文章目录
Partition
为什么需要Partition
由于hive执行一条简单的sql都会查询整个表,所以当表的数据量非常大时查询速度会很慢。
基于此Hive可以将表划分为几个分区,即将表基于某些分区列划分为几个部分。每个表可以有一个或者多个分区。例如,有一个员工信息表,如果根据部门来分区的话,那么查询department="A"时就只需要去部门为A的分区数据中找即可,而不用扫描整个表了,极大地提高了查询的性能。
如何创建Partition
下面是整个建表语句,不仅仅包括分区,还包括bucket等
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [column_constraint_specification] [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
例如,创建如下的分区表,其中以yoj来作为分区列,yoj表示year of join
create external table test_part(
id int, name string, dept string)
partitioned by(yoj string)
row format delimited fields terminated by ','
stored as textfile;
创建两个输入文件
/root/python_dirs/year/2009目录下有文件file2, 内容如下
1, sunny, SC
2, animesh, HR
/root/python_dirs/year/2010目录下有文件file3, 内容如下
3, sumeer, SC
4, sarthak, TP
分别将两个文件导入到分区表里
load data local inpath '/root/python_dirs/year/2009/file2' into table test_part partition(yoj='2009');
load data local inpath '/root/python_dirs/year/2010/file3' into table test_part partition(yoj='2010');
然后通过show partitions test_part可查看当前test_part表有哪些分区
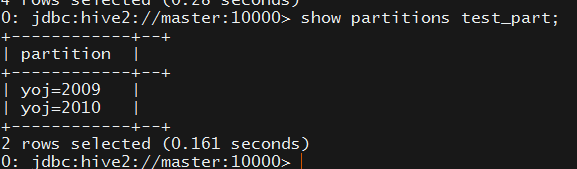
在hdfs上对应的就是两个目录yoj=2009和yoj=2010

可通过alter table test_part drop if exists partition(yoj="2010");来删除分区数据

Partition的两种类型 static VS dynamic
两种类型的区别在于如何导入分区数据。通常在将大文件加载到Hive表中时,静态分区是首选。但是,如果你不知道有几个分区,那么此时就可以选择动态分区。以上面的例子简要说明下,我们知道有两个文件内容分别属于yoj=2009和yoj=2010,所以需要手动导入两次,那么如果我有10个不同的yoj的值呢?那么我们就需要手动导入10次,这时我们就可以选择动态分区。
生成测试数据
假设我们有如下一张经过清洗后的信息表student_dwd_ext,可以认为是一张宽表。
create external table student_dwd_ext(
id int, name string, sex string, age int, id_card string,
address string, phone_number string, job string,
company string, graduation_time string)
row format delimited fields terminated by '\t'
stored as textfile
location '/opt/wacos/student';
下面是通过faker来生成测试数据的代码,需要通过pip install faker来安装所需要的依赖包
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# **********************************************
#
# Filename: generate_student_data.py
#
# Author: WangTian
# Description: 批量生成学生数据
# Create: 2020-03-03 21:19:30
# Last Modified: 2020-03-03 21:19:30
#
# **********************************************
from faker import Faker
import sys
from threading import Thread
def generate_stu_by_index(start, end, faker, file_name):
'''
生成id在start和end之间的学生数据
start : int
end : int
faker : 外部传进来, Faker类的实例对象, locale=“zh_CN”
file_name : string 要生成的文件名
'''
file_handler = open(file_name, mode="w")
id = start
f = faker
while(id <= end):
f = Faker(locale="zh_CN")
name = f.name()
sex = f.random_element(elements=("男", "女"))
age = f.random_int(min=20, max=40)
id_card = f.ssn()
address = f.address().split(" ")[0]
phone_number = f.phone_number()
job = f.job()
company = f.company()
graduation_time = f.random_element(
elements=("2012", "2013", "2014", "2015", "2016"))
row = "\t".join([str(id), name, sex, str(age), id_card,
address, phone_number, job, company,
graduation_time])
file_handler.write(row+"\n")
id = id+1
file_handler.close()
class run_thread(Thread):
def __init__(self, id, start, end, faker, file_name):
Thread.__init__(self)
self._id = id
self._start = start
self._end = end
self._faker = faker
self._file_name = file_name
def run(self):
print("threadid={}, starting......".format(self._id))
generate_stu_by_index(self._start, self._end,
self._faker, self._file_name)
print("threadid={}, exit......".format(self._id))
print("threadid={}, has generated {} rows, the generated file is {}".format(
self._id, (self._end-self._start+1), self._file_name))
def multithread_generate(num):
'''
多线程生成学生数据文件
num : 线程数
'''
i = 1
len = 100
faker = Faker(locale="zh_CN")
while(i <= num):
start = len*(i-1)+1
end = len*i
run = run_thread(i, start, end, faker,
"{}_{}_{}.txt".format(i, start, end))
run.start()
i = i+1
def main(num):
'''
main方法
'''
multithread_generate(num)
if __name__ == "__main__":
print sys.getdefaultencoding()
reload(sys)
sys.setdefaultencoding('utf8')
print sys.getdefaultencoding()
main(int(sys.argv[1]))
上面的代码保存并命名为generate_student_data.py
执行python generate_student_data.py 20来生成2000条数据,其中20表示开启20个线程,每个线程生成100条数据。执行完后部分结果截图如下所示。

