生成Bucket表
创建Bucket表
- 方式一
spark.sql("DROP TABLE IF EXISTS user1_bucket")
spark.sql("DROP TABLE IF EXISTS user2_bucket")
val r = new scala.util.Random()
val df = spark.range(1, 100).map(i => (i, s"wankun-${r.nextInt(100)}")).toDF("id", "name")
df.write.
bucketBy(10, "name").
sortBy("name").
mode("overwrite").
saveAsTable("user1_bucket")
scala> spark.sql("show create table user1_bucket").show(false)
+------------------------------------------------------------------------------------------------------------------------------------+
|createtab_stmt |
+------------------------------------------------------------------------------------------------------------------------------------+
|CREATE TABLE `default`.`users` (
`id` BIGINT,
`name` STRING)
USING parquet
CLUSTERED BY (name)
SORTED BY (name)
INTO 10 BUCKETS
|
+------------------------------------------------------------------------------------------------------------------------------------+
- 方式二
CREATE TABLE user2_bucket (
`id` BIGINT,
`name` STRING)
USING parquet
CLUSTERED BY (name)
INTO 10 BUCKETS;
INSERT OVERWRITE TABLE user2_bucket
SELECT id, concat("wankun-",cast(rand()*100 as int)) as name
FROM range(1, 100);
生成的结果文件
[1] $ hdfs dfs -ls /user/hive/warehouse/user1_bucket
21/05/12 17:11:19 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 21 items
-rw-r--r-- 1 wakun supergroup 0 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/_SUCCESS
-rw-r--r-- 1 wakun supergroup 812 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00000-b657899a-401b-406b-b45d-ac4df1d72e14_00000.c000.snappy.parquet
-rw-r--r-- 1 wakun supergroup 815 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00000-b657899a-401b-406b-b45d-ac4df1d72e14_00001.c000.snappy.parquet
-rw-r--r-- 1 wakun supergroup 833 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00000-b657899a-401b-406b-b45d-ac4df1d72e14_00002.c000.snappy.parquet
-rw-r--r-- 1 wakun supergroup 797 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00000-b657899a-401b-406b-b45d-ac4df1d72e14_00003.c000.snappy.parquet
...
-rw-r--r-- 1 wakun supergroup 817 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00000-b657899a-401b-406b-b45d-ac4df1d72e14_00009.c000.snappy.parquet
