1.不加 join() 的结果
我们让 Thread1 线程工作的耗时增加.
import time
def thread_job():
print('===============Thread1 Starting====================\n')
for i in range(10):
time.sleep(1)
print('====================Thread1 Finished===============\n')
def main():
added_thread = threading.Thread(target = thread_job, name = 'Thread1')
added_thread.start()
print('===============All Have Been Done==================\n')
if __name__ == "__main__":
main()
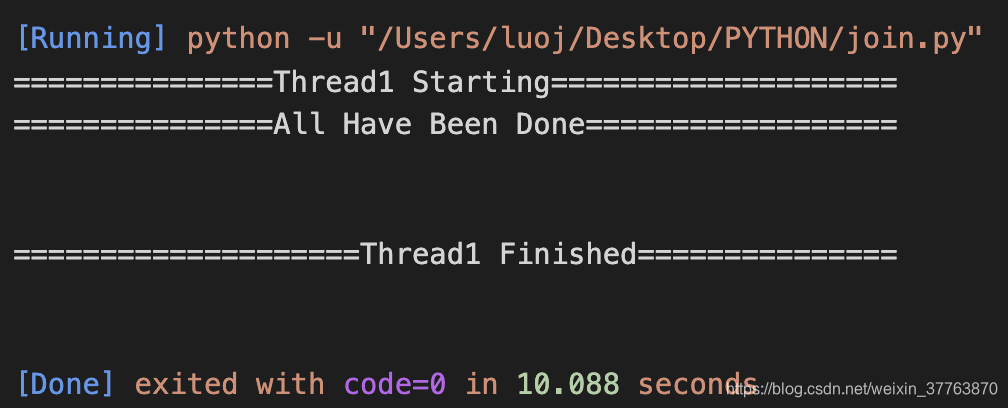
预想中输出的结果是否为:
=Thread1 Starting======
Thread1 Finished=
=All Have Been Done
但实际确为:
=Thread1 Starting====
=All Have Been Done====
======Thread1 Finished=
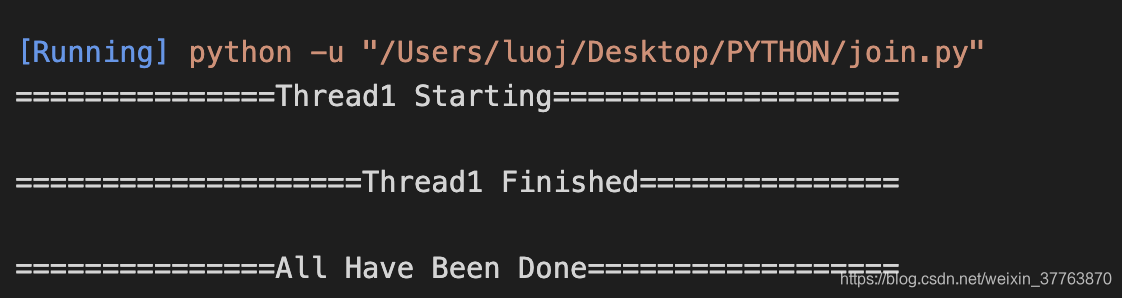
2.加入 join() 的结果
线程任务还未完成便输出All Have Been Done。如果要遵循顺序,可以在启动线程后对它调用join:
added_thread.start()
added_thread.join()
print("===============All Have Been Done==================\n")
import threading
import time
def thread_job():
print('===============Thread1 Starting====================\n')
for i in range(10):
time.sleep(1)
print('====================Thread1 Finished===============\n')
def main():
added_thread = threading.Thread(target = thread_job, name = 'Thread1')
added_thread.start()
added_thread.join()
print('===============All Have Been Done==================\n')
if __name__ == "__main__":
main()
使用join对控制多个线程的执行顺序非常关键。举个例子,假设我们现在再加一个线程Thread2,Thread2的任务量较小,会比Thread1更快完成:
import threading
import time
def thread_job():
print('===============Thread1 Starting====================\n')
for i in range(10):
time.sleep(1)
print('====================Thread1 Finished===============\n')
def thread2_job():
print('===============Thread2 Starting====================\n')
print('====================Thread2 Finished===============\n')
def main():
added_thread = threading.Thread(target = thread_job, name = 'Thread1')
added_thread2 = threading.Thread(target = thread2_job, name = 'Thread2')
added_thread.start()
added_thread2.start()
#added_thread.join()
print('===============All Have Been Done==================\n')
