1. 布置虚拟机系统
a.本人用的虚拟机平台是VMware15Pro
VMware的安装和破解教程地址
b.我比较喜欢ubuntn18.04的界面(下载desktop版本)
ubuntu18.04的国内镜像下载地址
c.在虚拟机中安装ubuntu系统比较简单,而且要根据自己主机的情况进行配置,下图是我的虚拟机配置截图
记得在网络适配器选项中选择NAT模式,这样可以共享主机的网络,不用再单独配置ip地址 
如果在虚拟机配置的时候出现“此主机支持Intel VT-x,但Intel VT-x处于禁用状态。。。”的报错信息时,要根据主机牌子的不同快捷键重启进入bios界面,一般在configuration下面会有Intel Virtual Technology,把后面的Disable改成Enable,切记保存后退出bios界面会自动重启就能解决这个问题。

设置好我们最喜欢最熟练的密码(以后ubuntu终端sudo密码就是这个)虚拟系统大功告成就会出现下图界面:

2. JAVA环境的下载和配置
Java的环境可以选择Oracle的JDK,或者是openjdk,我为了方便直接选择在终端通过命令安装openjdk-8(不同的Hadoop版本对应不同的openjdk版本,大家可以自己查阅自己的所需的jdk版本)so let’s打开终端:
sudo apt-get install openjdk-8-jre openjdk-8-jdk
接着打开配置文件bashrc
sudo gedit ./bashrc
在打开的文本中配置JAVA_HOME在最后一行加入
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
上面加入的环境变量可以在指定文件夹中去确认一下文件名是否存在或者是否正确,下面就是使配置文件生效
source ~/.bashrc
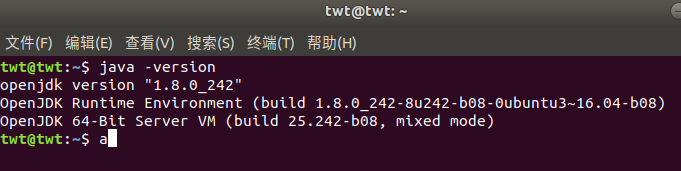
最后检查Java环境是否配置成功
echo $JAVA_HOME
java -version
如下图就是安装并且配置成功的界面
- 安装并配置hadoop3.2.1伪分布式
首先下载hadoop相应的版本,我在hadoop官网发现有国内镜像资源的链接,所以就直接用的官网的最新版本,链接如下:hadoop2.7.x以上稳定版本的下载镜像下后缀是tar.gz的链接
打开如下图,我们就选择稳定版本stable,里面就有相关链接,不用思考我们肯定下载最大的那个。

