上一篇:CentOS8 安装 Hadoop3.2.1 独立模式、伪分布模式
本文以root用户安装,开发测试使用。生产环境可以考虑用其他用户安装,比如hadoop或hdfs,yarn
下载地址:
https://hadoop.apache.org/releases.html
上传并解压hadoop-3.2.1.tar.gz
文档地址:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/ClusterSetup.html
一、准备工作
1.设置机器名及对应IP,CentOS8 修改主机名,配置对应IP
2.安装配置jdk8+,CentOS8 安装JDK8 jdk-8u192-linux-x64.tar.gz
3.ssh免密,CentOS8 设置无密码SSH,SSH免密
4.安装配置pdsh CentOS8 安装配置使用 pdsh 并行分布式shell (非必须)

5.关闭防火墙,CentOS8 关闭防火墙,禁用防火墙
6.时间同步(虚拟机就省了)
二、部署结构
| 机器名 | IP | 部署内容 |
| dev11 | 192.168.0.11 | NameNode,DataNode,NodeManager |
| dev12 | 192.168.0.12 | SecondaryNameNode,DataNode,NodeManager |
| dev13 | 192.168.0.13 | DataNode,NodeManager,ResourceManager 和 MapReduce-JobHistoryServer |
SecondaryNameNode和NameNode可以在一台,推荐在两台,防止意外。
(有条件的NameNode应该单独一台,为了性能。那么SecondaryNameNode也应该单独一台)
ResourceManager可以在1号服务器,也可以在其他服务器,比如放在3号服务器,看起来平衡。
但是,从1号服务器启动yarn时,在3号服务器启动不了ResourceManager,会报错。可以在3号服务器启动hdfs和yarn。
JobHistoryServer需要单独启动,如果配置不指定主机或IP,在哪台服务器都可以启动。如果指定了服务器,就在指定服务器启动。在其他服务器启动会报错。
我把JobHistoryServer和ResourceManager部署在一个节点上。
NodeManager一般和DataNode在一起
三、配置
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/core-default.xml
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
1./etc/profile
export JAVA_HOME=/opt/jdk1.8.0_192
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin2.etc/hadoop/hadoop-env.sh
#配置hdfs用户
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
#配置yarn用户
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
#至少必须指定JAVA_HOME,以便在每个远程节点上正确定义它。
export JAVA_HOME=/opt/jdk1.8.0_192
export HADOOP_HOME=/opt/hadoop-3.2.1
#在大多数情况下,您应该指定HADOOP_PID_DIR和HADOOP_LOG_DIR目录,以便它们只能由将要运行hadoop守护程序的用户写入。否则可能会发生符号链接攻击。
export HADOOP_LOG_DIR=${HADOOP_HOME}/logs
export HADOOP_PID_DIR=${HADOOP_HOME}/pidyarn-env.sh和mapred-env.sh不用配置
3.etc/hadoop/core-site.xml 配置通用属性
<configuration>
<!-- NameNode URI-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://dev11:9000</value>
</property>
<!-- 其他临时目录的基础-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.2.1/tmp</value>
</property>
<!-- 序列文件中使用的缓冲区大小。 该缓冲区的大小可能应该是硬件页面大小的倍数(在Intel x86上为4096),并且它确定在读写操作期间要缓冲多少数据。-->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>4.etc/hadoop/hdfs-site.xml 配置HDFS属性
<configuration>
<!-- 默认块复制。 创建文件时可以指定实际的复制数量。 如果在创建时未指定复制,则使用默认值。-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 确定DFS NameNode在本地文件系统上应该存储名称表(fsimage)的位置。 如果这是用逗号分隔的目录列表,则将名称表复制到所有目录中,以实现冗余。-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-3.2.1/dfs/name</value>
</property>
<!-- 允许/排除的数据节点列表。 如有必要,请使用这些文件来控制允许的数据节点列表。
命名一个文件,其中包含允许连接到名称节点的主机列表。 必须指定文件的完整路径名。 如果该值为空,则允许所有主机。
<property>
<name>dfs.hosts</name>
<value>/opt/hadoop-3.2.1/hosts</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/hadoop-3.2.1/hosts.exclude</value>
</property>
-->
<!-- HDFS块大小,例如128k,512m ,1g等,或提供完整的字节大小(例如134217728表示128 MB)-->
<property>
<name>dfs.blocksize</name>
<value>128m</value>
</property>
<!-- 更多的NameNode服务器线程可处理来自大量DataNode的RPC。-->
<property>
<name>dfs.namenode.handler.count</name>
<value>10</value>
</property>
<!-- 逗号分隔的DataNode本地文件系统上应存储其块的路径列表。 如果这是逗号分隔的目录列表,则数据将存储在所有命名的目录中,通常在不同的设备上。-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-3.2.1/dfs/data</value>
</property>
