关于 TensorFlow
TensorFlow 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。
节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。
TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。
核心概念:数据流图
数据流图用“结点”(nodes)和“线”(edges)的有向图来描述数学计算。
“节点” 一般用来表示施加的数学操作,但也可以表示数据输入(feed in)的起点/输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点。
“线”表示“节点”之间的输入/输出关系。这些数据“线”可以输运“size可动态调整”的多维数据数组,即“张量”(tensor)。
张量从图中流过的直观图像是这个工具取名为“Tensorflow”的原因。一旦输入端的所有张量准备好,节点将被分配到各种计算设备完成异步并行地执行运算。
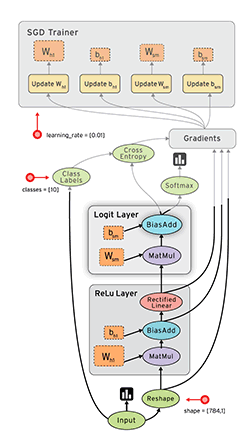
更详细的介绍可以查看tensorflow中文社区:http://www.tensorfly.cn/
TensorFlow主要是由计算图、张量以及模型会话三个部分组成。
计算图
在编写程序时,我们都是一步一步计算的,每计算完一步就可以得到一个执行结果。
在TensorFlow中,首先需要构建一个计算图,然后按照计算图启动一个会话,在会话中完成变量赋值,计算,得到最终结果等操作。
因此,可以说TensorFlow是一个按照计算图设计的逻辑进行计算的编程系统。
TensorFlow的计算图可以分为两个部分:
(1)构造部分,包含计算流图;(2)执行部分,通过session执行图中的计算。
构造部分又分为两部分:
(1)创建源节点;(2)源节点输出传递给其他节点做运算。
TensorFlow默认图:TensorFlow python库中有一个默认图(default graph)。节点构造器(op构造器)可以增加节点。
张量
在TensorFlow中,张量是对运算结果的引用,运算结果多以数组的形式存储,与numpy中数组不同的是张量还包含三个重要属性名字、维度、类型。
张量的名字,是张量的唯一标识符,通过名字可以发现张量是如何计算出来的。比如“add:0”代表的是计算节点"add"的第一个输出结果。维度和类型与数组类似。
模型会话
用来执行构造好的计算图,同时会话拥有和管理程序运行时的所有资源。
当计算完成之后,需要通过关闭会话来帮助系统回收资源。
在TensorFlow中使用会话有两种方式。第一种需要明确调用会话生成函数和关闭会话函数
import tensorflow as tf
# 创建session
session = tf.Session() #获取运算结果 session.run() #关闭会话,释放资源 session.close() 第二种可以使用with的方式
with tf.Session() as session:
session.run() 两种方式不同的是,第二种限制了session的作用域,即session这个参数只适用于with语句下面,同时语句结束后自动释放资源,
而第一种方式session则作用于整个程序文件,需要用close来释放资源。
tensorflow分布式原理
tensorflow的实现分为了单机实现和分布式实现。
单机的模式下,计算图会按照程序间的依赖关系顺序执行。
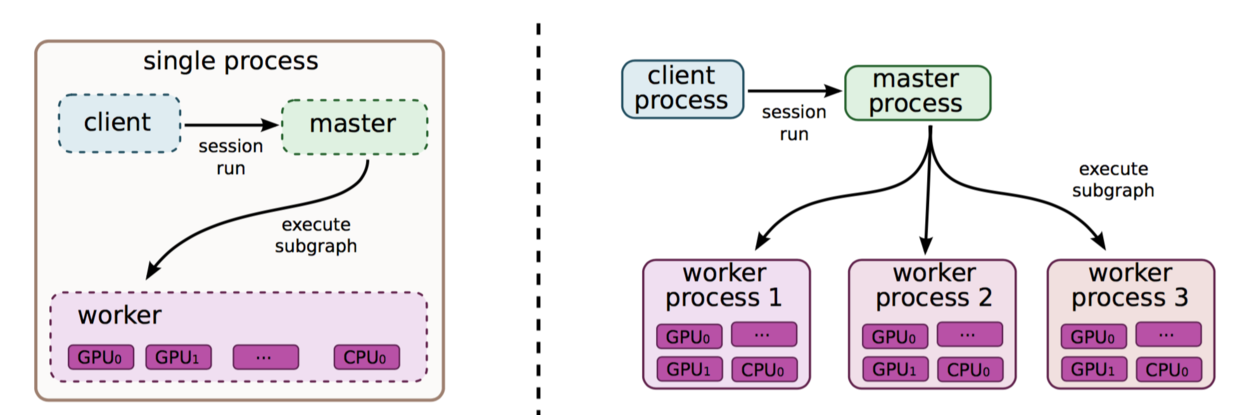
在分布式实现中,需要实现的是对client,master,worker process,device管理。
client也就是客户端,他通过session的接口与master和worker相连。
master则负责管理所有woker的计算图执行。
worker由一个或多个计算设备device组成,如cpu,gpu等。
具体过程如下图:
在分布式实现中,tensorflow有一套专门的节点分配策略。
策略是基于代价模型,代价模型会估算每个节点的输入,输出的tensor大小以及所需的计算时间,然后分配每个节点的计算设备。
扩展功能
在tensorflow中比较重要的拓展功能有,自动求导,子图执行,计算图控制流以及队列/容器
求导是机器学习中计算损失函数常用的运算,TensorFlow原生支持自动求导运算,它是通过计算图中的拓展节点实现。
子图执行是通过控制张量的流向实现。
计算图控制流:是指控制计算图的节点极其运行的设备管理,它提供了快速执行计算和满足设备施加的各种约束。比如限制内存总量为了执行它的图子集而在设备上所需的节点。
队列是一个有用的功能,它们允许图的不同部分异步执行,对数据进行入队和出队操作。
容器是用来存放变量,默认的容器是持久的,直到进程终止才会清空,同时容器中的变量也可以共享给其他计算图使用。
详细的细节可查看TensorFlow的介绍pdf
