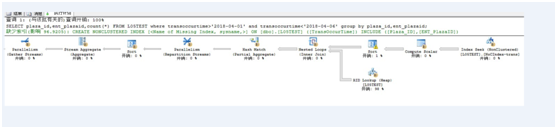
SELECT plaza_id,ent_plazaid,count(*) FROM L05TEST where transoccurtime>'2018-04-01' and transoccurtime<'2018-04-06' group by plaza_id,ent_plazaid;
表 'L05TEST'。扫描计数 3,逻辑读取 1789027 次,物理读取 0 次,预读 1789027 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间: CPU 时间 = 2624 毫秒,占用时间 = 108961 毫秒。
![]()
2 创建非聚集索引
CREATE NONCLUSTERED INDEX [NoCIndex-trans] ON [dbo].[L05TEST]
(
[TransOccurTime] ASC
)
DBCC DROPCLEANBUFFERS
dbcc showcontig(L05TEST) 只是扫描表用
- 扫描页数................................: 1789027
UPDATE STATISTICS L05TEST ---更新数据库大脑
DBCC DROPCLEANBUFFERS
SELECT plaza_id,ent_plazaid,count(*) FROM L05TEST where transoccurtime>'2018-04-01' and transoccurtime<'2018-04-06' group by plaza_id,ent_plazaid;
表 'L05TEST'。扫描计数 3,逻辑读取 359678 次,物理读取 2852 次,预读 13714 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间:
CPU 时间 = 296 毫秒,占用时间 = 4142 毫秒。
很牛逼的语句,查看是否有全表扫描
select db_name(database_id) as N't_branch', --库名
object_name(a.object_id) as N'TopProjectNew', --表明
b.name N'索引名称',
user_seeks ,
user_scans ,
user_lookups,
last_user_seek N'最后查找时间',
last_user_scan N'最后扫描时间',
rows as N'表中的行数'
from sys.dm_db_index_usage_stats a join
sys.indexes b
on a.index_id = b.index_id
and a.object_id = b.object_id
join sysindexes c
on c.id = b.object_id
where database_id=db_id('t_branch') ---改成要查看的数据库
and object_name(a.object_id) not like 'sys%' and object_name(a.object_id)='L05TEST'
order by user_seeks,user_scans,object_name(a.object_id)

2 创建非聚集索引-包含列
CREATE NONCLUSTERED INDEX [NonCIndex-trans-in] ON [dbo].[L05TEST]
(
[TransOccurTime] ASC
)
INCLUDE ( [Plaza_ID],
[ENT_PlazaID])
UPDATE STATISTICS L05TEST ---更新数据库大脑
DBCC DROPCLEANBUFFERS
SELECT plaza_id,ent_plazaid,count(*) FROM L05TEST where transoccurtime>'2018-04-01' and transoccurtime<'2018-04-06' group by plaza_id,ent_plazaid;
表 'L05TEST'。扫描计数 1,逻辑读取 1342 次,物理读取 4 次,预读 1338 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
SQL Server 执行时间:CPU 时间 = 62 毫秒,占用时间 = 459 毫秒。


