1.hive创建表格语法
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [column_constraint_specification] [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
data_type
: primitive_type
| array_type
| map_type
| struct_type
| union_type -- (Note: Available in Hive 0.7.0 and later)
primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later)
| STRING
| BINARY -- (Note: Available in Hive 0.8.0 and later)
| TIMESTAMP -- (Note: Available in Hive 0.8.0 and later)
| DECIMAL -- (Note: Available in Hive 0.11.0 and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later)
| DATE -- (Note: Available in Hive 0.12.0 and later)
| VARCHAR -- (Note: Available in Hive 0.12.0 and later)
| CHAR -- (Note: Available in Hive 0.13.0 and later)
array_type
: ARRAY < data_type >
map_type
: MAP < primitive_type, data_type >
struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...>
union_type
: UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later)
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| JSONFILE -- (Note: Available in Hive 4.0.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
column_constraint_specification:
: [ PRIMARY KEY|UNIQUE|NOT NULL|DEFAULT [default_value]|CHECK [check_expression] ENABLE|DISABLE NOVALIDATE RELY/NORELY ]
default_value:
: [ LITERAL|CURRENT_USER()|CURRENT_DATE()|CURRENT_TIMESTAMP()|NULL ]
constraint_specification:
: [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, CONSTRAINT constraint_name FOREIGN KEY (col_name, ...) REFERENCES table_name(col_name, ...) DISABLE NOVALIDATE
[, CONSTRAINT constraint_name UNIQUE (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, CONSTRAINT constraint_name CHECK [check_expression] ENABLE|DISABLE NOVALIDATE RELY/NORELY ]
2.hive创建内部表
内部表:
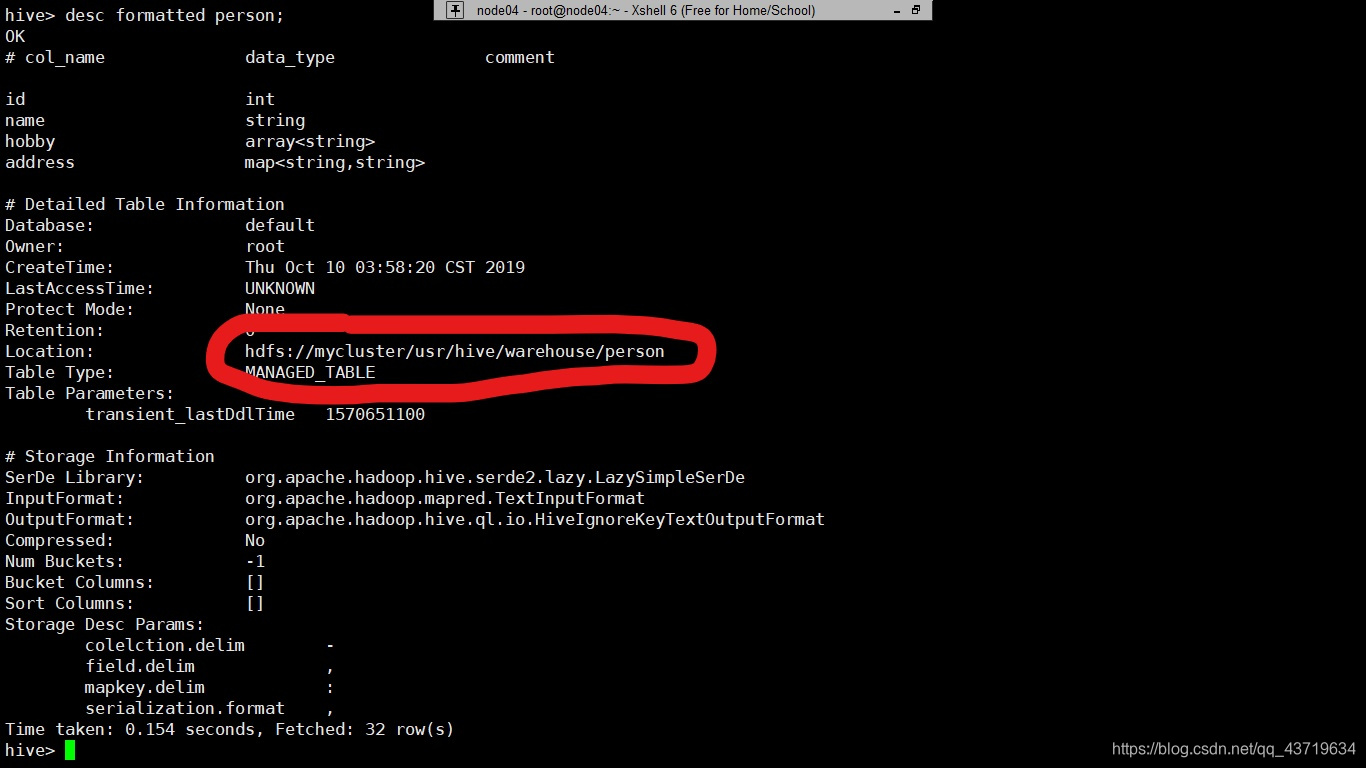
2.1默认行格式(ROW FORMAT)创建内部表
数据格式:

基本语法:
create table person1
(
id int,
name string,
hobby array<string>,
address map<string,string>
);
或
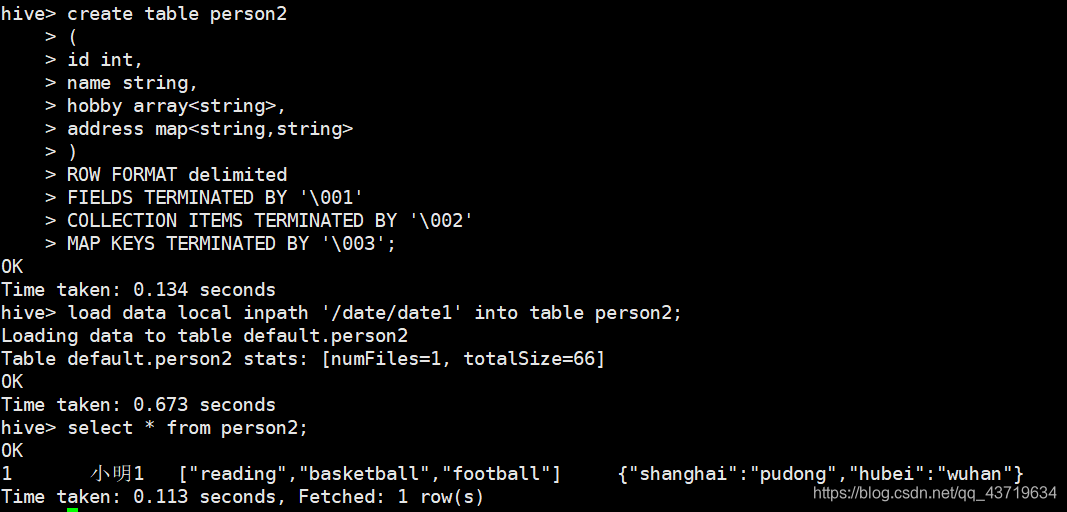
(不常用)
create table person2
(
id int,
name string,
hobby array<string>,
address map<string,string>
)
ROW FORMAT delimited
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003';
//用文件的方式插入数据
load data local inpath '/date/date' into table person2;
注意:默认的行格式中,以^ A(linux文本书写中为Ctrl+V,Ctrl+A)----------^ H(Ctrl+V,Ctrl+H),不能超过^ H。其中^ A 也与’\001’等效,^ B与’\002’等效,以此类推。
什么时候需要用到^ A等行格式?
当表的属性比较复杂时,如array<map<string,array>>时,自定义分隔符将很难进行界定各属性,必须用此界定符。
为什么用文件方式插入数据,而不是insert into的方式?