解压到 /usr/local 的目录下(注意要进入hadoop安装下载的目录再输下面的代码)
sudo tar -zxvf hadoop-2.6.0.tar.gz -C /usr/local
为方便以后的操作,可把原来为hadoop3.2.1文件夹的名字改成hadoop。
然后cd进入hadoop/etc/hadoop目录下,配置以下的四个文本文件。(都用sudo gedit命令打开再进行配置)
cd /usr/local/hadoop/etc/hadoop
先配置core-site.xml
sudo gedit ./core-site.xml
在打开的文本中找到在中间加入代码
<property>
<name>fs.defaultFS</name>
<value>file:///</value>
<value>hdfs://loacalhost</value>
</property>
点击右上角的保存按钮在关闭就会出现如下的提示:
如同上述步骤一样打开hdfs-site.xml
sudo gedit ./hdfs-site.xml
在类似的位置加入代码:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
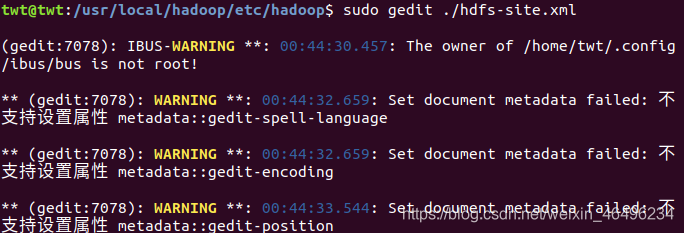
打开mapred-site.xml
sudo gedit ./mapred-site.xml
加入的代码:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
最后打开yarn-site.xml
sudo gedit ./yarn-site.xml
加入代码:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
这个时候我们配置好了hadoop,可以打开hadoop服务试一下:
经过本人的多次试验和参考的资料:
进入/usr/local/hadoop目录下sudo start-all.sh会报错
进入/usr/local/hadoop/sbin目录下sudo start-all.sh 会报错
但是我们在/usr/local/hadoop/sbin目录下查找文件发现是有start-all.sh这个目录的
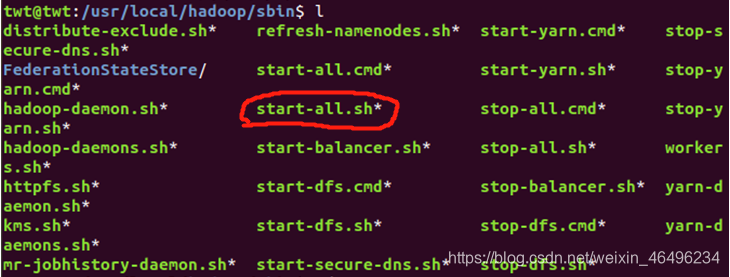
不知道为什么反正就是不行
但是有一种命令可行
cd /usr/local/hadoop
sbin/start-all.sh
发现就可以了。
这时发现了新的问题
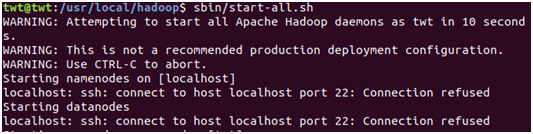
如上图出现的问题时ssh的连接被拒绝
是因为我没安装openssh-server,所以我们先安装服务
sudo apt-get install openssh-server
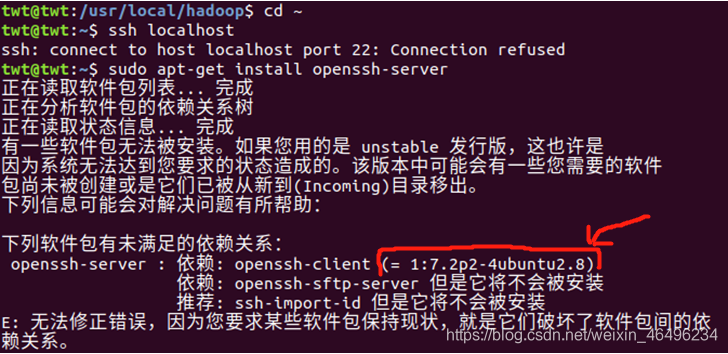
ok,fine,一个新的问题它有出现了,让我们平静一下冲动的心情慢慢品品这报错的地方,原来是安装的依赖版本问题,如上图所示:我们需要的openssh-client是1:7.2p2-4ubuntu2.8(这里每个人的版本会不一样,具体的直接复制终端中保存的依赖关系后面的版本)
然后我们就根据报错信息安装固定的版本(openssh-client=1:7.2p2-4ubuntu2.8)
sudo apt-get install openssh-client=1:7.2p2-4ubuntu2.8
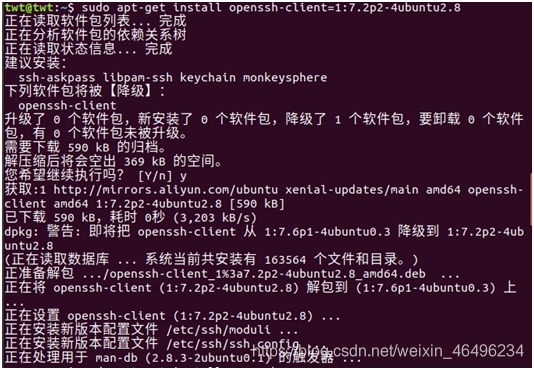
安装并更新降级了依赖,这时我们再次请求安装openssh-server
sudo apt-get install openssh-server