执行load data local inpath '/root/python_dirs/*.txt' overwrite into table student_dwd_ext;将生成的2000条数据导入到student_dwd_ext表里,如下所示

动态分区验证
创建一个分区表,以graduation_time来作为分区列
create table student_part(
id int, name string, sex string, age int, id_card string,
address string, phone_number string, job string,
company string)
partitioned by(graduation_time string)
row format delimited fields terminated by '\t'
stored as textfile;
然后通过动态分区的方式导入数据,但是必须要开启动态分区的设置,否则会报如下图所示的错误。
# 开启动态分区的设置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions=1000;
set hive.exec.max.dynamic.partitions.pernode=100;
insert into table student_part partition(graduation_time)
select * from student_dwd_ext;

然后对结果进行了如下的验证
select count(*),graduation_time from student_dwd_ext group by graduation_time;
select count(*) from student_part where graduation_time="2012";
select count(*) from student_part where graduation_time="2013";
show partitions student_part;


Bucket
为什么要引入Bucket
我们知道Hive的Partition已经可以将表分隔成多个文件(或目录),但是,Partition只是在如下两个场景中有明显的效果
- 有限的分区数
- 分区之间数据大小几乎是相等的
例如,当我们以country来进行分区时,大国对应的分区数据就很大,小国对应的分区数据就很小,那么此时Partition就不是太理想了。
为了解决这个问题,Hive提出了Bucketing的概念。这是一种非常有效的技术,能将表的数据分成大小几乎相同的易于管理的多个部分。
特点及优点
Bucketing是通过对bucketed column做hash function然后mod number of buckets。
通过CLUSTERED BY语句将表分为多个buckets。
每个bucket是表目录的一个文件。
Bucketing可以和Partitioning一起使用,也可以单独使用
Bucketing有如下几个优点
- 将表的数据分成大小几乎相同的几部分
- 相对于没有做bucket的表利于做
sampling map side join会更快
同样地,Bucketing也有缺点,就是在导入数据到bucket table时需要手工指定和导入,而且导入的时间会比导入数据到Partition表要长,因为数据要均匀分配嘛。
创建Bucket
如下所示,clustered by指定id来做bucket,然后通过sorted by来在bucket文件里做排序。
其中clustered by和sorted by的字段必须要在表的创建定义里定义好,这里是Partitioning不同的地方
create table student_bucket_part(
id int, name string, sex string, age int, id_card string,
address string, phone_number string, job string,
company string)
partitioned by(graduation_time string)
clustered by (id) sorted by (age) into 16 buckets
row format delimited fields terminated by '\t'
stored as textfile;
导入数据。如果不能成功导入到bucket表的话,可能需要显示打开bucket
set hive.enforce.bucketing=true; 2.x的版本已经不需要
insert into table student_bucket_part partition(graduation_time)
select * from student_dwd_ext;
查看HDFS,能发现如下所示,每个bucket就是一个单独的文件

Table Sampling VS limit
hive里的Table Sampling是从原始的大数据集中抽取小部分数据,和limit非常相似。
但它们之间是有不同点的。大多数情况下,limit会执行全表扫然后指定数目的结果,但是Sampling会选取一部分数据来执行查询。
关于tablesample bucket x out of y的说明,y一般来说是bucket num的整数倍
假如bucket num为32
TABLESAMPLE(BUCKET 6 OUT OF 8)就表示分成8个bucket为一组,然后就选取每组的第6个即6, 14, 22, 30这4个编号的bucket
TABLESAMPLE(BUCKET 23 OUT OF 32)就表示分成32个bucket为一组,然后就选取第23个bucket
TABLESAMPLE(BUCKET 3 OUT OF 64)就表示64个bucket为一组,然后就选取第3个
select id,name,sex,age,job,graduation_time from student_bucket_part
tablesample(bucket 10 out of 128) where age between 20 and 30;

