B树
相关概念
B树属于多叉树又名平衡多路查找树(查找路径不只两个)
数据库索引技术里大量使用者B树和B+树的数据结构,原因如下:
- 加快存储过程 ,mysql表中的数据和索引存储在磁盘这种外围设备中。但是和内存相比,从磁盘中读取数据的速度会慢上百倍千倍甚至万倍,所以,我们应当尽量减少从磁盘中读取数据的次数,采用B树查询的最坏时间复杂度为B的树高。
- 一次尽可能读取更多的数据,磁盘存储 和查询的最小单位为块(每个块的大小为4K),如果我们能把尽量多的关键字放进磁盘块中,一次磁盘读取操作就会读取更多关键字而且也充分利用了磁盘块的空间,压缩了树的层级,减少了数据查找次数和时间复杂度。(mysql中数据读取的基本单位为页,即上面所说的磁盘块)(一个关键字有一个键key和值value组成)
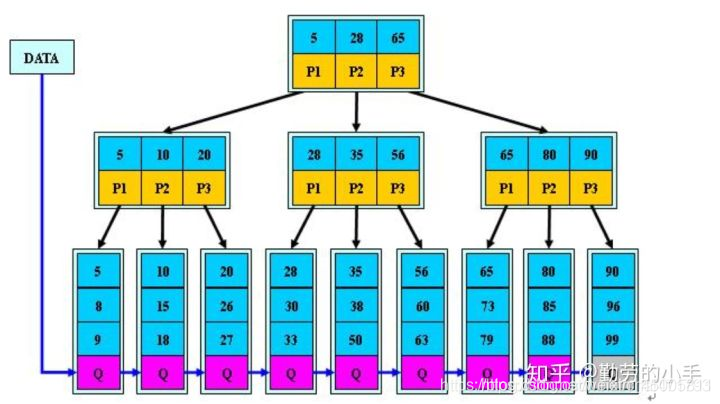
如下为一棵阶数为3的B树(每一页的子节点个数即为阶数)

B树构造特点如下:
- 排序方式:所有节点关键字是按递增次序排列,并遵循左小右大原则;
- 子节点数:M>=非叶节点的子节点数>1(M>=2),空树除外(注:M阶代表一个树节点最多有多少个查找路径,M=M路,当M=2则是2叉树,M=3则是3叉);
- 关键字数:M-1>=节点的关键字数>=ceil(m/2)-1个(注:ceil()是个朝正无穷方向取整的函数 如ceil(1.1)结果为2);
相关操作
查询
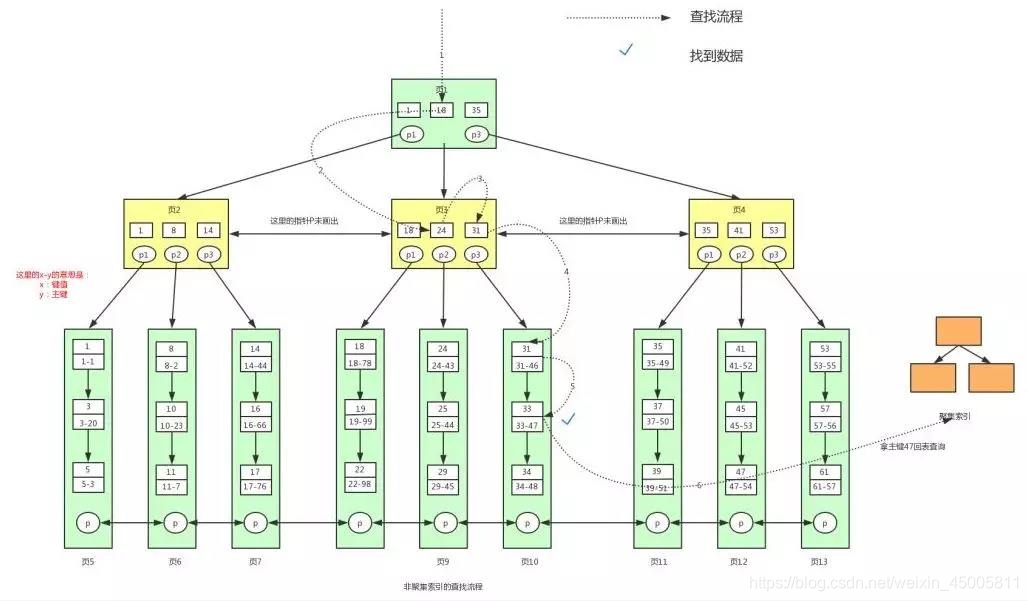
以上图为例,查询id=28 的用户信息,流程如下:
- 先找到根节点也就是页 1,判断 28 在键值 17 和 35 之间,那么我们根据页 1 中的指针 p2 找到页 3。
- 将 28 和页 3 中的键值相比较,28 在 26 和 30 之间,我们根据页 3 中的指针 p2 找到页 8。
