import pandas as pd
import numpy as np
import lightgbm as lgb
import matplotlib. pyplot as plt
import seaborn as sns
from sklearn. model_selection import KFold
from sklearn. metrics import r2_score
def parseData ( df) :
"""
预处理数据
"""
df[ 'rentType' ] [ df[ 'rentType' ] == '' ] = '未知方式'
columns = [ 'rentType' , 'houseFloor' , 'houseToward' , 'houseDecoration' , 'communityName' , 'region' , 'plate' ]
for col in columns:
df[ col] = df[ col] . astype( 'category' )
tmp = df[ 'buildYear' ] . copy( )
tmp2 = tmp[ tmp!= '暂无信息' ] . astype( 'int' )
tmp[ tmp== '暂无信息' ] = tmp2. mode( ) . iloc[ 0 ]
df[ 'buildYear' ] = tmp
df[ 'buildYear' ] = df[ 'buildYear' ] . astype( 'int' )
df[ 'pv' ] . fillna( df[ 'pv' ] . mean( ) , inplace= True )
df[ 'uv' ] . fillna( df[ 'uv' ] . mean( ) , inplace= True )
df[ 'pv' ] = df[ 'pv' ] . astype( 'int' )
df[ 'uv' ] = df[ 'uv' ] . astype( 'int' )
df. drop( 'communityName' , axis= 1 , inplace= True )
df. drop( 'city' , axis= 1 , inplace= True )
return df
def washData ( df_train, df_test) :
"""
清洗数据
"""
df_train = df_train[ df_train[ 'area' ] <= 200 ]
df_train = df_train[ df_train[ 'tradeMoney' ] <= 20000 ]
df_train. drop( 'ID' , axis= 1 , inplace= True )
df_test. drop( 'ID' , axis= 1 , inplace= True )
return df_train, df_test
def feature ( df) :
"""
特征
"""
def parseRoom ( info, index) :
res = int ( info[ index* 2 ] )
return res
df. insert( 3 , '室' , None )
df. insert( 4 , '厅' , None )
df. insert( 5 , '卫' , None )
df[ '室' ] = df[ 'houseType' ] . apply ( parseRoom, index= 0 )
df[ '厅' ] = df[ 'houseType' ] . apply ( parseRoom, index= 1 )
df[ '卫' ] = df[ 'houseType' ] . apply ( parseRoom, index= 2 )
df[ '交易月份' ] = df[ 'tradeTime' ] . apply ( lambda x: int ( x. split( '/' ) [ 1 ] ) )
df. drop( 'houseType' , axis= 1 , inplace= True )
df. drop( 'tradeTime' , axis= 1 , inplace= True )
categorical_feats = [ 'rentType' , 'houseFloor' , 'houseToward' , 'houseDecoration' , 'region' , 'plate' ]
return df, categorical_feats
def getData ( feature) :
"""
获取数据
"""
train = pd. read_csv( 'train_data.csv' )
test = pd. read_csv( 'test_a.csv' )
train = parseData( train)
test = parseData( test)
train, test = washData( train, test)
train, col = feature( train)
test, col = feature( test)
target = train. pop( 'tradeMoney' )
features = train. columns
categorical_feats = col
return train, test, target, features, categorical_feats
train, test, target, features, categorical_feats = getData( feature)
D:\Users\Litchi\Anaconda3\lib\site-packages\ipykernel_launcher.py:5: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
"""
features
Index(['area', 'rentType', '室', '厅', '卫', 'houseFloor', 'totalFloor',
'houseToward', 'houseDecoration', 'region', 'plate', 'buildYear',
'saleSecHouseNum', 'subwayStationNum', 'busStationNum',
'interSchoolNum', 'schoolNum', 'privateSchoolNum', 'hospitalNum',
'drugStoreNum', 'gymNum', 'bankNum', 'shopNum', 'parkNum', 'mallNum',