<!-- SecondaryNameNode http服务器地址和端口。-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>dev12:9868</value>
</property>
<!-- SecondaryNameNode HTTPS服务器地址和端口。-->
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>dev12:9869</value>
</property>
</configuration>5.etc/hadoop/yarn-site.xml 配置yarn属性
日志聚合,把job的执行日志聚合到一起,供obHistorySever查看
<configuration>
<!-- 以逗号分隔的服务列表,其中服务名称应仅包含a-zA-Z0-9_并且不能以数字开头-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 容器可以覆盖而不是使用NodeManager的默认环境变量。-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- ResourceManager主机。主机可以设置单个主机名,以代替设置所有yarn.resourcemanager * address资源。生成ResourceManager组件的默认端口。-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>dev13</value>
</property>
<!-- 是否启用日志聚合。日志聚合收集每个容器的日志,并在应用程序完成后将这些日志移动到文件系统(例如HDFS)中。-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 删除聚合日志前要保留多长时间。 -1禁用。 小心将其设置得太小,您将向名称节点发送垃圾邮件。-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 应用程序完成时将应用程序日志移动到的HDFS目录。 需要设置适当的权限。 仅在启用日志聚合的情况下适用。-->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/user/container/logs</value>
</property>
</configuration>6.etc/hadoop/mapred-site.xml 配置MapReduce属性
加入配置JobHistoryServer,如果配置不指定主机或IP,在哪台服务器都可以启动。
但是指定localhost或127.0.0.1,JobHistoryServer无法启动,会报错。
<configuration>
<!-- 用于执行MapReduce作业的运行时框架。 可以是local, classic 或者 yarn。-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MapReduce应用程序的CLASSPATH。-->
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
<!-- MapReduce JobHistoryServer IPC 主机:端口-->
<property>
<name>mapreduce.jobhistory.addres</name>
<value>dev13:10020</value>
</property>
<!-- MapReduce JobHistoryServer Web UI 主机:端口-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>dev13:19888</value>
</property>
<!-- 提交作业时使用的暂存目录。(hdfs目录)-->
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/tmp/hadoop-yarn/staging</value>
</property>
<!-- MapReduce作业写入历史文件的目录。(hdfs目录)-->
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/tmp/hadoop-yarn/staging/history/done_intermediate</value>
</property>
<!-- MR JobHistoryServer管理历史文件的目录。(hdfs目录)-->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/tmp/hadoop-yarn/staging/history/done</value>
</property>
</configuration>7.etc/hadoop/workers
在hadoop 2.x中这个文件叫slaves,配置所有datanode的主机地址,只需要把所有的datanode主机名填进去就好了
dev11
dev12
dev13把所有这些配置复制到另外两台服务器
四、格式化hdfs
在namenode所在服务器执行
[root@dev11 opt]# hdfs namenode -format
2020-05-20 07:00:02,336 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1609697951-192.168.0.11-1589929202324
2020-05-20 07:00:02,351 INFO common.Storage: Storage directory /opt/hadoop-3.2.1/dfs/name has been successfully formatted.
2020-05-20 07:00:02,384 INFO namenode.FSImageFormatProtobuf: Saving image file /opt/hadoop-3.2.1/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2020-05-20 07:00:02,499 INFO namenode.FSImageFormatProtobuf: Image file /opt/hadoop-3.2.1/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 399 bytes saved in 0 seconds .
2020-05-20 07:00:02,516 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2020-05-20 07:00:02,524 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2020-05-20 07:00:02,524 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at dev11/192.168.0.11
************************************************************/

