numpy安装
pip install numpy
numpy底层是使用C语言来实现运算的效果非常高
数据清洗的意义
- 现实生活中,数据并非完美,需要进行清洗才能进行后面的数据分析
- 数据清洗是整个数据分析项目最消耗时间的一步
- 数据的质量最终决定了数据分析的准确性
- 数据清洗是唯一可以提高数据质量的方法,使得数据分析的结果也变得更加可靠
数据清洗常用工具
- 目前在Python中,numpy和pandas是最主流的工具
- numpy中的向量化运算使得数据处理变得高效
- pandas提供了大量数据清洗的高效方法
- 在Python中,尽可能多的使用numpy和pandas中的函数,提高数据清洗的效率
arange和rang的区别
- 在Python中range只能迭代整型
- numpy中的arange步可以为浮点型
numpy常用的数据结果
- numpy中常用的数据结果是ndarray格式
- 使用array函数创建,语法格式为array(列表或元组)
- 可以使用其他函数例如:arange(迭代器) 、linspace(等差数组)、zeros等创建
numpy常用方法
zeros
ones
dtype
size:返回数组中使用元素的总和
shape:查看该数组的行和列数(返回的结果是元组类型(当只有))
ndmin:查看数组为多少维数组
练习代码
# -*- coding: utf-8 -*-
# @Time : 2020/2/1 19:35
# @Author : 大数据小J
import numpy as np
"""
array
里面可以传字符串,字典,元组,列表
np.dtype 返回的结果是numpy这个数据类型
dtype=None array里面有这个参数,这个参数的意思是可以强制转换数据类型。(强制类型转换,只能够是列表和元组,并且里面的数据为统一数据)
:代表着
"""
a = np.array([1, 2, 3, 4, 5], dtype=float) # [1. 2. 3. 4. 5.] 当传入的数据类型为列表类型,返回的结果为列表类型
b = np.array((1, 2, 3, 4, 5)) # [1 2 3 4 5] 当传入的数据为元组类型,返回的结果也是列表类型
c = np.array('demo') # demo 当传入字符串类型,返回的结果为字符串类型
d = np.array({'name': 'Big_data J'}) # {'name': 'Big_data J'} 当传入的结果为字典类型,返回的结果为字典类型
# print(np.dtype) # <class 'numpy.dtype'> 返回的结果为numpy这个数据类型
e = np.array((1, 2, 3, 4, 5), dtype=str) # ['1' '2' '3' '4' '5'] 可以强制转换为字符串类型
arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]) # 使用array可以创建列表嵌套数据,也可以生成二维数据以上等
# print(arr)
# print(arr[0]) # [1 2 3 4]返回的结果为列表的第一行数据,numpy也是从0开始
# print(arr[1]) # [5 6 7 8]返回的结果为列表的第二行数据
# print(arr[2]) # [ 9 10 11 12]返回的结果为列表的第三行数据
# print(arr[1:2]) # [[5 6 7 8]] 返回的结果是遵从左闭右开的原则。
# print(arr[1:3]) #[[ 5 6 7 8] [ 9 10 11 12]]
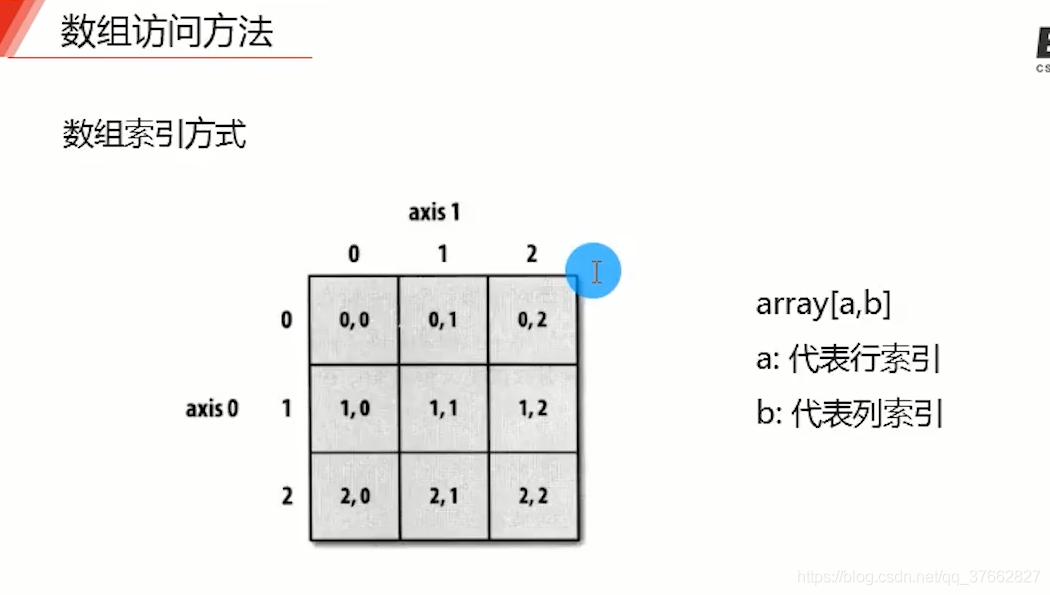
# print(arr[0, 1]) # 2 array中是以”,“来操控
"""
np.arange()
意思:和range差别不大,但可以指定步长为浮点型
这个方法是numpy里面的迭代器与range和像
arange 和 range 有什么区别? 区别在于 arange可以生成浮点型 range只能生成整型