因为insert into的方式插入数据需要提交job作业给mr,mr进行map,shuffle,reduce。其中shuffle阶段,频繁的与I/O(网络I/O,磁盘I/O)交互,造成耗费大量时间。
2.2自定义行格式(ROW FORMAT)创建内部表
数据格式:
1,小明1,reading-basketball-football,shanghai:pudong-hubei:wuhan
2,小明2,reading-basketball-football,shanghai:pudong-hubei:wuhan
3,小明3,reading-basketball-football,shanghai:pudong-hubei:wuhan
4,小明4,reading-basketball-football,shanghai:pudong-hubei:wuhan
5,小明5,reading-basketball-football,shanghai:pudong-hubei:wuhan
6,小明6,reading-basketball-football,shanghai:pudong-hubei:wuhan
7,小明7,reading-basketball-football,shanghai:pudong-hubei:wuhan
8,小明8,reading-basketball-football,shanghai:pudong-hubei:wuhan
9,小明9,reading-basketball-football,shanghai:pudong-hubei:wuhan
语法:
create table person
(
id int,
name string,
hobby array<string>,
address map<string,string>
)
ROW FORMAT delimited
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':';
//以文件方式插入数据
load data local inpath '/date/date' into table person;


3.创建外部表
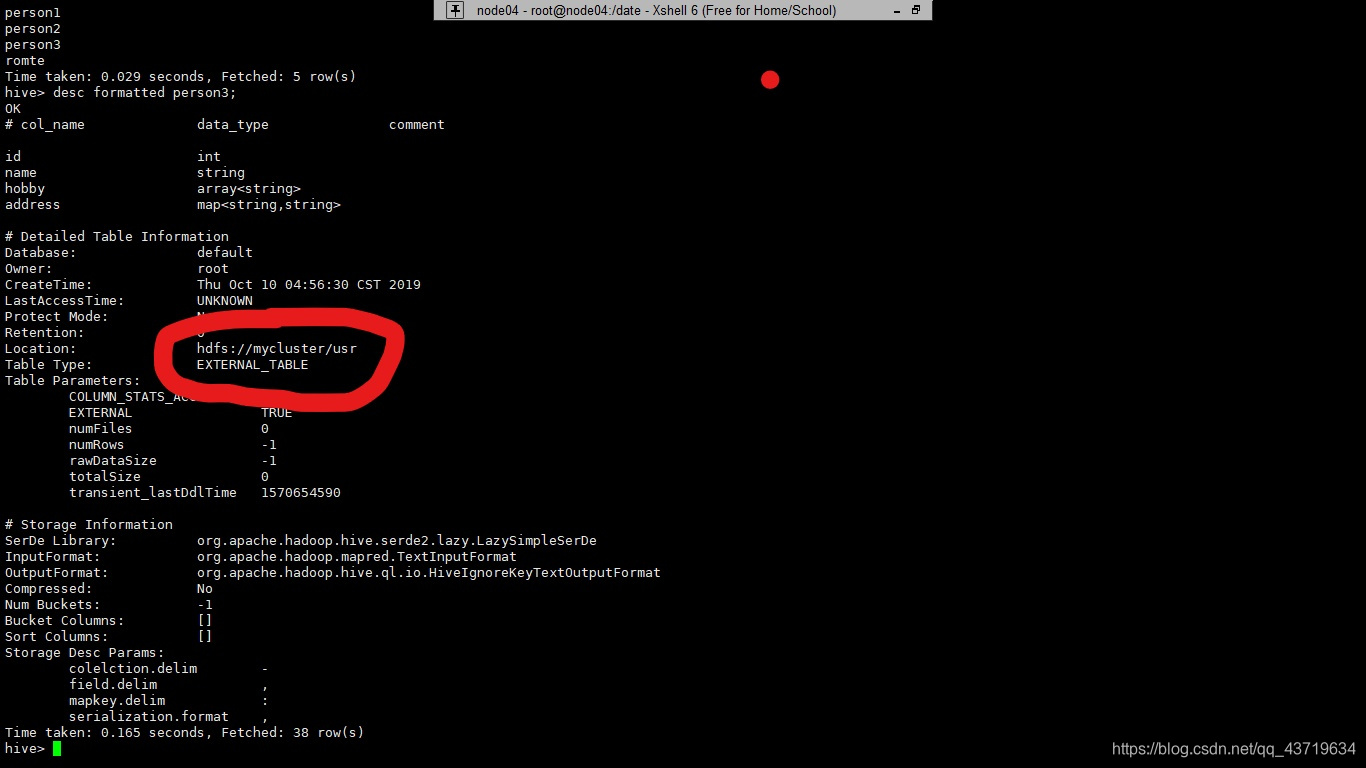
创建外部表的语法与内部表的语法大致相同,只有个别差异。
数据格式:
1,小明1,reading-basketball-football,shanghai:pudong-hubei:wuhan
2,小明2,reading-basketball-football,shanghai:pudong-hubei:wuhan
3,小明3,reading-basketball-football,shanghai:pudong-hubei:wuhan
4,小明4,reading-basketball-football,shanghai:pudong-hubei:wuhan
语法:
create EXTERNAL table person3
(
id int,
name string,
hobby array<string>,
address map<string,string>
)
ROW FORMAT delimited
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
//设置数据存储在hdfs的路径
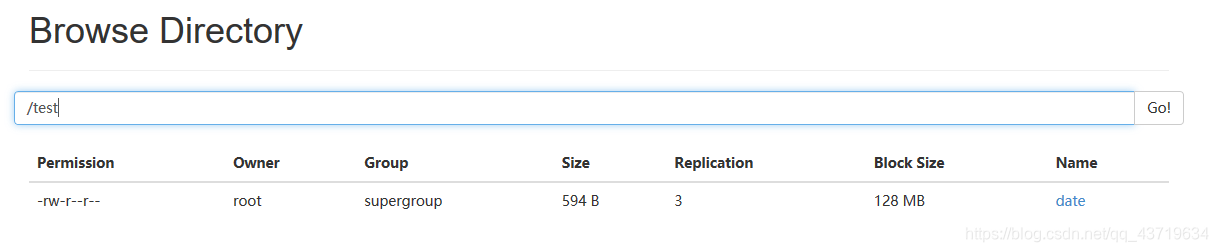
LOCATION '/test';
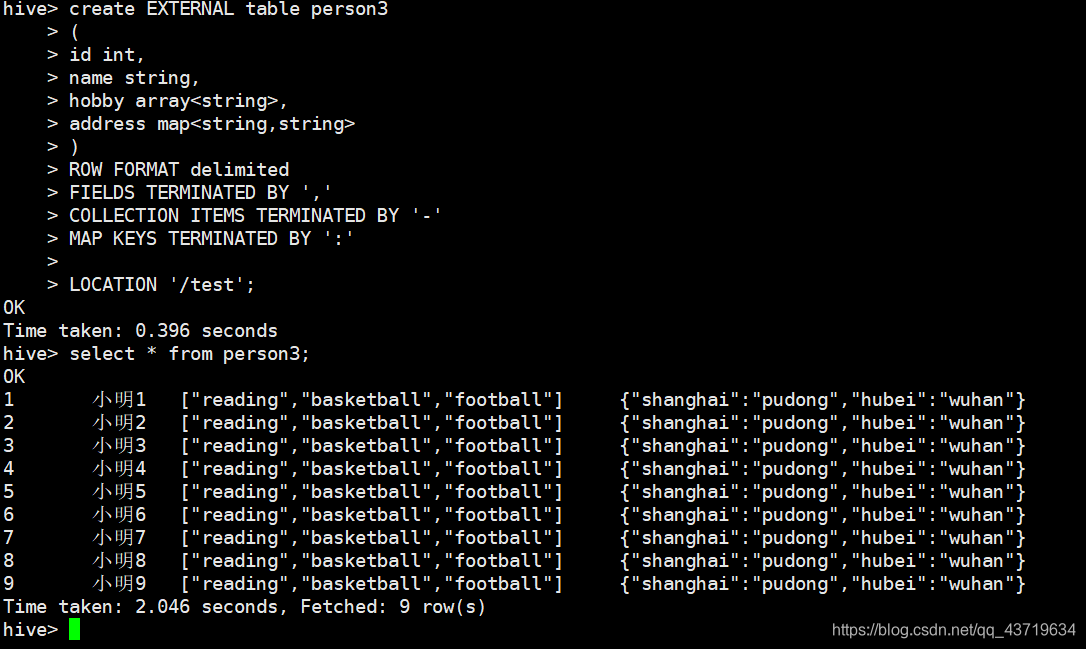
注意开头和末尾的差异。并且外部表不需要导入数据,会根据你设置的hdfs的路径下的文件为数据,创建表
4.内部表和外部表的区别
1、创建表的时候,内部表直接存储再默认的hdfs路径,外部表需要自己指定路径
2、删除表的时候,内部表会将数据和元数据全部删除,外部表只删除元数据,数据不删除