五、启动
1.启动dfs,
可以在1号服务器启动,也可以在3号服务器启动
[root@dev13 opt]# start-dfs.sh
Starting namenodes on [dev11]
Starting datanodes
Starting secondary namenodes [dev12]
[root@dev11 opt]# jps
4897 NameNode
5108 Jps
4997 DataNode
[root@dev12 opt]# jps
4947 Jps
4774 DataNode
4902 SecondaryNameNode
[root@dev13 opt]# jps
8160 DataNode
8433 Jps


2.启动yarn
在指定yarn服务器启动yarn
[root@dev13 opt]# start-yarn.sh
Starting resourcemanager
Starting nodemanagers
[root@dev11 opt]# jps
4897 NameNode
5907 NodeManager
4997 DataNode
6031 Jps
[root@dev12 opt]# jps
4774 DataNode
4902 SecondaryNameNode
6294 NodeManager
6429 Jps
[root@dev13 opt]# jps
8160 DataNode
9956 NodeManager
10327 Jps
9803 ResourceManager
3.启动MapReduce JobHistoryServer
在指定的服务器启动
[root@dev13 opt]# mapred --daemon start historyserver
[root@dev13 opt]# jps
8160 DataNode
10496 Jps
9956 NodeManager
10406 JobHistoryServer
9803 ResourceManager
六、web控制台
本地配置hosts
1.hdfs控制台

浏览hdfs文件系统

2.yarn控制台

3. JobHistoryServer控制台

七、停止
1.停止JobHistoryServer
[root@dev13 opt]# mapred --daemon stop historyserver
2.停止yarn
[root@dev13 opt]# stop-yarn.sh
Stopping nodemanagers
Stopping resourcemanager
3.停止hdfs
[root@dev13 opt]# stop-dfs.sh
Stopping namenodes on [dev11]
Stopping datanodes
Stopping secondary namenodes [dev12]
八、日志文件
有错误看日志



九、运行个例子
[root@dev11 hadoop-3.2.1]# hdfs dfs -mkdir -p /user/root
[root@dev11 hadoop-3.2.1]# hdfs dfs -mkdir input
[root@dev11 hadoop-3.2.1]# hdfs dfs -put etc/hadoop/*.xml input
[root@dev11 hadoop-3.2.1]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
1.hdfs控制台