- 将 28 和页 8 中的键值相比较,发现有匹配的键值 28,键值 28 对应的用户信息为(28,bv)。
插入
定义一个5阶树(平衡5路查找树;),现在我们要把3、8、31、11、23、29、50、28 这些数字构建出一个5阶树出来;
规则:
- 排序:满足节点本身比左边节点大,比右边节点小的排序规则;
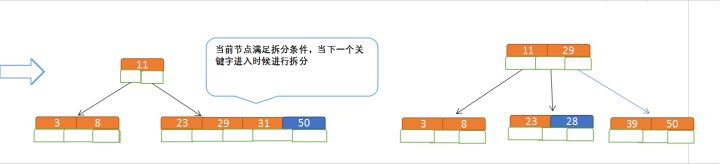
- 拆分:如果节点关键字个数大于限定范围,则需要进行拆分,即取出中间节点作为父节点,并连接两边作为左右节点
流程如下: - 先插入 3、8、31、11
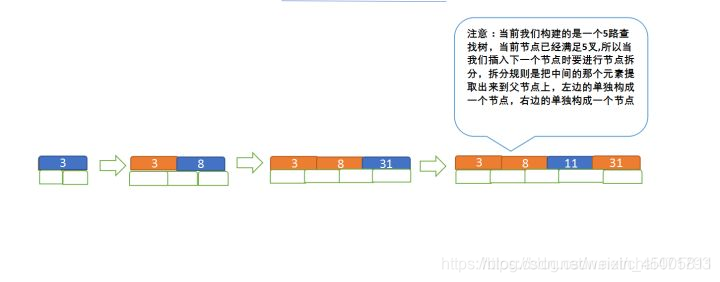
- 再插入23、29
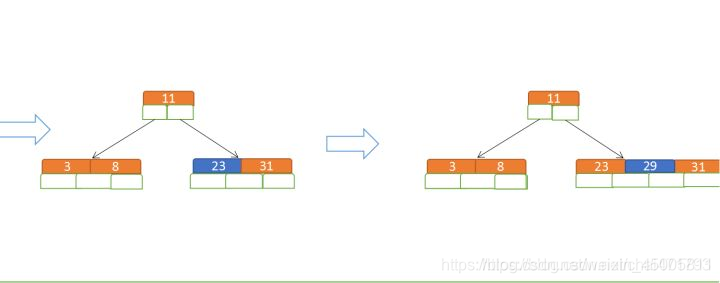
- 再插入50、28
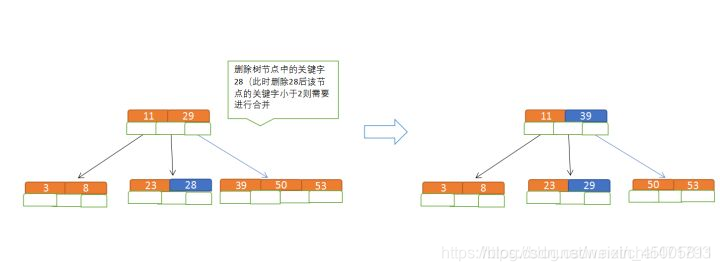
删除
已将3、8、31、11、23、29、50、28插入到平衡5路查找树中,此时需要删除28
规则:
- 排序:满足节点本身比左边节点大,比右边节点小的排序规则;
- 合并:如果节点关键字个数小于限定范围,则需要进行合并,先从子节点取,若子节点没有符合条件的就向父节点取
流程如下:
B+树
相关概念
B+树是B树的一个升级版,相对于B树来说B+树更充分的利用了节点的空间,让查询速度更加稳定,其速度完全接近于二分法查找。
对比B+树和B树的异同:
- B+树的非叶子节点不保存值value,只保存键key,这样使得B+树每个非叶子节点所能保存的数据大大增加;
- B+树叶子节点保存了值value,而且是利用单向链表按顺序连接了每一个数据,另外叶子节点之间使用双向链表连接,故B+ 树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。而 B 树因为数据分散在各个节点,要实现这一点是很不容易的。