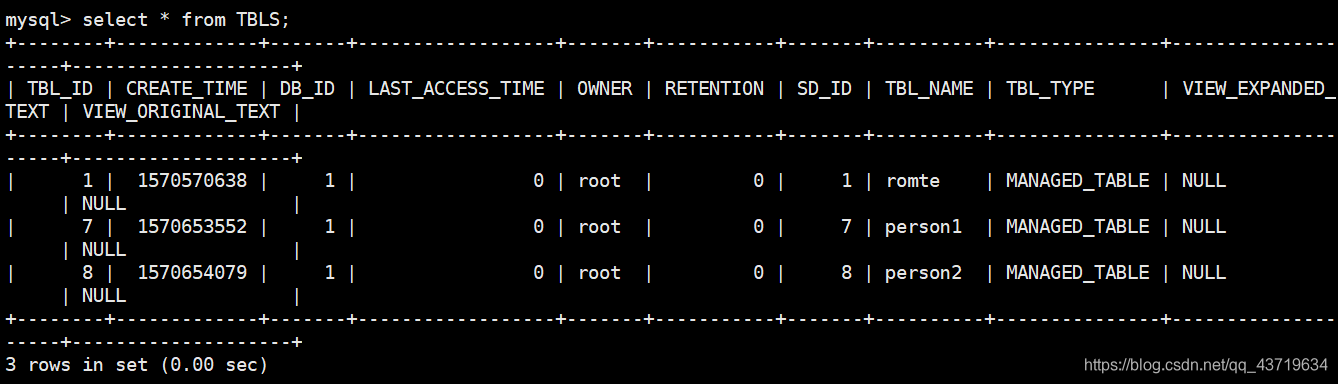
删除内部表person和外部表person3
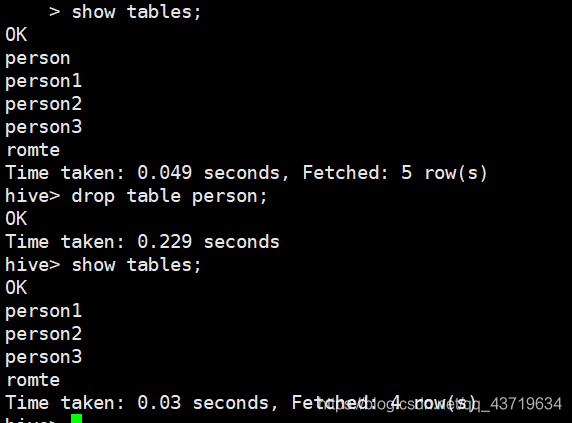 mysql中存档元数据都被删除
mysql中存档元数据都被删除
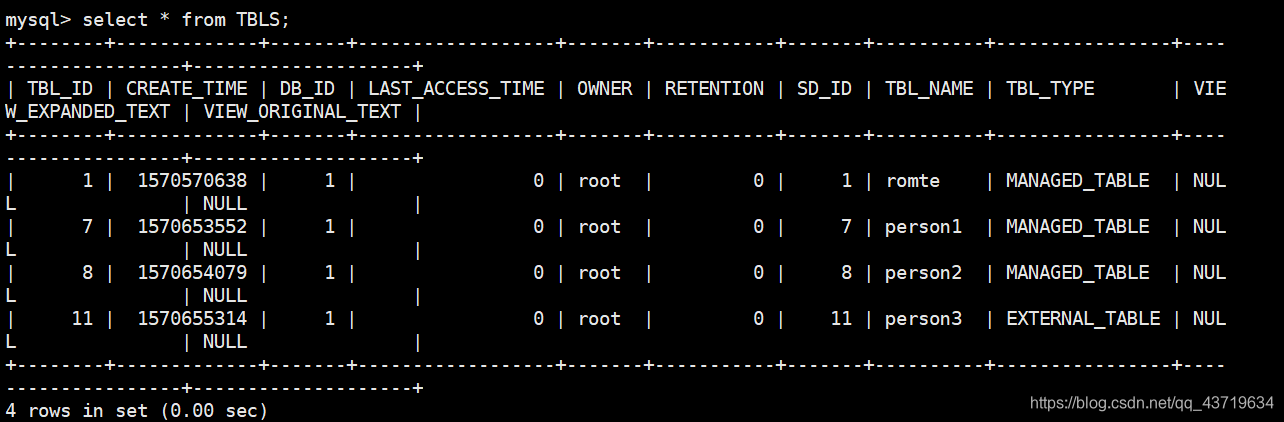
 外部表的数据依然存在
外部表的数据依然存在
 内部表的数据被删除
内部表的数据被删除
注 意:hive:读时检查(实现解耦(hdfs和hive职责分离,hdfs负责存储,hive负责解析显示。任何文件都可以存入hdfs,但是hive只能解析特定格式的文件,不符合格式,将显示为NULL),提高数据记载的效率)
关系型数据库:写时检查
5.创建struct结构体类型(扩展)
hive> create table t (id structid1:int,id2:int,id3:int,name array,xx map<int,string>)
row format delimited
fields terminated by ‘\t’
lines terminated by ‘\n’
collection items terminated by ‘,’
map keys terminated by ‘:’;
FAILED: ParseException line 5:0 missing EOF at ‘collection’ near ‘’\n’’
for example:
编辑本地文件:f.txt 内容为:1,2 1,2,3,4,5 1:value_1,2:value_2
导入本地文件:load data local inpath ‘/f.txt’ into table t;
查询表数据:select * from t;
{“id1”:1,“id2”:2} [“1”,“2”,“3”,“4”,“5”] {1:“value_1”,2:“value_2”}
