(作者:陈玓玏 data-master)
spark-sql任务跑着跑着,碰到一个bug:
Container on host: was preempted
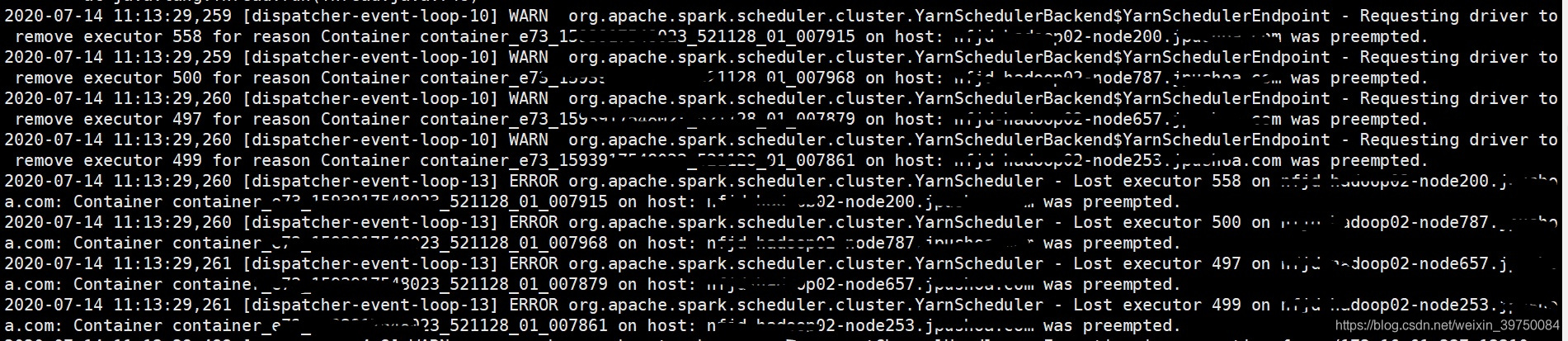
又是一个新鲜的bug呢!!
一通查资料,得出一个初步结论:因为我的任务,其中有task占用的内存太大,而我们的yarn又是使用的公平调度机制,当有新任务来的时候,我的task对应的容器就会被别的任务抢占。
于是就简单了解下yarn的公平调度机制。yarn有先入先出调度器,容量调度器,公平调度器三种调度器。
先入先出调度器,先来的任务先执行,任务非常多,或者有的任务非常大的情况下,其他任务就苦了。
容量调度器,专门为小任务开辟了队列,不会抢占容器,因此任务非常多的时候,还是first in first out。
公平调度器,允许抢占容器。资源比较充足的情况下,新任务启动时,会等之前的任务阶段性使用资源释放出来,才会分老任务的资源。但是在资源不足的情况下,占用资源超过公平份额的容器,就可能被强制中断,把容器分配给占用资源未超过公平份额的容器。这个公平份额和使用份额,在spark web ui上可以看到。
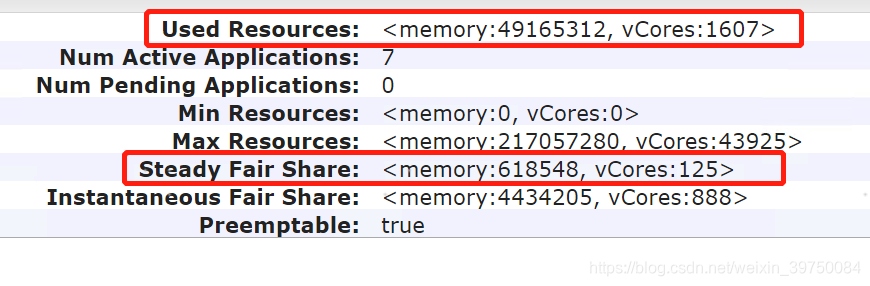
至于解决的办法,我自己觉得,
1)要么就是资源紧张的时候,别挂任务,或者挂任务别挂spark任务,挂hive,嫌慢的话就多开些并发,hive就算多开并发也不会像spark一样自己互相抢占资源。
2)要么就是,好好看看自己的代码,看是不是能有些方法优化一下,减少不必要的数据,或者减少不必要的关联/操作,避免一个task中数据过多。
3)再不然,就只能改yarn的参数了,让资源抢占的门限值变高些。
这个错误也不一定会使得任务失败,有时候只是告警,会重启别的容器来执行失败的任务。
参考资料:
- 牵扯到yarn调度:https://blog.csdn.net/zhanyuanlin/article/details/71516286;
- 调度中的抢占机制,https://blog.csdn.net/bujiujie8/article/details/86713115(这篇写得比较好)
- https://www.mail-archive.com/[email protected]/msg101196.html
- https://blog.csdn.net/m0_37885286/article/details/106674721