Spark MLlib
机器学习是什么?
机器学习
数据挖掘有着50多年的发展历史。机器学习就是其子领域之一,特点是利用大型计算机集群来从海量数据中分析和提取知识
机器学习与计算统计学密切相关。它与数学优化紧密关联,为其提供方法、理论和应用领域。机器学习在各种传统设计和编程不能胜任的计算机任务中有广泛应用。典型的应用如垃圾邮件过滤、光学字符识别(OCR)、搜索引擎和计算机视觉。机器学习有时和数据挖掘联用,但更偏向探索性数据分析,亦称为无监督学习。
与学习系统的可用输入自然属性不同,机器学习系统可分为3种。学习算法发现输入数据的内在结构。它可以有目标(隐含模式),也可以是发现特征的一种途径。
| 无监督学习 | 学习系统的输入数据中并不包含对应的标签(或期望的输出),它需要自行从输入中找到输入数据的内在结构 |
| 监督学习 | 系统已知各输入对应的期望输出系统的目标是学习如何将输入映射到输出 |
| 强化学习 | 系统与环境进行交互,它有已定义的目标,但没有人类显式地告知其是否正在接近目标 |
Spark MLlib
MLlib是Spark的机器学习(ML)库。其目标是使实用的机器学习可扩展且容易。在较高级别,它提供了以下工具:
- ML算法:常见的学习算法,例如分类,回归,聚类和协同过滤
- 特征化:特征提取,变换,降维和选择
- 管道:用于构建,评估和调整ML管道的工具
- 持久性:保存和加载算法,模型和管道
- 实用程序:线性代数,统计信息,数据处理等。
Spark MLlib案例
基于
DataFrame的API是主要API
快速入门
- pom.xml
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-mllib -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>2.2.1</version>
</dependency>
def main(args: Array[String]): Unit = {
// 屏蔽日志
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.apache.jetty.server").setLevel(Level.OFF)
val spark = SparkSession
.builder()
.master("local[*]")
.appName(Demo01.getClass.getName)
.getOrCreate()
import spark.implicits._
val data = Seq(
/**
* 稀疏向量表示方式
* 4, Seq((0, 1.0), (3, -2.0))
* 表示向量长度为4 有两个非0位置:0和3位置,0和3的值分别为1.0、-2.0
* 该向量可表示为(1.0, 0, 0, -2.0)
*/
Vectors.sparse(4, Seq((0, 1.0), (3, -2.0))),
// 密集向量表示方式
Vectors.dense(4.0, 5.0, 0.0, 3.0),
Vectors.dense(6.0, 7.0, 0.0, 8.0),
Vectors.sparse(4, Seq((0, 9.0), (3, 1.0)))
)
val df = data.map(Tuple1.apply).toDF("features")
df.show()
// 计算df features列的相关性
val Row(coeff1: Matrix) = Correlation.corr(df, "features").head
println(s"Pearson correlation matrix:\n $coeff1")
val Row(coeff2: Matrix) = Correlation.corr(df, "features", "spearman").head
println(s"Spearman correlation matrix:\n $coeff2")
spark.stop()
}
基本统计
Correlation(相关性)
Correlation 使用指定的方法为向量的输入数据集计算相关矩阵。输出将是一个DataFrame,其中包含向量列的相关矩阵。
皮尔森系数公式:
当两个变量的线性关系增强时,相关系数趋于1或-1。正相关时趋于1,负相关时趋于-1。当两个变量独立时相关系统为0,但反之不成立。当Y和X服从联合正态分布时,其相互独立和不相关是等价的
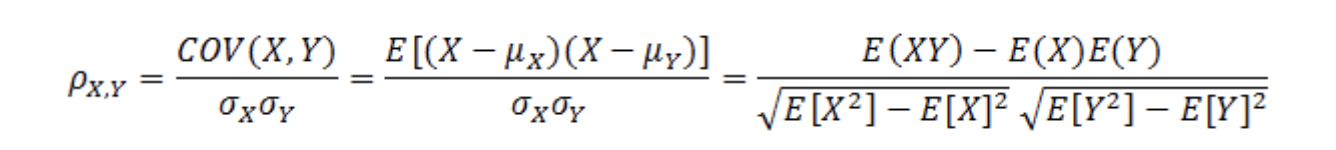
val data = Seq(
/**
* 稀疏向量表示方式
* 4, Seq((0, 1.0), (3, -2.0))
* 表示向量长度为4 有两个非0位置:0和3位置,0和3的值分别为1.0、-2.0
* 该向量可表示为(1.0, 0, 0, -2.0)
*/
Vectors.sparse(4, Seq((0, 1.0), (3, -2.0))),
// 密集向量表示方式
Vectors.dense(4.0, 5.0, 0.0, 3.0),
Vectors.dense(6.0, 7.0, 0.0, 8.0),
Vectors.sparse(4, Seq((0, 9.0), (3, 1.0)))
)
val df = data.map(Tuple1.apply).toDF("features")
df.show()
// 计算features的相关性, method系数默认为Pearson
val Row(coeff1: Matrix) = Correlation.corr(df, "features").head
println(s"Pearson correlation matrix:\n $coeff1")
// 计算features的相关性, method系数为Spearson
val Row(coeff2: Matrix) = Correlation.corr(df, "features", "spearman").head
println(s"Spearman correlation matrix:\n $coeff2")
Hypothesis testing(假设检验)
假设检验是一种强大的统计工具,可用来确定结果是否具有统计学意义,以及该结果是否偶然发生。spark.ml当前支持Pearson的卡方(
数学处理错误)测试独立性。
ChiSquareTest针对标签上的每个功能进行Pearson的独立性测试。对于每个要素,(要素,标签)对将转换为列联矩阵,针对该列矩阵计算卡方统计量。所有标签和特征值必须是分类的。
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.ml.stat.ChiSquareTest
val data = Seq(
(0.0, Vectors.dense(0.5, 10.0)),
(0.0, Vectors.dense(1.5, 20.0)),
(1.0, Vectors.dense(1.5, 30.0)),
(0.0, Vectors.dense(3.5, 30.0)),
(0.0, Vectors.dense(3.5, 40.0)),
(1.0, Vectors.dense(3.5, 40.0))
)
val df = data.toDF("label", "features")
df.show()
val chi = ChiSquareTest.test(df, "features", "label").head
println(s"pValues = ${chi.getAs[Vector](0)}")
println(s"degreesOfFreedom ${chi.getSeq[Int](1).mkString("[", ",", "]")}")
println(s"statistics ${chi.getAs[Vector](2)}")
Summarizer(总结器)
import spark.implicits._
import org.apache.spark.ml.stat.Summarizer._
val data = Seq(
(Vectors.dense(2.0, 3.0, 5.0), 1.0),
(Vectors.dense(4.0, 6.0, 7.0), 2.0)
)
val df = data.toDF("features", "weight")
val (meanVal, varianceVal) = df.select(metrics("mean", "variance")
.summary($"features", $"weight").as("summary"))
.select("summary.mean", "summary.variance")
.as[(Vector, Vector)].first()
println(s"with weight: mean = ${meanVal}, variance = ${varianceVal}")
val (meanVal2, varianceVal2) = df.select(mean($"features"), variance($"features"))
.as[(Vector, Vector)].first()
println(s"without weight: mean = ${meanVal2}, sum = ${varianceVal2}")