Partition和Bucket数据模型图示

Join
介绍
hive的join和sql的join是非常类似的,都是将多个表连接起来获取更多的字段信息。关于Hive Join我们需要知道以下几点:
- 只有
Equality join才是被允许的,即join里的on语句只能有等于和不等于。 - 一个
query语句里可以有超过2张表来进行join,这是和sql join保持一致的。 - 有
LEFT, RIGHT, FULL OUTER join,这是和sql join保持一致的,不过mysql没有full join。 Joins are NOT commutative! Joins are left-associative regardless of whether they are LEFT or RIGHT joins,意思是a join b和b join a是不同的,这不同于数学上的加法交换律,顺序不同,哪个表去stream也是不同的,关于stream后面有介绍。不管是LEFT JOIN还是RIGHT JOIN都是从左开始join表的,至于数据以哪张表为主就看是LEFT JOIN还是RIGHT JOIN。
完整的join语法如下
join_table:
table_reference [INNER] JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
| table_reference CROSS JOIN table_reference [join_condition] (as of Hive 0.10)
table_reference:
table_factor
| join_table
table_factor:
tbl_name [alias]
| table_subquery alias
| ( table_references )
join_condition:
ON expression
Hive Join有四种类型,如下图所示,和sql join是保持一致的,具体各个join是什么意思我就不在这里赘述。