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45166.pdf
关于 TensorFlow
TensorFlow 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。
节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。
TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。
核心概念:数据流图
数据流图用“结点”(nodes)和“线”(edges)的有向图来描述数学计算。
“节点” 一般用来表示施加的数学操作,但也可以表示数据输入(feed in)的起点/输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点。
“线”表示“节点”之间的输入/输出关系。这些数据“线”可以输运“size可动态调整”的多维数据数组,即“张量”(tensor)。
张量从图中流过的直观图像是这个工具取名为“Tensorflow”的原因。一旦输入端的所有张量准备好,节点将被分配到各种计算设备完成异步并行地执行运算。
更详细的介绍可以查看tensorflow中文社区:http://www.tensorfly.cn/
TensorFlow主要是由计算图、张量以及模型会话三个部分组成。
计算图
在编写程序时,我们都是一步一步计算的,每计算完一步就可以得到一个执行结果。
在TensorFlow中,首先需要构建一个计算图,然后按照计算图启动一个会话,在会话中完成变量赋值,计算,得到最终结果等操作。
因此,可以说TensorFlow是一个按照计算图设计的逻辑进行计算的编程系统。
TensorFlow的计算图可以分为两个部分:
(1)构造部分,包含计算流图;(2)执行部分,通过session执行图中的计算。
构造部分又分为两部分:
(1)创建源节点;(2)源节点输出传递给其他节点做运算。
TensorFlow默认图:TensorFlow python库中有一个默认图(default graph)。节点构造器(op构造器)可以增加节点。
张量
在TensorFlow中,张量是对运算结果的引用,运算结果多以数组的形式存储,与numpy中数组不同的是张量还包含三个重要属性名字、维度、类型。
张量的名字,是张量的唯一标识符,通过名字可以发现张量是如何计算出来的。比如“add:0”代表的是计算节点"add"的第一个输出结果。维度和类型与数组类似。
模型会话
用来执行构造好的计算图,同时会话拥有和管理程序运行时的所有资源。
当计算完成之后,需要通过关闭会话来帮助系统回收资源。
在TensorFlow中使用会话有两种方式。第一种需要明确调用会话生成函数和关闭会话函数
import tensorflow as tf
# 创建session
session = tf.Session() #获取运算结果 session.run() #关闭会话,释放资源 session.close() 第二种可以使用with的方式
with tf.Session() as session:
session.run() 两种方式不同的是,第二种限制了session的作用域,即session这个参数只适用于with语句下面,同时语句结束后自动释放资源,
而第一种方式session则作用于整个程序文件,需要用close来释放资源。
tensorflow分布式原理
tensorflow的实现分为了单机实现和分布式实现。
单机的模式下,计算图会按照程序间的依赖关系顺序执行。
在分布式实现中,需要实现的是对client,master,worker process,device管理。
client也就是客户端,他通过session的接口与master和worker相连。
master则负责管理所有woker的计算图执行。
worker由一个或多个计算设备device组成,如cpu,gpu等。
具体过程如下图:
在分布式实现中,tensorflow有一套专门的节点分配策略。
策略是基于代价模型,代价模型会估算每个节点的输入,输出的tensor大小以及所需的计算时间,然后分配每个节点的计算设备。
扩展功能
在tensorflow中比较重要的拓展功能有,自动求导,子图执行,计算图控制流以及队列/容器
求导是机器学习中计算损失函数常用的运算,TensorFlow原生支持自动求导运算,它是通过计算图中的拓展节点实现。
子图执行是通过控制张量的流向实现。
计算图控制流:是指控制计算图的节点极其运行的设备管理,它提供了快速执行计算和满足设备施加的各种约束。比如限制内存总量为了执行它的图子集而在设备上所需的节点。
队列是一个有用的功能,它们允许图的不同部分异步执行,对数据进行入队和出队操作。
容器是用来存放变量,默认的容器是持久的,直到进程终止才会清空,同时容器中的变量也可以共享给其他计算图使用。
详细的细节可查看TensorFlow的介绍pdf
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45166.pdf