什么是堆
在计算机科学中堆是一种很有趣的数据结构,实际上通常用数组来存储堆中的元素,但是我们却可以把数组中元素视为树,如图所示:

这就是一个普通的数组,但是我们可以将其看做如下图所示的树:

这是怎么做到的呢?
原来虽然我们是在数组中存储的堆元素,但是这里面有一条隐藏的规律,如果你仔细看上图就会发现:
- 每一个左子树节点的下标是父节点的2倍
- 每一个右子树节点的下标是父节点的2倍再加1
也就是说在数组中实际上隐藏了上面的这两条规律,如图所示:

堆这种数据结构最棒的地方在于我们无需像树一样存储左右子树的信息,而只需要通过下标运算就可以轻松的找到一个节点的左子树节点、右子树节点以及父节点,如下所示,相对于树这种数据结构来说堆更加节省内存。
int parent(int i){ // 计算给定下标的父节点
return i/2;
}
int left(int i){ // 计算给定下标的左子树节点
return 2*i;
}
int right(int i){ // 计算给定下标的右子树节点
return 2*i+1;
}
除了上述数组下标上的规律以外,你还会发现堆中的每一个节点的值都比左右子树节点大,这被称为大根堆,即对于大根堆来说以下一定成立:
array[i] > array[left(i)] && array[i] > array[right(i)] == true
相应的如果堆中每个一节点的值都比左右子树节点的值小,那么这被称为小根堆,即对于小根堆来说以下一定成立:
array[i] < array[left(i)] && array[i] < array[right(i)] == true
以上就是堆这种数据结构的全部内容了。
那么接下来的问题就是,给定一个数组,我们该如何将数组中的值调整成一个堆呢?
如何在给定数组上创建堆
在这里我们以大根堆为例来讲解如何在给定数组上创建一个堆。
给定数组的初始状态如下图a所示,从图中我们看到除array[2]之外其它所有节点都满足大根堆的要求了,接下来我们要做的就是把array[2]也调整成为大根堆,那么该怎么调整呢?

很简单,我们只需要将array[2]和其左右子树节点进行比较,最大的那个和array[2]进行交换,如图b所示,array[2]和其左子树array[4]以及右子树array[5]中最大的是array[4],这样array[2]和array[4]进行交换,这样array[2]就满足大根堆的要求了,如图b所示;
但此时array[4]不满足要求,怎么办呢?还是重复上面的过程,在array[4]的左子树和右子树中选出一个最大的和array[4]交换,最终我们来到了图c,此时所有元素都满足了堆的要求,这个过程就好比石子在水中下沉,一些资料中将这个过程称形象的称为“shift down”。
现在我们知道了假设堆中有一个元素i不满足大根堆的要求,那么该如何调整呢:
void keep_max_heap(int i){
int l = left(i);
int r = right(i);
int larget = i;
if (l < heap_size && array[l] > array[i])
larget = l;
if (r < heap_size && array[r] > array[larget])
larget = r;
if (larget != i){
swap(array[larget], array[i]);
max_heap(larget);
}
}
以上代码即keep_max_heap函数就是刚才讲解调整节点的过程,该过程的时间复杂度为O(logn)。
但是到目前为止我们依然不知道该如何在给定的数组上创建堆,不要着急,我们首先来观察一下给定的数组的初始状态,如图所示:

实际上堆是一颗完全二叉树,那么这对于我们来说有什么用呢?这个性质非常有用,这个性质告诉我们要想将一个数组转换为堆,我们只需要从第一个非叶子节点开始调整即可。
那么第一个非叶子节点在哪里呢?假设堆的大小为heap_size,那么第一个非叶子节点就是:
heap_size / 2;
可这是为什么呢?原因很简单,因为第一个非叶子节点总是最后一个节点的父节点,因此第一个非叶子节点就是:
parent(heap_size) == heap_size / 2
有了这些准备知识就可以将数组转为堆了,我们只需要依次在第一个非叶子节点到第二个节点上调用一下keep_max_heap就可以了:
void build_max_heap() {
for (int i = heap_size/2; i>=1; i--)
keep_max_heap(i);
}
这样,一个堆就建成了。
增加堆节点以及删除堆节点
对于堆这种数据结构来说除了在给定数组上创建出一个堆之外,还需要支持增加节点以及删除节点的操作,在这里我们依然以大根堆为例来讲解,首先来看删除堆节点。
删除节点
删除堆中的一个节点实际用到的正是keep_max_heap这个过程,假设删除的是节点i,那么我只需要将节点i和最后一个元素交换,并且在节点i上调用keep_max_heep函数就可以了:
void delete_heep_node(int i) {
swap(array[i], array[heap_size]);
--heap_size;
keep_max_heap(i);
}
注意在该过程中不要忘了将堆的大小减一。
增加节点
增加堆中的一个节点相对容易,如图所示,假设堆中新增了一个节点16,那么该如何位置堆的性质呢?很简单,我们只需要将16和其父节点进行比较,如果不符合要求就交换,并重复该过程直到根节点为止,这个过程就好比水中的气泡上浮,有的资料也将这个过程形象的称为“shift up”,该过程的时间复杂度为O(logn)。
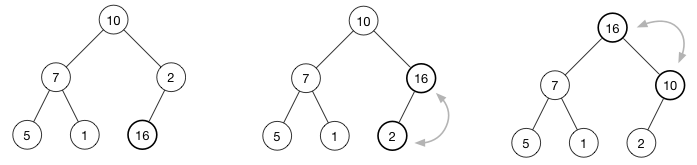
用代码表示就是如下add_heap_node函数:
void add_heap_node(int i){
if (i == 0)
return;
int p = parent(i);
if(array[i] > array[p]) {
swap(array[i], array[p]);
add_heap_node(p);
}
}
至此,关于堆的性质、堆的创建以及增删就讲解完毕了,接下来我们看一下堆这种数据结构都可以用来做些什么。
堆的应用
在这一节中我们介绍三种堆常见的应用场景。
排序
有的同学可能会有疑问,堆这种数据结构该如何来排序呢?
让我们来仔细想一想,对于大根堆来说其性质就是所有节点的值都比其左子树节点和右子树节点的值要大,那么我们很容易得出以下结论,对于大根堆来说:
堆中的第一个元素就是所有元素的最大值。
有了这样一个结论就可以将堆应用在排序上了:
- 将大根堆中的第一个元素和最后一个元素交换
- 堆大小减一
- 在第一个元素上调用keep_max_heap维持大根堆的性质
这个过程能进行排序是很显然的,实际上我们就是不断的将数组中的最大值放到数组最后一个位置,次大值放到最大值的前一个位置,利用的就是大根堆的第一个元素是数组中所有元素最大值这个性质。
用代码表示就如下所示:
void heap_sort(){
build_max_heap();
for(int i=heap_size-1;i>=1;i--){
swap(array[0],array[i]);
--heap_size;
keep_max_heap(0);
}
}
执行完heap_sort函数后array中的值就是有序的了,堆排序的时间复杂度为O(nlogn)。
求最大(最小)的K个数
对于给定数组如何求出数组中最大的或者最小的K个数,有的同学可能觉得非常简单,不就是排个序然后就得到最大的或最小的K个数了吗,我们知道,排序的时间复杂度为O(nlogn),那么有没有什么更快的方法吗?
答案是肯定的,堆可以来解决这个问题,在这里我们以求数组中最小的K个值为例。
对于给定的数组,我们可以将数组中的前k个数建成一个大根堆,注意是大根堆,建成大根堆后array[0]就是这k个数中的最大值;
接下来我们依次将数组中K+1之后的元素依次和array[0]进行比较:
- 如果比array[0]大,那么我们知道该元素一定不属于最小的K个数;
- 如果比array[0]小,那么我们知道array[0]就肯定不属于最小的K个数了,这时我们需要将该元素和array[0]进行交换,并在位置0上调用keep_max_heap函数维护大根堆的性质
这样比较完后堆中的所有元素就是数组中最小的k个数,整个过程如下所示:
void get_maxk(int k) {
heap_size = k; // 设置堆大小为k
build_max_heap(); // 创建大小为k的堆
for(int i=k;i<array.size();i++){
if(array[i] >= array[0]) // 和堆顶元素进行比较,小于堆顶则处理
continue;
array[0] = array[i];
keep_max_heap(0);
