最近,老师给了一篇文章,说是还比较新奇,让看看,其实和我的研究方向不是非常吻合,但是疫情在家也无聊,就花了几天精看了下,写得还是不错的,内容也比较有意思,不过相对来说方法啥的比较简单,对于学习下写作和了解一个新方向还是不错的。
本文主要对《Quantifying privacy vulnerability of individual mobility traces:A case study of license plate recognition data》这篇文章进行下解读和介绍。
1.文章概述
文章主要是介绍了时空数据的隐私暴露与保护方面的内容。具体内容包括如下几点:
- k-anonymity and adversary model
- Factors affecting anonymity
- Two possible solutions
思路非常清晰,首先介绍k-anonymity model,说是model,其实是介绍下k-anonymity的概念,如何定量的描述数据的隐私保护的好坏。然后介绍下可能会影响隐私暴露风险大小的因素。最后提出两个算法来对时空数据的发布进行隐私保护。over。
2.k-anonymity and adversary model
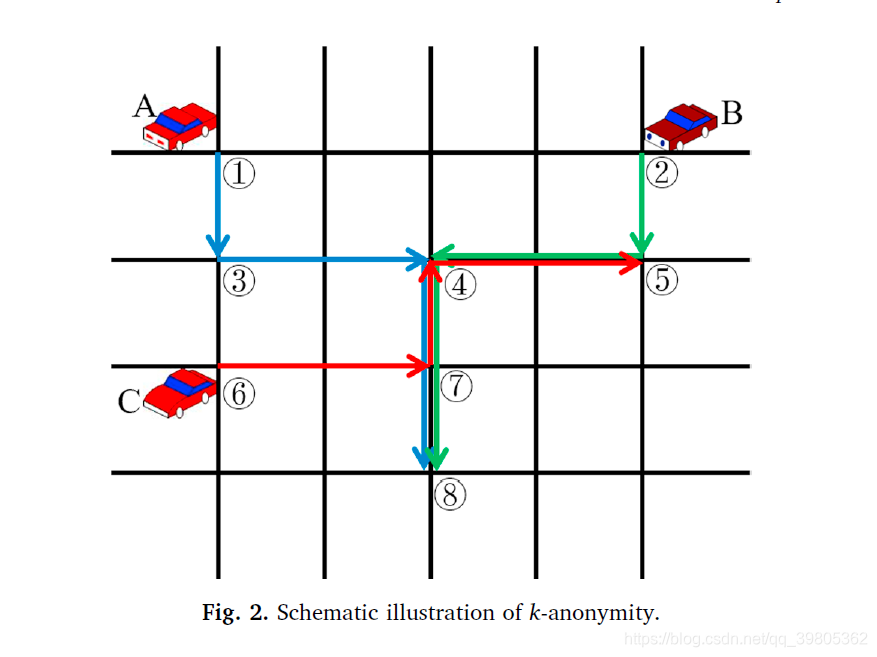
文章里当然说的非常复杂了,其实这个k-anonymity非常简单,非常容易理解,通俗来说,就是给定一批数据,本文都以车牌识别数据为例,给定数据的某一个record,至少有k辆车都有这个record的时空属性。也就是说,通过这个record,我们至少无法判断是k辆车的哪一辆。然后进一步又可以拓展,不光给定一个record,而是给定几个records,形成一个records set,通过这个records set无法判断至少是k辆车的哪一辆,这些用来标志的record或者是records set就是quasi-identifier(准标记符)。这就是k-anonymity and adversary model这个section的全部内容了。文章中给出了下面这个例子来说明。

3.Factors affecting anonymity
这一部分主要是阐述了那些会影响隐私暴露风险的因素。
3.1Temporal granularity
首先是时间粒度,怎么理解呢?raw LPR data 是精确到秒级别的,但是发布数据时,无须发布到这么精确的时间粒度,可以以5min,10min···1h,2h,6h···为时间单位做划分,然后发布这种粗时间粒度的数据,很容易知道时间粒度越粗糙,数据的时间信息越少,隐私保护就越强。文章中定量的做了下时间粒度对隐私保护的影响。结论和直观感觉肯定是一致,下图就是定量结果。