2.yarn控制台
job运行中,可以点击ApplicationMaster,查看运行情况


运行完成,可以点击History,查看之前运行的job的情况
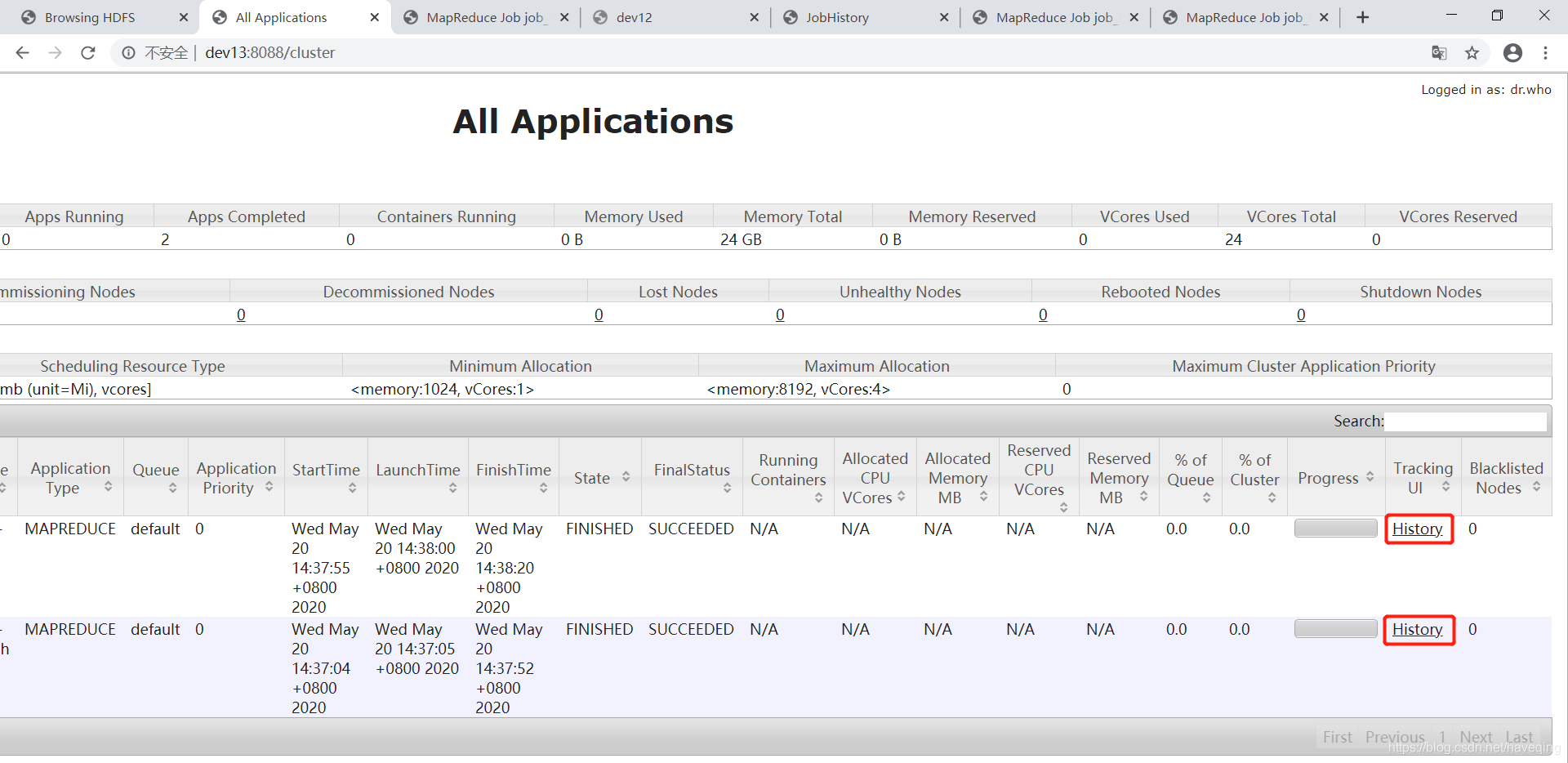

有的点不开,跳到dev12服务器了,可以手动吧dev12换成dev13,
没必要在每个节点都启动JobHistoryServer吧,可以直接在dev13的JobHistoryServer中查看History。