官方的join exmaples
- 如下的join语句都是正确的
SELECT a.* FROM a JOIN b ON (a.id = b.id)
SELECT a.* FROM a JOIN b ON (a.id = b.id AND a.department = b.department)
SELECT a.* FROM a LEFT OUTER JOIN b ON (a.id <> b.id)
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
- 如果join子句对于每个表都使用相同的列,则Hive将多个表上的join转换为单个map/reduce作业。
例如,下面的join语句的on条件里都有b.key1,所以该join会转换成一个MR作业
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
例如,下面的join语句的on条件里没有相同的列,所以会转换成两个MR作业。 第一个MR作业是a join b,然后a join b的结果和c做join作为第二个MR作业。
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
- 在join的每个MR阶段,最后一个表都是通过
reducer传递的,其他前面的表被缓存到内存里。因此将大表放在最后面是可以减少内存消耗的。
例如,下面的join语句会转换成一个MR作业,a和b表的数据就会被缓存到内存里,c表通过reducer传递
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
例如,下面的join语句会转换成两个MR作业。第一个MR作业缓存a表数据,b表通过reducer传递;第二个MR作业缓存a join b的结果数据,c表通过reducer传递
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
- 在join的每个MR阶段,要传递(
stream)的表是可以显示指定的
例如,下面的join语句会转换成一个MR作业,如果不指定/*+ STREAMTABLE(a) */,默认是c表去stream,a和b表的数据就会被缓存到内存。现在指定了/*+ STREAMTABLE(a) */,所以是b和c表的数据就会被缓存到内存,a表通过reducer传递。
如果没有显示指定STREAMTABLE,默认要stream的表是最后一个。
SELECT /*+ STREAMTABLE(a) */ a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
LEFT, RIGHT, and FULL OUTER join对于匹配不成功的时候是非常有效的,实际工作经常用
例如,下面的LEFT OUTER JOIN语句对于a表的每行数据都会有返回结果。如果有b.key等于a.key那么返回a.val, b.val,如果没有b.key等于a.key那么返回a.val,NULL。b表中和a.key不匹配的数据会被丢弃。
FROM a LEFT OUTER JOIN b必须要写在一行来保证a一定是在b的左边,保留a表所有数据。
FROM a RIGHT OUTER JOIN b必须要写在一行,保留b表所有数据。
FROM a FULL OUTER JOIN b必须要写在一行,保留a表和b表所有数据。
SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key)
join发生在where语句前。所以如果想过滤join的输出的话,可以在where语句里过滤,也可以在join语句里过滤
考虑下面的sql语句,会返回a.val,b.val的数据集,然后在where进行过滤(既引用了a表字段也引用了b表字段)。对于没有b.key等于a.key的row来说,返回的数据是a.val,NULL,而且b.ds的值也是NULL。也就是说b.ds='2009-07-07'会过滤掉所有没有b.key等于a.key的a的row数据(那就有可能过滤多了)
SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key)
WHERE a.ds='2009-07-07' AND b.ds='2009-07-07'
那么对于LEFT OUTER JOIN这种情况来说,应该采用下面的语句,join的结果已经预先就过滤掉了。RIGHT and FULL join也是同理。
SELECT a.val, b.val FROM a LEFT OUTER JOIN b
ON (a.key=b.key AND b.ds='2009-07-07' AND a.ds='2009-07-07')
- Joins are NOT commutative! Joins are left-associative regardless of whether they are LEFT or RIGHT joins. 这句话我在上面join的介绍里就已经说明的很清楚了。
例如,a和b先做join,得到的结果再去做LEFT OUTER JOIN c,所以即使a.key和c.key存在但是b.key不存在,这条数据也会在a join b的阶段被干掉。
SELECT a.val1, a.val2, b.val, c.val
FROM a
JOIN b ON (a.key = b.key)
LEFT OUTER JOIN c ON (a.key = c.key)
LEFT SEMI JOIN以一种有效的方式实现了IN/EXISTS子查询功能。LEFT SEMI JOIN的限制是右边的表只能在join condition (ON-clause)里引用,不能在WHERE或者SELECT等语句里使用
例如,
SELECT a.key, a.value
FROM a
WHERE a.key in
(SELECT b.key
FROM B);
就可以重写成
SELECT a.key, a.val
FROM a LEFT SEMI JOIN b ON (a.key = b.key)
- 如果join的表里面有一个小表,那么就可以将该join转换成一个只有map的job,不需要reducer。
例如,b表足够小,/*+ MAPJOIN(b) */就会将b表的所有数据加载到内存,对于a表的每个mapper,b表数据可以直接读取。限制是a FULL OUTER JOIN b不能执行,因为map join操作仅仅只能stream一张表,FULL OUTER JOIN就需要stream两张表了。不建议使用/*+ MAPJOIN(b) */,而应该使用参数hive.auto.convert.join=true,开启后hive会在运行时自动的将join转换成map join(如果可以的话)
SELECT /*+ MAPJOIN(b) */ a.key, a.value
FROM a JOIN b ON a.key = b.key
- 如果join的表是在on语句的列上做了bucket,且两个表的bucket的数目是倍数关系,那么两表的bucket之间可以相互join
例如,a表和b表都有4个bucket,下面的join会转换成一个只有map的job。对于A的每个mapper,不用获取B的所有数据,处理A的bucket-1的mapper仅仅只需要获取B的bucket-1。但是这并不是默认行为,需要通过设置set hive.optimize.bucketmapjoin = true来开启
SELECT /*+ MAPJOIN(b) */ a.key, a.value
FROM a JOIN b ON a.key = b.key
- 如果join的表是在on语句的列上做了bucket和sort,而且两表有同样的bucket数,那么就可以优化成
sort-merge join。在mapper里,对应的bucket会相互join。
例如,a表和b表都有4个bucket,下面的join会转换成一个只有map的job。但是需要开启参数来进行优化
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
SELECT /*+ MAPJOIN(b) */ a.key, a.value
FROM A a JOIN B b ON a.key = b.key
Map Join
原理介绍
Hive里的Map Join可以加速查询,这个feature也叫做Map Side Join。上面的官方例子里也简要提到了Map Join的用法,这里是从运行原理、参数、限制等方面来更加详细的介绍该feature。
join有一个开销非常大的操作就是shuffle,这就降低了hive的查询速度。我们可以用Map Side Join来加速查询,因为在join的表里有一个小表是可以完整的加载到内存里的。所以该join可以转换成一个只有map没有reducer的job,消去了shuffle过程。