}
}
那么对于求数组中最大的k个数呢,显然我们应该建立小根堆并进行同样的处理。
注意使用堆来求解数组中最小K个元素的时间复杂度为O(nlogk),显然k<n,那么我们的算法优于排序算法。
定时器是如何实现的
我们要讲解的堆的最后一个应用是定时器,timer。
定时器相信有的同学已经使用过了,定义一个timer变量,传入等待时间以及一个回调函数,到时后自动调用我们传入的回调函数,是不是很神奇,那么你有没有好奇过定时器到底是怎么实现的呢?
我们先来看看定时器中都有什么,定时器中有两种东西:
- 一个是我们传入的时延,比如传入2那就是等待2秒钟;传入10就是等待10秒钟;
- 另一个是我们传入的回调函数,当定时器到时之后调用回调函数。
因此我们要做的就是在用户指定的时间之后调用回调函数,就这么简单;为做到这一点,显然我们必须知道什么时间该调用用户传入的回调函数。
最简单的一种实现方式是链表,我们将用户定义的定时器用链表管理起来,并按照等待时间大小降序链接,这样我们不断检查链表中第一个定时器的时间,如果到时后则调用其回调函数并将其从链表中删除。
链表的这种实现方式比较简单,但是有一个缺点,那就是我们必须保持链表的有序性,在这种情况下向链表中新增一个定时器就需要遍历一边链表,因此时间复杂度为O(n),如果定时器很多就会有性能问题。
那么该怎样改进呢?
初看起来,堆这种数据结构和定时器八竿子打不着,但是如果你仔细想一想定时器的链表实现就会看到,我们实际上要找的仅仅就是时延最短的那一个定时器,链表之所以有序就是为此目的服务的,那么要得到一个数组中的最小值我们一定要让数组有序才可以吗?
实际上我们无需维护数组的有序就可以轻松得到数组的最小值,答案就是刚学过的小根堆。
只要我们将所有的定时器维护成为一个小根堆,那么我们就可以很简单的获取时延最小的那个定时器(堆顶),同时向堆中新增定时器无需遍历整个数组,其时间复杂度为O(logn),比起链表的实现要好很多。
首先我们看一下定时器的定义:
typedef void (*func)(void* d);
class timer
{
public:
timer(int delay, void* d, func cb) {
expire = time(NULL) + delay; // 计算定时器触发时间
data = d;
f = cb;
}
~timer(){}
time_t expire; // 定时器触发时间
void* data; // timer中所带的数据
func f; // 操作数据的回调函数
int i; // 在堆中的位置
};
该定时器的定义非常简单,用户需要传入时延,回调函数以及回调函数的参数,注意在定时器内部我们记录的不是时延,而是将时延和当前的时间进行加和从而得到了触发定时器的时间,这样在处理定时器时只需要简单的比较当前时间和定时器触发时间的大小就可以了,同时使用i来记录该timer在堆中的位置。
至于堆我们简单的使用vector而不是普通的数组,这样数组的扩增问题就要交给STL了 ?
注意在这里定时器是从无到有一个一个加入到堆的,因此在向堆中加入定时器时就开始维护堆的性质,如下即为向堆中增加定时器add_timer函数:
void add_timer(timer* t){
if (heap_size == timers.size()){
timers.push_back(t);
} else {
timers[heap_size]=t;
}
t->i = heap_size;
++heap_size;
add_heap_node(heap_size-1);
}
当我们删除定时器节点时同样简单,就是堆的节点删除操作:
void del_timer(timer* t){
if (t == NULL || heap_size == 0)
return;
int pos = t->i;
swap_pos(timers[pos], timers[heap_size-1]); // 注意不要忘了交换定时器下标
swap(timers[pos], timers[heap_size-1]);
--heap_size;
keep_min_heap(pos); // 该函数实现请参见大根堆的keep_max_heap
}
当我可以向堆中增加删除定时器节点后就可以开始不断检测堆中是否有定时器超时了:
void run(){
while(heap_size) {
if (time(NULL) < timers[0]->expire) // 注意这里会导致CPU占用过高
continue; // 真正使用时应该调用相应函数挂起等待
if (timers[0]->f)
timers[0]->f(timers[0]->data); // 调用用户回调函数
del_timer(timers[0]);
}
}
注意在这种简单的实现方式下,当堆中没有定时器超时时会存在while循环的空转问题从而导致CPU使用率上升,在真正使用时应该调用相关的函数挂起等待。
总结
堆是一种性质非常优良的数据结构,在计算机科学中有着非常广泛的应用,希望大家能通过这篇文章掌握这种数据结构。
如果你喜欢这篇文章,欢迎关注微信公共账号:码农的荒岛求生,获取更多精彩内容。

计算机基础决定程序员职业生涯高度