索引即为数据,可以理解为树的节点
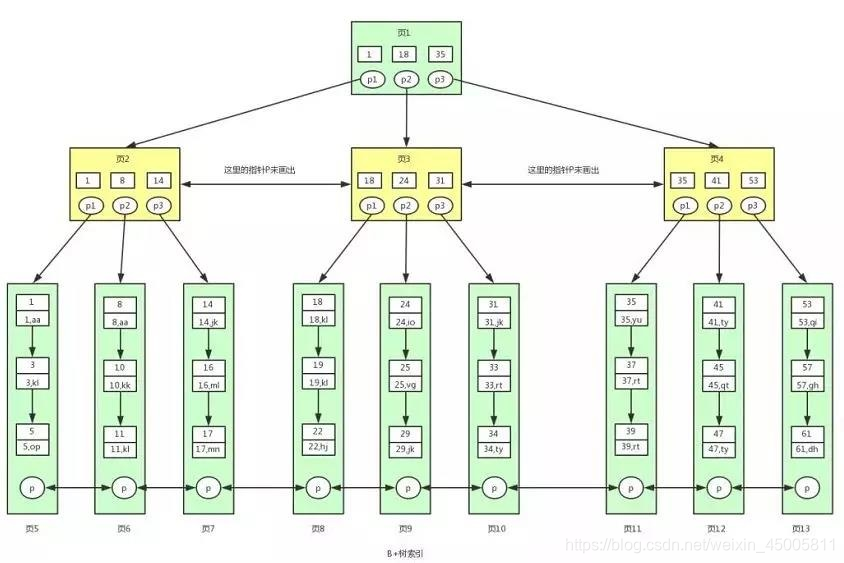
聚集索引
以InnoDB作为存储引擎为例,
B+树的非叶子节点存储的是主键,
B+树的叶子节点存储的是数据
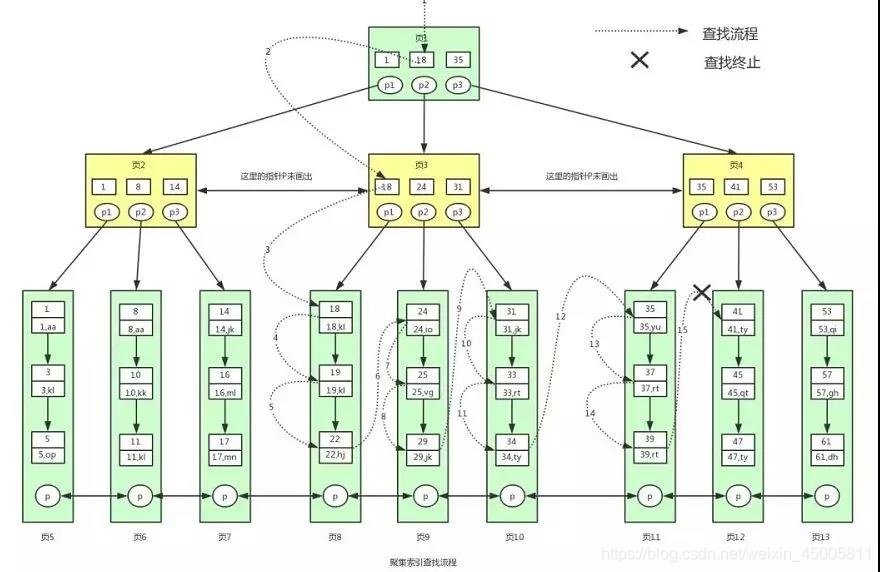
假定查询语句,其查询过程如下:
select * from user where id>=18 and id <40
- 一般根节点都是常驻内存的,也就是说页 1 已经在内存中了,此时不需要到磁盘中读取数据,直接从内存中读取即可。从页 1 中我们可以找到键值 18,此时我们需要根据指针 p2,定位到页 3。
- 从磁盘中读取页 3 后将页 3 放入内存中,然后进行查找,我们可以找到键值 18,然后再拿到页 3 中的指针 p1,定位到页 8。
- 将页 8 读取到内存中后。因为页中的数据是链表进行连接的,而且键值是按照顺序存放的,此时可以根据二分查找法定位到键值 18。
- 因为是范围查找,而且此时所有的数据又都存在叶子节点,并且是有序排列的,那么我们就可以对页 8 中的键值依次进行遍历查找并匹配满足条件的数据。我们可以一直找到键值为 22 的数据,然后页 8 中就没有数据了
- 此时我们需要拿着页 8 中的 p 指针去读取页 9 中的数据。因为页 9 不在内存中,就又会加载页 9 到内存中,并通过和页 8 中一样的方式进行数据的查找,直到将页 12 加载到内存中,发现 41 大于 40,此时不满足条件。那么查找到此终止。
非聚集索引
以InnoDB作为存储引擎为例,
B+树的非叶子节点存储的是主键以外的列值
B+树的叶子节点存储的是主键

假定查询语句,其查询过程如下:
select * from user where luckNum=33
- 根据主键以外的列值寻找到主键
- 利用主键值到聚集索引中查找具体对应的数据信息,这个步骤2也被称为回表