if __name__ == "__main__":
main()
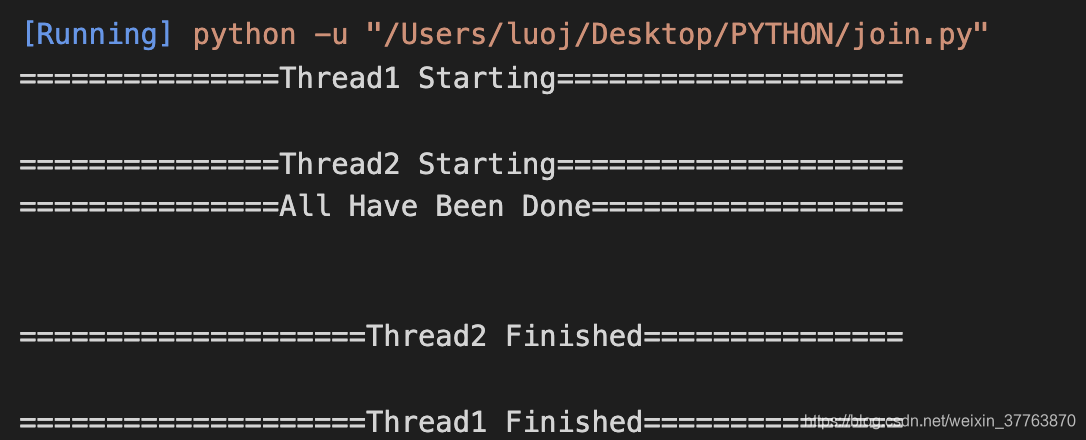
现在Thread1和Thread2都没有join,注意这里说”一种”是因为All Have Been Done的出现完全取决于两个线程的执行速度, 完全有可能Thread2 finish出现在All Have Been Done之后。这种杂乱的执行方式是我们不能忍受的,因此要使用join加以控制。
我们试试在Thread1启动后,Thread2启动前加上thread_1.join():
import threading
import time
def thread_job():
print('===============Thread1 Starting====================\n')
for i in range(10):
time.sleep(1)
print('====================Thread1 Finished===============\n')
def thread2_job():
print('===============Thread2 Starting====================\n')
print('====================Thread2 Finished===============\n')
def main():
added_thread = threading.Thread(target = thread_job, name = 'Thread1')
added_thread2 = threading.Thread(target = thread2_job, name = 'Thread2')
added_thread.start()
added_thread.join()
added_thread2.start()
#added_thread.join()
print('===============All Have Been Done==================\n')
if __name__ == "__main__":
main()
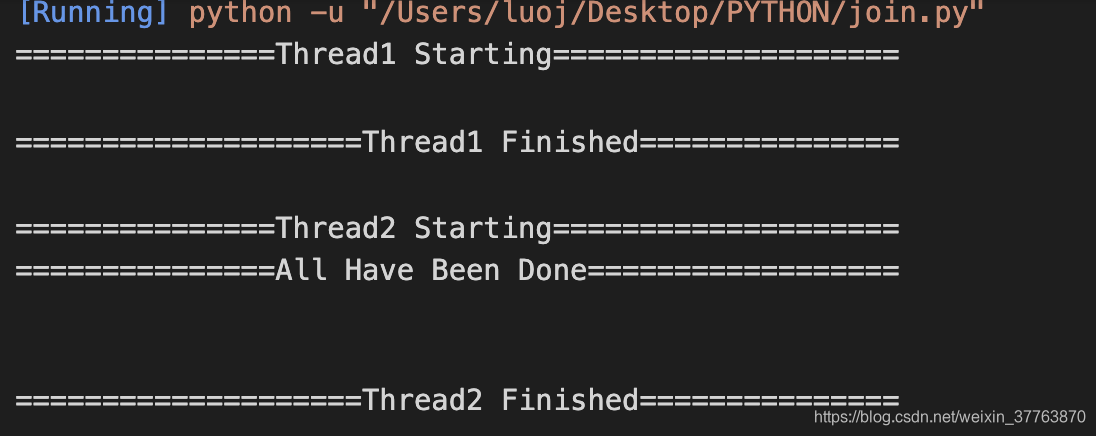
可以看到,Thread2会等待Thread1结束后才开始运行。
如果我们在Thread2启动后放上added_thread.join()会怎么样呢?
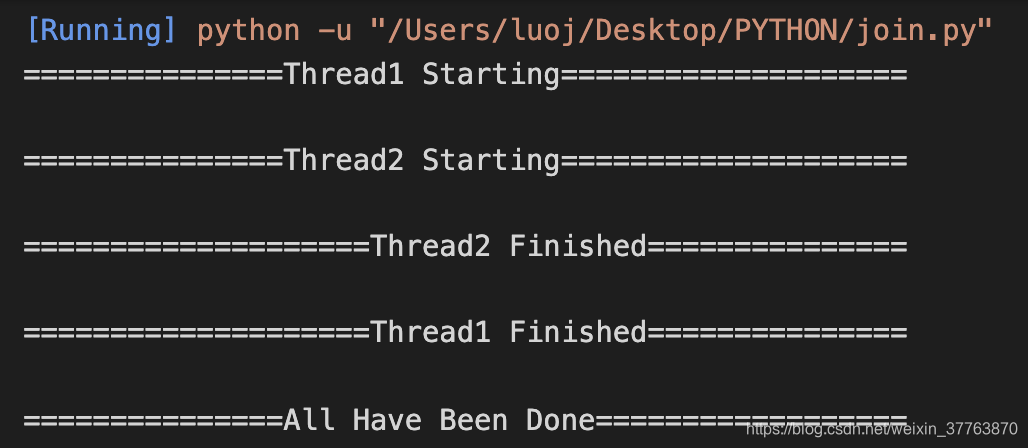
Thread2在Thread1之后启动,并且因为Thread2任务量小会在Thread1之前完成;而Thread1也因为加了join,All Have Been Done在它完成后才显示。
你也可以添加thread_2.join()进行尝试,但为了规避不必要的麻烦,推荐如下这种1221的V型排布:
import threading
import time
def thread_job():
print('===============Thread1 Starting====================\n')
for i in range(10):
time.sleep(1)
print('====================Thread1 Finished===============\n')
def thread2_job():
print('===============Thread2 Starting====================\n')
print('====================Thread2 Finished===============\n')
def main():
added_thread = threading.Thread(target = thread_job, name = 'Thread1')
added_thread2 = threading.Thread(target = thread2_job, name = 'Thread2')
added_thread.start()
added_thread2.start()
added_thread2.join()
added_thread.join()
print('===============All Have Been Done==================\n')
if __name__ == "__main__":
main()