3.JobHistoryServer



十、报错处理
1.有字符不能识别,是因为在windows下编辑的,文件另存为UNIX格式UTF-8无BOM编码。
2020-05-18 12:05:02,238 ERROR conf.Configuration: error parsing conf mapred-site.xml
com.ctc.wstx.exc.WstxIOException: Invalid UTF-8 middle byte 0xc3 (at char #726, byte #20)
2020-05-18 12:13:45,129 ERROR conf.Configuration: error parsing conf yarn-site.xml
com.ctc.wstx.exc.WstxIOException: Invalid UTF-8 middle byte 0xd4 (at char #604, byte #20)
2.启动hdfs,但是没先格式化hdfs会报错。
2020-05-20 06:54:40,328 WARN org.apache.hadoop.hdfs.server.common.Storage: Storage directory /opt/hadoop-3.2.1/dfs/name does not exist
2020-05-20 06:54:40,330 WARN org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Encountered exception loading fsimage
org.apache.hadoop.hdfs.server.common.InconsistentFSStateException: Directory /opt/hadoop-3.2.1/dfs/name is in an inconsistent state: storage directory does not exist or is not accessible.
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverStorageDirs(FSImage.java:391)
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:242)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFSImage(FSNamesystem.java:1105)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFromDisk(FSNamesystem.java:720)
at org.apache.hadoop.hdfs.server.namenode.NameNode.loadNamesystem(NameNode.java:648)
at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:710)
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:953)
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:926)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1692)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1759)
3.在非ResourceManager节点启动yarn,ResourceManager启动报错
如果在dev11启动yarn,查看dev11下的日志,logs/hadoop-root-resourcemanager-dev11.log
2020-05-18 13:16:31,320 INFO org.apache.hadoop.http.HttpServer2: HttpServer.start() threw a non Bind IOException
java.net.BindException: Port in use: dev13:8088
at org.apache.hadoop.http.HttpServer2.constructBindException(HttpServer2.java:1218)
at org.apache.hadoop.http.HttpServer2.bindForSinglePort(HttpServer2.java:1240)
at org.apache.hadoop.http.HttpServer2.openListeners(HttpServer2.java:1299)
at org.apache.hadoop.http.HttpServer2.start(HttpServer2.java:1154)
at org.apache.hadoop.yarn.webapp.WebApps$Builder.start(WebApps.java:439)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.startWepApp(ResourceManager.java:1231)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.serviceStart(ResourceManager.java:1340)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.main(ResourceManager.java:1535)
Caused by: java.net.BindException: 无法指定被请求的地址
at sun.nio.ch.Net.bind0(Native Method)
at sun.nio.ch.Net.bind(Net.java:433)
at sun.nio.ch.Net.bind(Net.java:425)
at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:223)
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:74)
at org.eclipse.jetty.server.ServerConnector.openAcceptChannel(ServerConnector.java:351)
at org.eclipse.jetty.server.ServerConnector.open(ServerConnector.java:319)
at org.apache.hadoop.http.HttpServer2.bindListener(HttpServer2.java:1205)
at org.apache.hadoop.http.HttpServer2.bindForSinglePort(HttpServer2.java:1236)
... 7 more
排除了防火墙的问题,端口占用的问题
解决办法,在ResourceManager所在服务器启动yarn,也可以启动hdfs。或者把ResourceManager和NameNode部署在一台服务器。
4.如果指定了JobHistoryServer的主机或IP,没在指定主机启动,会报错
(还有JobHistoryServer如果指定localhost和127.0.0.1也启动不了,你可以选择不指定。)
2020-05-19 10:13:05,382 INFO org.apache.hadoop.http.HttpServer2: HttpServer.start() threw a non Bind IOException
java.net.BindException: Port in use: dev11:19888
at org.apache.hadoop.http.HttpServer2.constructBindException(HttpServer2.java:1218)
at org.apache.hadoop.http.HttpServer2.bindForSinglePort(HttpServer2.java:1240)
at org.apache.hadoop.http.HttpServer2.openListeners(HttpServer2.java:1299)
at org.apache.hadoop.http.HttpServer2.start(HttpServer2.java:1154)
at org.apache.hadoop.yarn.webapp.WebApps$Builder.start(WebApps.java:439)
at org.apache.hadoop.yarn.webapp.WebApps$Builder.start(WebApps.java:428)
at org.apache.hadoop.mapreduce.v2.hs.HistoryClientService.initializeWebApp(HistoryClientService.java:166)
at org.apache.hadoop.mapreduce.v2.hs.HistoryClientService.serviceStart(HistoryClientService.java:122)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
at org.apache.hadoop.service.CompositeService.serviceStart(CompositeService.java:121)
at org.apache.hadoop.mapreduce.v2.hs.JobHistoryServer.serviceStart(JobHistoryServer.java:200)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
at org.apache.hadoop.mapreduce.v2.hs.JobHistoryServer.launchJobHistoryServer(JobHistoryServer.java:227)
at org.apache.hadoop.mapreduce.v2.hs.JobHistoryServer.main(JobHistoryServer.java:236)
Caused by: java.net.BindException: 无法指定被请求的地址
at sun.nio.ch.Net.bind0(Native Method)
at sun.nio.ch.Net.bind(Net.java:433)
at sun.nio.ch.Net.bind(Net.java:425)
at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:223)
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:74)
at org.eclipse.jetty.server.ServerConnector.openAcceptChannel(ServerConnector.java:351)
at org.eclipse.jetty.server.ServerConnector.open(ServerConnector.java:319)
at org.apache.hadoop.http.HttpServer2.bindListener(HttpServer2.java:1205)
at org.apache.hadoop.http.HttpServer2.bindForSinglePort(HttpServer2.java:1236)
... 12 more
十一、HDFS High Availability Using the Quorum Journal Manager

十二、ResourceManager High Availability
https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html