这个时候在主目录下查一下ssh
ssh localhost
就会发现ssh已经成功安装完毕开始服务了

然后我们回到上面一步,开启hadoop
cd /usr/local/hadoop
sbin/start-all.sh
然而报错信息又来了
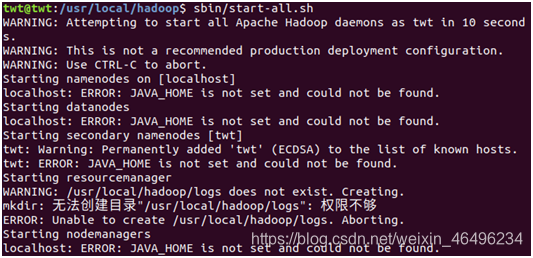
因为hadoop-config.sh中的JAVA_HOME没有配置,然而我并不知道hadoop-config.sh是个什么玩意儿,也不知道它的位置,但我确定它肯定在hadoop的大包中,于是就在hadoop的目录下搜索hadoop-config.sh就会出现这个包,它的位置也显示了在libexec中
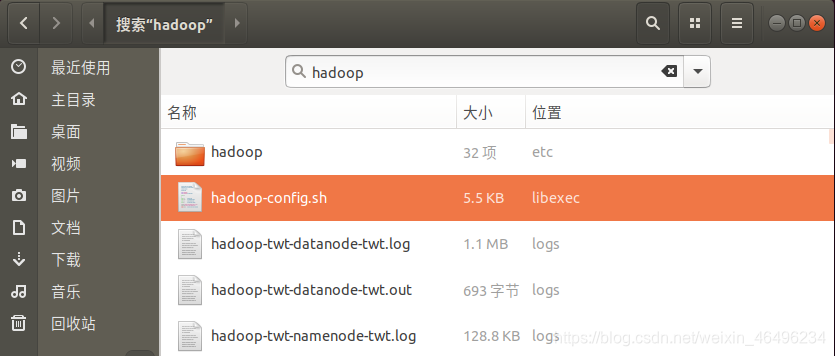
我们在当前文件夹下打开终端加入环境变量。(一定要加在第一行!)
sudo gedit ./hadoop-config.sh

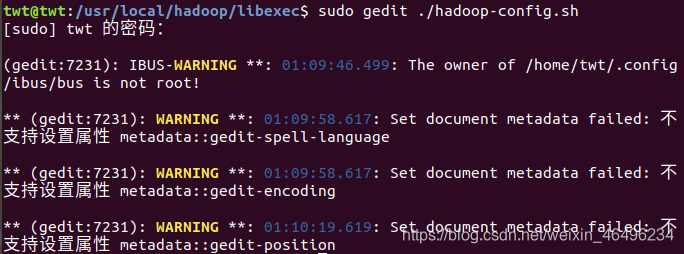
好了我们又解决一个问题,继续上一步,我们再次开启!
然而问题又来了。。。
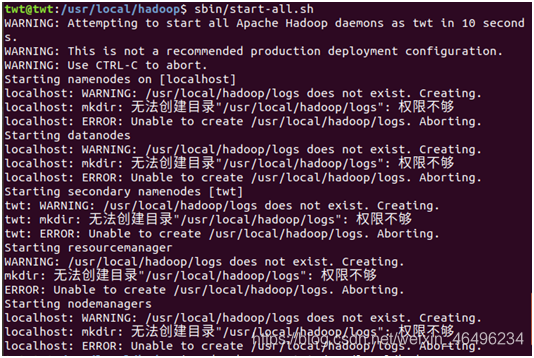
所有的这些权限不够,是因为之前新建了一个hadoop的用户,我们要用那个用户登录。
进入usr/local/hadoop目录
sudo chown –R twt /usr/loacal/hadoop
 好了已至深夜,我最后一次启动hadoop
好了已至深夜,我最后一次启动hadoop
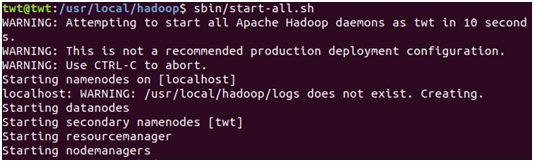
大功告成,当然了里面有个警告,此时心里想(我们程序员只在乎error,不在乎warning)然而还是硬着头皮查了点资料。
我们第一次打开虚拟机必须得在cd /usr/local/hadoop目录中用sbin/start-all.sh命令打开hadoop。
但是只要打开过一次之后我们就能在cd /usr/local目录中直接用start-all.sh命令打开hadoop。如下图:
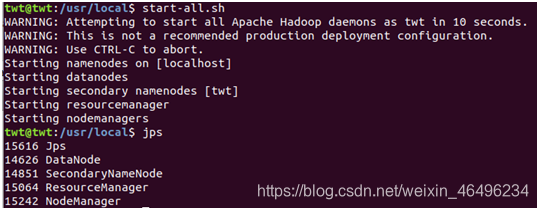
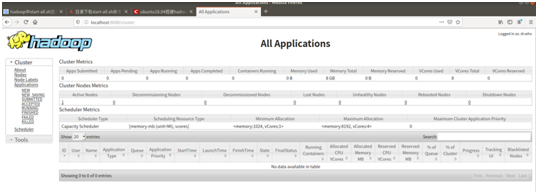
最后打开localhost:8088/cluster就能看到hadoop的工作界面和伪分布式的具体参数。