'superMarketNum', 'totalTradeMoney', 'totalTradeArea', 'tradeMeanPrice',
'tradeSecNum', 'totalNewTradeMoney', 'totalNewTradeArea',
'tradeNewMeanPrice', 'tradeNewNum', 'remainNewNum', 'supplyNewNum',
'supplyLandNum', 'supplyLandArea', 'tradeLandNum', 'tradeLandArea',
'landTotalPrice', 'landMeanPrice', 'totalWorkers', 'newWorkers',
'residentPopulation', 'pv', 'uv', 'lookNum', '交易月份'],
dtype='object')
categorical_feats
['rentType', 'houseFloor', 'houseToward', 'houseDecoration', 'region', 'plate']
params = {
'num_leaves' : 31 ,
'min_data_in_leaf' : 20 ,
'min_child_samples' : 20 ,
'objective' : 'regression' ,
'learning_rate' : 0.01 ,
"boosting" : "gbdt" ,
"feature_fraction" : 0.8 ,
"bagging_freq" : 1 ,
"bagging_fraction" : 0.85 ,
"bagging_seed" : 23 ,
"metric" : 'rmse' ,
"lambda_l1" : 0.2 ,
"nthread" : 4 ,
}
folds = KFold( n_splits= 5 , shuffle= True , random_state= 2333 )
oof_lgb = np. zeros( len ( train) )
predictions_lgb = np. zeros( len ( test) )
feature_importance_df = pd. DataFrame( )
for fold_, ( trn_idx, val_idx) in enumerate ( folds. split( train. values, target. values) ) :
print ( "fold {}" . format ( fold_) )
trn_data = lgb. Dataset( train. iloc[ trn_idx] , label= target. iloc[ trn_idx] , categorical_feature= categorical_feats)
val_data = lgb. Dataset( train. iloc[ val_idx] , label= target. iloc[ val_idx] , categorical_feature= categorical_feats)
num_round = 10000
clf = lgb. train( params, trn_data, num_round, valid_sets = [ trn_data, val_data] , verbose_eval= 500 , early_stopping_rounds = 200 )
oof_lgb[ val_idx] = clf. predict( train. iloc[ val_idx] , num_iteration= clf. best_iteration)
fold_importance_df = pd. DataFrame( )
fold_importance_df[ "feature" ] = features
fold_importance_df[ "importance" ] = clf. feature_importance( )
fold_importance_df[ "fold" ] = fold_ + 1
feature_importance_df = pd. concat( [ feature_importance_df, fold_importance_df] , axis= 0 )
predictions_lgb += clf. predict( test, num_iteration= clf. best_iteration) / folds. n_splits
print ( "CV Score: {:<8.5f}" . format ( r2_score( target, oof_lgb) ) )
fold 0
Train until valid scores didn't improve in 200 rounds.
[500] training's rmse: 931.342 valid_1's rmse: 1001.7
[1000] training's rmse: 838.786 valid_1's rmse: 957.922
[1500] training's rmse: 782.81 valid_1's rmse: 941.005
[2000] training's rmse: 742.088 valid_1's rmse: 930.67
[2500] training's rmse: 709.892 valid_1's rmse: 925.214
[3000] training's rmse: 682.772 valid_1's rmse: 921.3
[3500] training's rmse: 659.414 valid_1's rmse: 918.183
[4000] training's rmse: 638.949 valid_1's rmse: 916.658
[4500] training's rmse: 620.26 valid_1's rmse: 915.573
[5000] training's rmse: 603.375 valid_1's rmse: 915.023
Early stopping, best iteration is:
[5100] training's rmse: 600.156 valid_1's rmse: 914.734
fold 1
Train until valid scores didn't improve in 200 rounds.