此外,这里必须要讲一下这个计算anonymity的算法。思想很简单,对于一个quasi-identifier遍历每辆车看这辆车中是否包含QI,是的话就把这辆车放到set里去就行。

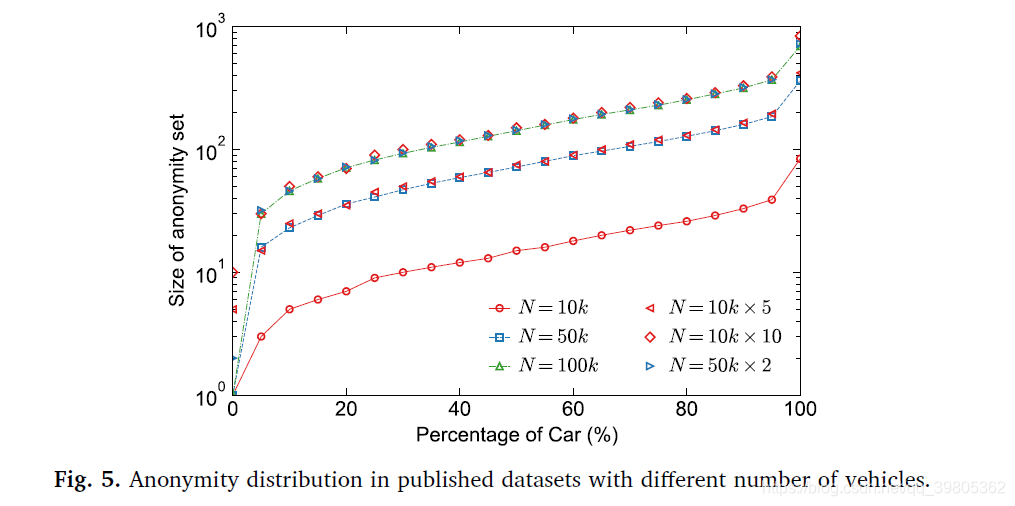
3.2Number of released vehicles
车辆数的多少对anonymity的影响,显然,车越多,anonymity越好。100个人里找一个人和1000个人里找一个人,当然1000个人里难找啦,也就是匿名性更好。
3.3Length of released time period
数据的时间跨度对anonymity影响不大,这个结论实际上与我们的直觉是不同的,首先看下result。

