一、Spark简介
【1】什么是Spark?
Apache Spark是用于大规模数据处理的统一分析引擎,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序
【2】Spark特点
运行速度快:Spark有先进的DAG执行引擎(Directed Acyclic Graph,有向无环图),支持循环数据流和内存计算易用:Spark支持使用Java、Scala、Python以及R语言快速编写应用,提供超过80个高级运算符,使得编写并行应用程序变得容易通用:Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)兼容性:Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等
【3】Spark生态体系
Spark的生态系统主要包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX 等组件,各个组件的具体功能如下:
Spark Core:Spark Core包含Spark的基本功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等。Spark建立在统一的抽象RDD之上,使其可以以基本一致的方式应对不同的大数据处理场景;通常所说的Apache Spark,就是指Spark CoreSpark SQL:Spark SQL允许开发人员直接处理RDD,同时也可查询Hive、HBase等外部数据源。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行查询,并进行更复杂的数据分析Spark Streaming:Spark Streaming支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流式计算分解成一系列短小的批处理作业。Spark Streaming支持多种数据输入源,如Kafka、Flume和TCP套接字等MLlib(机器学习):MLlib提供了常用机器学习算法的实现,包括聚类、分类、回归、协同过滤等,降低了机器学习的门槛,开发人员只要具备一定的理论知识就能进行机器学习的工作GraphX(图计算):GraphX是Spark中用于图计算的API,可认为是Pregel在Spark上的重写及优化,Graphx性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法
二、Spark部署
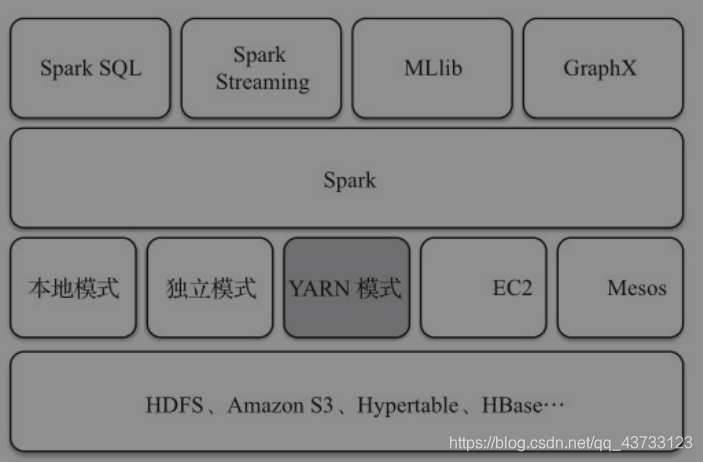
【1】Spark部署方式
Local模式:就是运行在一台计算机上的模式(通常用于本地测试,了解即可)local:所有计算都运行在一个线程中,没有任何并行计算local[K]:指定使用几个线程来运行计算local[*]:直接按照CPU的core核数来设置线程数
Standalone模式:运行任务由Spark内部实现进行资源调度,其中管理者为Master,工作者为WorkerYarn模式:运行任务由Yarn进行资源调度,此时就没有Master和Worker的概念了Mesos模式:这里不是重点,了解有这种模式即可
【2】Spark安装
1.vi spark-env.sh
在spark-env.sh中添加master主机名和端口号

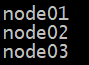
2.vi slaves
在slaves中添加worker节点
3.同步配置文件
1.vi yarn-site.xml
添加如下内容:
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
2.vi spark-env.sh
设置Yarn配置目录和Hadoop配置目录:
YARN_CONF_DIR=$YOUR_HADOOP_HOME_CONF
HADOOP_CONF_DIR=$YOUR_HADOOP_HOME_CONF
3.同步配置文件
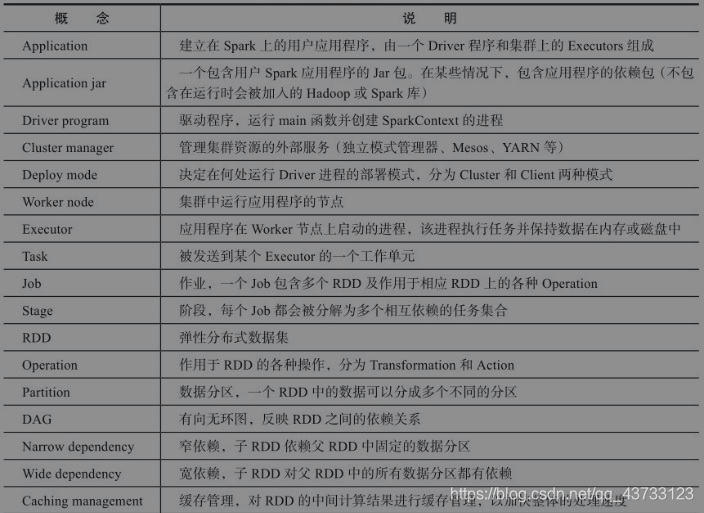
【3】Spark部分概念