[500] training's rmse: 936.025 valid_1's rmse: 975.652
[1000] training's rmse: 840.817 valid_1's rmse: 932.943
[1500] training's rmse: 784.903 valid_1's rmse: 916.052
[2000] training's rmse: 743.215 valid_1's rmse: 907.209
[2500] training's rmse: 710.331 valid_1's rmse: 902.363
[3000] training's rmse: 682.643 valid_1's rmse: 899.242
[3500] training's rmse: 658.955 valid_1's rmse: 897.194
[4000] training's rmse: 638.818 valid_1's rmse: 895.997
[4500] training's rmse: 620.113 valid_1's rmse: 895.114
Early stopping, best iteration is:
[4675] training's rmse: 614.218 valid_1's rmse: 894.679
fold 2
Train until valid scores didn't improve in 200 rounds.
[500] training's rmse: 933.409 valid_1's rmse: 1005.77
[1000] training's rmse: 840.146 valid_1's rmse: 954.307
[1500] training's rmse: 784.712 valid_1's rmse: 932.187
[2000] training's rmse: 743.711 valid_1's rmse: 919.787
[2500] training's rmse: 710.892 valid_1's rmse: 912.114
[3000] training's rmse: 683.723 valid_1's rmse: 906.937
[3500] training's rmse: 660.831 valid_1's rmse: 903.181
[4000] training's rmse: 640.649 valid_1's rmse: 901.41
[4500] training's rmse: 622.107 valid_1's rmse: 899.159
[5000] training's rmse: 605.354 valid_1's rmse: 898.173
[5500] training's rmse: 590.722 valid_1's rmse: 897.163
[6000] training's rmse: 576.628 valid_1's rmse: 896.439
[6500] training's rmse: 563.883 valid_1's rmse: 895.71
[7000] training's rmse: 552.041 valid_1's rmse: 895.343
Early stopping, best iteration is:
[6946] training's rmse: 553.261 valid_1's rmse: 895.299
fold 3
Train until valid scores didn't improve in 200 rounds.
[500] training's rmse: 927.549 valid_1's rmse: 1012.27
[1000] training's rmse: 831.644 valid_1's rmse: 964.079
[1500] training's rmse: 775.929 valid_1's rmse: 945.962
[2000] training's rmse: 734.603 valid_1's rmse: 937.228
[2500] training's rmse: 701.36 valid_1's rmse: 930.409
[3000] training's rmse: 674.453 valid_1's rmse: 926.819
[3500] training's rmse: 651.394 valid_1's rmse: 923.885
[4000] training's rmse: 631.25 valid_1's rmse: 921.569
[4500] training's rmse: 612.841 valid_1's rmse: 920.702
[5000] training's rmse: 596.24 valid_1's rmse: 920.094
Early stopping, best iteration is:
[5291] training's rmse: 587.702 valid_1's rmse: 919.704
fold 4
Train until valid scores didn't improve in 200 rounds.
[500] training's rmse: 927.713 valid_1's rmse: 1015.9
[1000] training's rmse: 837.015 valid_1's rmse: 971.835
[1500] training's rmse: 780.893 valid_1's rmse: 951.545
[2000] training's rmse: 740.199 valid_1's rmse: 940.376
[2500] training's rmse: 707.811 valid_1's rmse: 934.12
[3000] training's rmse: 681.413 valid_1's rmse: 930.279
[3500] training's rmse: 658.231 valid_1's rmse: 928.134
[4000] training's rmse: 638.105 valid_1's rmse: 926.649
[4500] training's rmse: 619.808 valid_1's rmse: 925.475
[5000] training's rmse: 603.03 valid_1's rmse: 924.849
[5500] training's rmse: 588.098 valid_1's rmse: 924.424
[6000] training's rmse: 574.53 valid_1's rmse: 923.822
Early stopping, best iteration is:
[6239] training's rmse: 568.242 valid_1's rmse: 923.257
CV Score: 0.89181
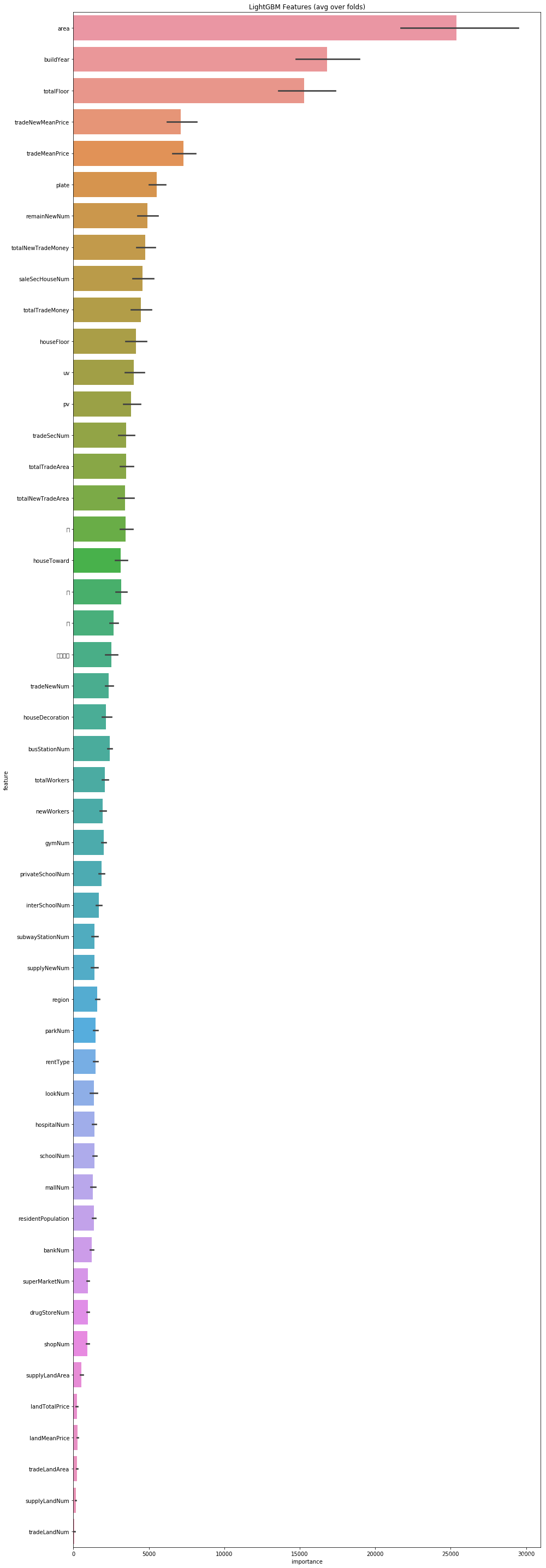
cols = ( feature_importance_df[ [ "feature" , "importance" ] ]
. groupby( "feature" )
. mean( )
. sort_values( by= "importance" , ascending= False ) [ : 1000 ] . index)
best_features = feature_importance_df. loc[ feature_importance_df. feature. isin( cols) ]
plt. figure( figsize= ( 14 , 40 ) )
sns. barplot( x= "importance" ,
y= "feature" ,
data= best_features. sort_values( by= "importance" ,
ascending= False ) )
plt. title( 'LightGBM Features (avg over folds)' )
plt. tight_layout( )
D:\Users\Litchi\Anaconda3\lib\site-packages\scipy\stats\stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.
return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval
pd. DataFrame( predictions_lgb) . apply ( round ) . to_csv( 'submit.csv' , na_rep= '\n' , index= False , encoding= 'utf8' , header= False )
pred = pd. read_csv( "submit.csv" , engine = "python" , header= None )
print ( "预测结果最大值:{}" . format ( pred. max ( ) ) )
print ( "预测结果最小值:{}" . format ( pred. min ( ) ) )
conmbine1 = pd. read_csv( "sub_a_913.csv" , engine = "python" , header= None )
score1 = r2_score( pred, conmbine1)
print ( '预测分数为:{}' . format ( score1) )
预测结果最大值:0 18384.0
dtype: float64
预测结果最小值:0 1204.0
dtype: float64
预测分数为:0.9456036247279659