那么出现这种现象的原因是什么呢?作者做了进一步的实验,发现绝大多数人的出行行为是很稳定的,这就导致其实每一天人们不过是在做重复的行为,因此时间跨度长和短对匿名性的影响就不是很大了,因为2天的数据和1天的数据其实差不多,只不过是把1天的数据copy了一遍。
3.4Difference between local and non-local vehicles
本地车和外地车对anonymity的影响。这个分析也有点意思的。最后得到的结果是当取一个record作为QI时,本地车的匿名性比外地车好,当取多个record作为QI时,外地车的匿名性比本地车好。 看下结果。
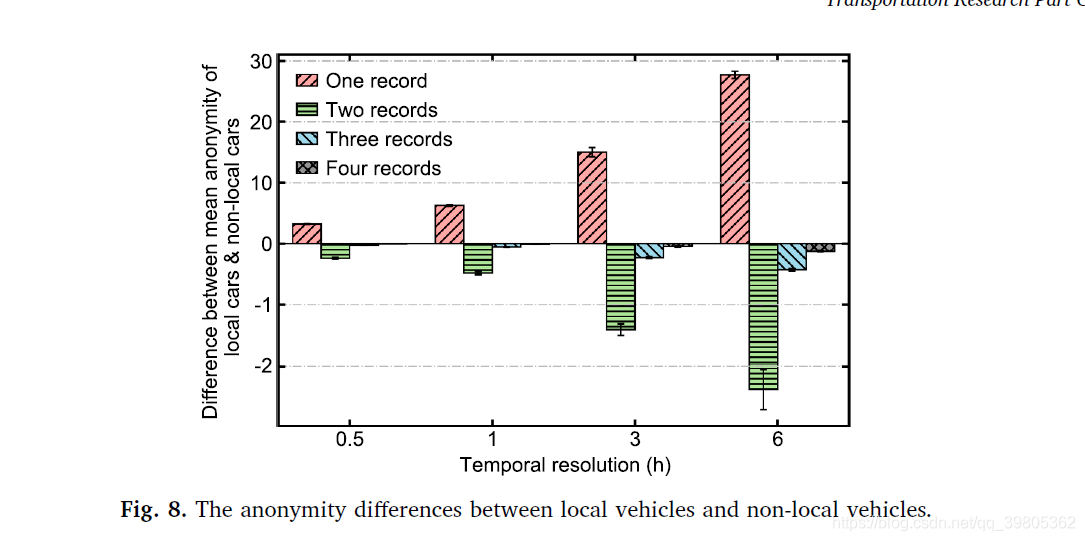
造成这种现象的原因是只用一个record作为QI时,实际上匿名性就是同一个卡口拍摄到的车辆数,这时本地的卡口显然会拍到更多的车辆,当然本地车辆的匿名性就好一些了。当用多个records作为QI时,此时外地车的隐私性就更好些了,因为外地车从外地进入广州,基本都是要经过同一个道路的,于是这个local behiviour就相当一致,因此anonymity外地车就高些了。
3.5Quasi-identifier using continuous records
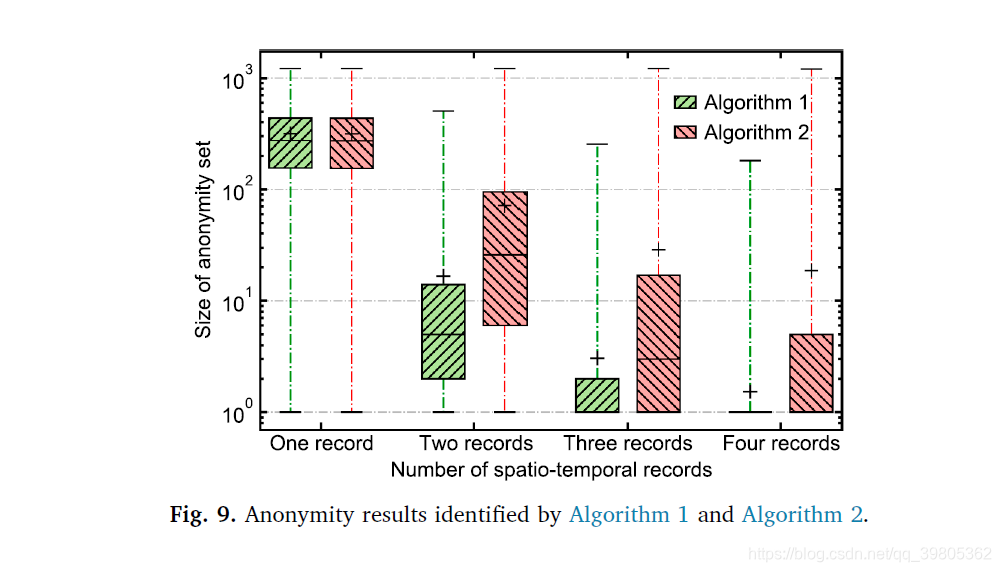
这个part是分析是否用连续的几个records作为QI对隐私性保护的影响。作者用下述算法来计算连续quasi-identifiers的anonymity的大小,和algorithm1基本一样,不过之前是不要求连续的records。