arange 也是一个左闭右开的原则
"""
ara = np.arange(1, 10, 0.5) # [1. 1.5 2. 2.5 3. 3.5 4. 4.5 5. 5.5 6. 6.5 7. 7.5 8. 8.5 9. 9.5] 可以指定步长为浮点型
# print(ara)
"""
linspace
意思:等差数组
常见的参数: start, stop, num=50, endpoint=True
start:开始值
stop: 结束值
num=50: 默认情况下,这个参数为50,这代表着元素个数,生成的元素
endpoint=True : 默认情况下为True,意思是:是否包含其结束值(也就是stop)
"""
# lin = np.linspace(1, 10, 10, endpoint=True) # endpoint默认情况下为True,当我们想不包含其结束值的时候可修改为False
# print(lin) # [ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.] 返回的结果为浮点类型的等差数组
lin2 = np.linspace(1, 5, 10, endpoint=True) # [1. 1.44444444 1.88888889 2.33333333 2.77777778 3.22222222
# 3.66666667 4.11111111 4.55555556 5. ] 生成的结果算法为4/9
"""
zeros
意思:生成一个为0的数据
常见的参数shape, dtype=None, order='C'
shape:传参 (传入的数据类型可以为列表,元组).第一个值为行,第二个值为列
dtype:强制类型转换
ones
意思:生成一个为1的数据
常见的参数shape, dtype=None, order='C'
shape:传参 (传入的数据类型可以为列表,元组),第一个值为行,第二个值为列
dtype:强制类型转换
ndim
意思:判断一个数组是几维数组
shape
意思:查看数组为几行几列。当为一维数组的时候(返回的结果为(4,))
返回的数据类型为元组类型
size
意思:返回数组里面有多少个元素
dtype
意思:返回数组的数据类型
"""
ze = np.zeros(shape=[4, 5]) # 生成一个四行五列的二维数据
ze1 = np.zeros(4) # [0. 0. 0. 0.] 返回的结果为一维数组 默认情况下为浮点类型
# print(ze1)
on = np.ones(4) # [1. 1. 1. 1.] 生成一个一维数组 默认情况下为浮点数据类型
on1 = np.ones([4, 5], dtype=int) # 生成一个二维数组 浮点型
# print(on1+1.5) # 可以对数组的值进行加法运算
# print(on1.ndim) # 2 查看数组的行和列,返回为元组类型
# print(on.shape) # (4,) 返回的结果为元组类型 一维数组直接输出列数
print(on1.shape) #(4, 5) 二维数组先行后列
# print(on.size) # 4 返回数组里面的元素个数
# print(on1.size) # 20
# print(on.dtype) # float64 返回的结果为浮点类型
# print(on1.dtype) # int32 返回的结果为整型
data = ((1, 1.5, 2.5, 3.3, 4.4,), (2, 3.4, 5.5, 6.6, 7.7), (7.7, 8.8, 9.9, 2.2, 6.7))
demo = np.array(data)
# print(demo[1, 4]) # 2.5 从0开始,第一个值为行索引,第二个值代表列索引
# print(demo[1:, 2]) # [5.5 9.9] 先选择第一行以后的数组,在选择第一行以后的数组的第二个列数
# print(demo[:, 1:3]) # 不选择起始值和结束值, 在进行选择行的第1列到第3列(但不包含第三列)