在MR task前,第一步就是创建一个MapReduce local task。这个本地的MR task会从HDFS上读取小表数据,然后加载到内存的hash table里,然后变成一个hash table文件。接着在MR task启动前将这个hash table文件通过Hadoop Distributed Cache发送到每个mapper的本地磁盘上。这样,所有的mapper就能加载这个hash table文件到mapper内存里然后在map阶段做join。
参数
hive.auto.convert.join
<property>
<name>hive.auto.convert.join</name>
<value>true</value>
<description>Whether Hive enables the optimization about converting common join into mapjoin based on the input file size</description>
</property>
该参数默认值是true,当join的表里找到一个大小小于25 MB(hive.mapjoin.smalltable.filesize)的表,那么就将该join转换为map join。
hive.auto.convert.join.noconditionaltask
<property>
<name>hive.auto.convert.join.noconditionaltask</name>
<value>true</value>
<description>
Whether Hive enables the optimization about converting common join into mapjoin based on the input file size.
If this parameter is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than the
specified size, the join is directly converted to a mapjoin (there is no conditional task).
</description>
</property>
<property>
<name>hive.auto.convert.join.noconditionaltask.size</name>
<value>10000000</value>
<description>
If hive.auto.convert.join.noconditionaltask is off, this parameter does not take affect.
However, if it is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than this size,
the join is directly converted to a mapjoin(there is no conditional task). The default is 10MB
</description>
</property>
假定有3表或者更多的表一起join的场景。如果所有的表都是小表且开启hive.auto.convert.join,Hive会生成3个或多个map-side join。然而,如果第n个表的大小小于10 MB(hive.auto.convert.join.noconditionaltask.size),我们可以将这3个或多个map-side join变成一个map-side join。
hive.auto.convert.join.use.nonstaged
可以将其设置为true来避免这些情况的pres-taging,这些情况包括要map join的表不用过滤或者projection。当前,该参数不适用于vectorization和tez引擎
<property>
<name>hive.auto.convert.join.use.nonstaged</name>
<value>false</value>
<description>
For conditional joins, if input stream from a small alias can be directly applied to join operator without
filtering or projection, the alias need not to be pre-staged in distributed cache via mapred local task.
Currently, this is not working with vectorization or tez execution engine.
</description>
</property>
Hive Map Side Join的限制
- 主要的限制是我们是无法将
Full outer join转化为map-side join的。这个在上面官方例子里说过。 - 对于
left-outer join变成map-side join,右边的表大小需要小于25 MB。 - Union Followed by a MapJoin
- Lateral View Followed by a MapJoin
- Reduce Sink (Group By/Join/Sort By/Cluster By/Distribute By) Followed by MapJoin
- MapJoin Followed by Union
- MapJoin Followed by Join
- MapJoin Followed by MapJoin
测试
先创建一张表company_new
create table company_new
row format delimited fields terminated by '\t'
stored as textfile
AS
select count(*) ct,company from student_part group by company order by ct desc;
将student_dwd_ext表和company_new表进行join,查看执行计划
explain select a.*, b.ct from student_dwd_ext a, company_new b where a.company=b.company and a.company="凌云科技有限公司";
如下图所示,只有Map阶段,没有reduce,说明已经变成了map-side join

在关闭掉hive.auto.convert.join后再次查看其查询计划,如下图所示,就是正常的join,有Reduce
set hive.auto.convert.join=false;
explain select a.*, b.ct from student_dwd_ext a, company_new b where a.company=b.company and a.company="凌云科技有限公司";

查询时间上也有差距,这里我就不展示图片了。
Bucket Map Join
当要join的表很大,且join on的列刚好是bucket的列,还需要一个表的bucket的数目是另一个表的bucket数目的倍数,那么我们就可以使用Bucket Map Join。

假如一个表有2个bucket,那么另一个表的bucket的数目必须是2的倍数。而且表的每个bucket是可以放的进内存例如a表的bucket-a1大小要足够小,这样才能执行map side join,否则就只能执行普通的join。这样,在mapper端就只需要获取相对应的bucket就行了,而不用获取整个表。这样就能大大提高性能。还有一点需要保证的是,数据不能在bucket map join里做排序。
默认情况下,bucket map join是不会开启的,需要设置下面的参数来开启优化。
set hive.optimize.bucketmapjoin = true;
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
bucket map join的使用场景总结为以下五点
- 所有的表是非常大的
- 表join on的列恰好是bucket的列
- 一个表的bucket的数目是另一个表的bucket数目的倍数
- 表的每个bucket必须要足够小(即对应的bucket数目应该要很大)
- 数据不能排序
bucket map join的缺点也是非常明显,也就是上面的第2点,只能用在特定的sql join语句里。
Sort Merge Bucket Map Join
使用要求如下
- 所有的表是非常大的
- 表join on的列恰好是bucket的列同时也是
sort的列 - 所有join的表的bucket的数目必须是相同的
需要设置以下参数来开启
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
Sort Merge Bucket Map Join的缺点也是非常明显,限制很高。
join优化的总结
上面的这些优化参数并不一定会带来更快的查询速度。假如选择Sort Merge Bucket Map Join,在执行join前会首先对join的表进行排序,这就是增加的开销。map join也会增加内存的开销。所以这都是一个trade-off的过程。
有可能简单的join就有很好的性能,而上面的优化参数没有效果。所以这时就可以考虑调整MapReduce或者Hive配置如内存使用、并行度等来优化常规的join。
参考网址
faker简单使用
faker官网
python-multithreading
hive-static-vs-dynamic-partition
data-flair-hive-parititions
LanguageManual+Sampling
tablesamplebucket-x-out-of-y
bucketing-in-hive
LanguageManual+Joins
map-join-in-hive
LanguageManual+JoinOptimization
hive-efficient-join-of-two-tables