结果显示:连续性的records对隐私的保护会更好一点。这也很好理解,离散的records对行为的刻画显然会更多些,连续的records的话,一个pattern group里的vehicles行为基本一样,连续的records也是倾向于一样的,结果图如下:
4.Two possible solutions
4.1Suppression solution
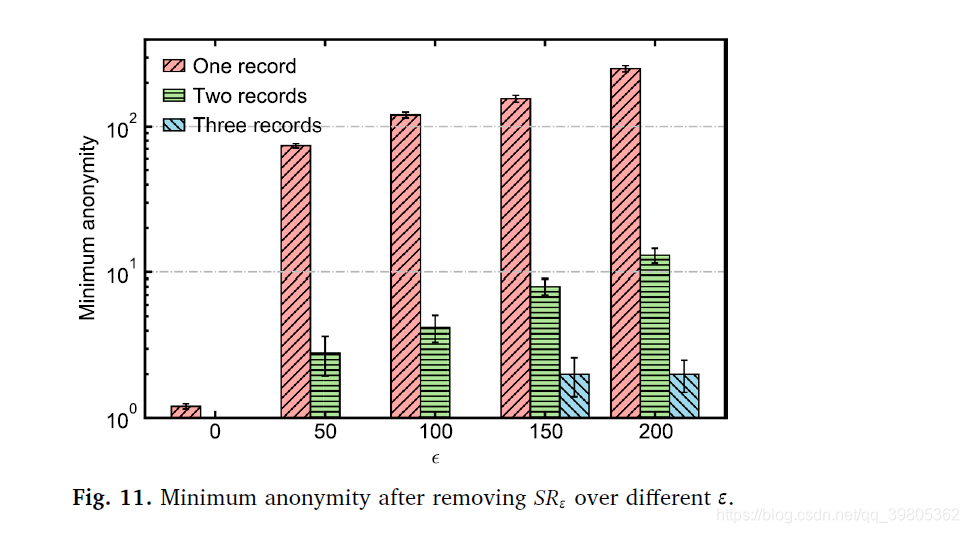
这种方法就非常简单直白了,把那些会导致很小的anonymity的records称为是sensitive records(SR),然后把SR全删掉就解决了。这样做显然可以提高anonymity.效果如下:(下面两张图的
指的是we define sensitive records as the record whose anonymity set is smaller than
and denote it as SR .)

4.2Generalization solution
作者提出的生成方案的算法如下所示,这种算法相对复杂些,但其实也很简单。本质上是一种综合权衡隐私保护和信息丢失的折中方法,由于权衡隐私保护和信息丢失是一种NP-HARD problem,因此每次都求出最优解是不可能的,只能采用下面这种方法。首先给出一个原始的时间划分方案,然后迭代改进这个时间划分方案,改进过程中要求anonymity满足大于
,并且在此基础上信息损失要尽可能少,最后生成一种新的时间粒度划分方式。

效果如下所示:下面这个图是作者提出的方法和uniform time interval cloaking method相比较的结果,红色的是作者的algorithm,这种方法并不是说隐私保护是最好的,而是在隐私保护和信息留存中得到一个相对比较好的解。下面这个图也说明了这点,所有数据的隐私性较为集中在[100-200],隐私性达到一定程度后便不在进一步提升,而是利用香农熵的概念着重保护信息的不丢失。

5.Conclusion
Overall, this paper reveals the high risk of privacy disclosure of LPR data from a quantitative point of view. We introduce possible solutions to provide privacy protection for agencies publishing/sharing mobility trace data and discuss the privacy-and-utility tradeoff when releasing such data sets.
参考文献
Gao, Jing, Lijun Sun, and Ming Cai. “Quantifying privacy vulnerability of individual mobility traces: a case study of license plate recognition data.” Transportation research part C: emerging technologies 104 (2019): 78-94.