-rw-r--r-- 1 wakun supergroup 812 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00001-b657899a-401b-406b-b45d-ac4df1d72e14_00000.c000.snappy.parquet
-rw-r--r-- 1 wakun supergroup 815 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00001-b657899a-401b-406b-b45d-ac4df1d72e14_00001.c000.snappy.parquet
-rw-r--r-- 1 wakun supergroup 833 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00001-b657899a-401b-406b-b45d-ac4df1d72e14_00002.c000.snappy.parquet
-rw-r--r-- 1 wakun supergroup 831 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00001-b657899a-401b-406b-b45d-ac4df1d72e14_00003.c000.snappy.parquet
....
-rw-r--r-- 1 wakun supergroup 788 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00001-b657899a-401b-406b-b45d-ac4df1d72e14_00008.c000.snappy.parquet
-rw-r--r-- 1 wakun supergroup 817 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00001-b657899a-401b-406b-b45d-ac4df1d72e14_00009.c000.snappy.parquet
相同数据的Key一定在同一个Bucket
scala> spark.read.parquet("/user/hive/warehouse/user1_bucket/part-00000-b657899a-401b-406b-b45d-ac4df1d72e14_00000.c000.snappy.parquet").show(false)
+---+---------+
|id |name |
+---+---------+
|21 |wankun-57|
|12 |wankun-73|
|37 |wankun-73|
|10 |wankun-89|
|17 |wankun-89|
|35 |wankun-89|
+---+---------+
scala> spark.read.parquet("/user/hive/warehouse/user1_bucket/part-00001-b657899a-401b-406b-b45d-ac4df1d72e14_00000.c000.snappy.parquet").show(false)
+---+---------+
|id |name |
+---+---------+
|70 |wankun-57|
|61 |wankun-73|
|86 |wankun-73|
|59 |wankun-89|
|66 |wankun-89|
|84 |wankun-89|
+---+---------+
scala> spark.read.parquet("/user/hive/warehouse/user1_bucket/part-00000-b657899a-401b-406b-b45d-ac4df1d72e14_00001.c000.snappy.parquet").show(false)
+---+---------+
|id |name |
+---+---------+
|1 |wankun-0 |
|8 |wankun-12|
|13 |wankun-12|
|16 |wankun-29|
|27 |wankun-85|
|34 |wankun-85|
+---+---------+
测试 bucket table join VS nonbucket table join
set spark.sql.autoBroadcastJoinThreshold=-1;
-- bucket table join
SELECT t1.id, t1.name, t2.id as id2, t2.name as name2
FROM user1_bucket t1
JOIN user2_bucket t2
ON t1.name = t2.name;
-- non bucket table join
SELECT t1.id, t1.name, t2.id as id2, t2.name as name2
FROM user1 t1
JOIN user2 t2
ON t1.name = t2.name;
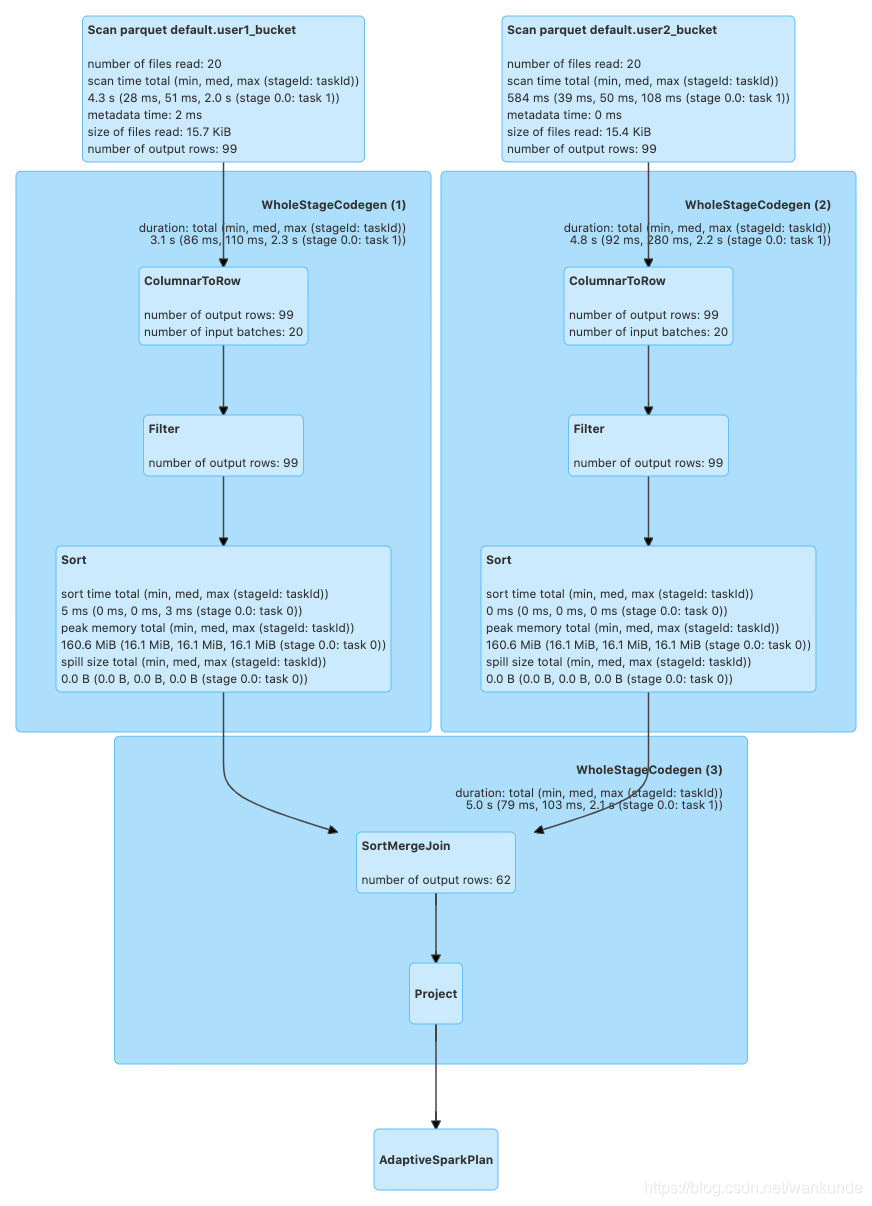
Bucket Join 过程
NonBucket Join 过程
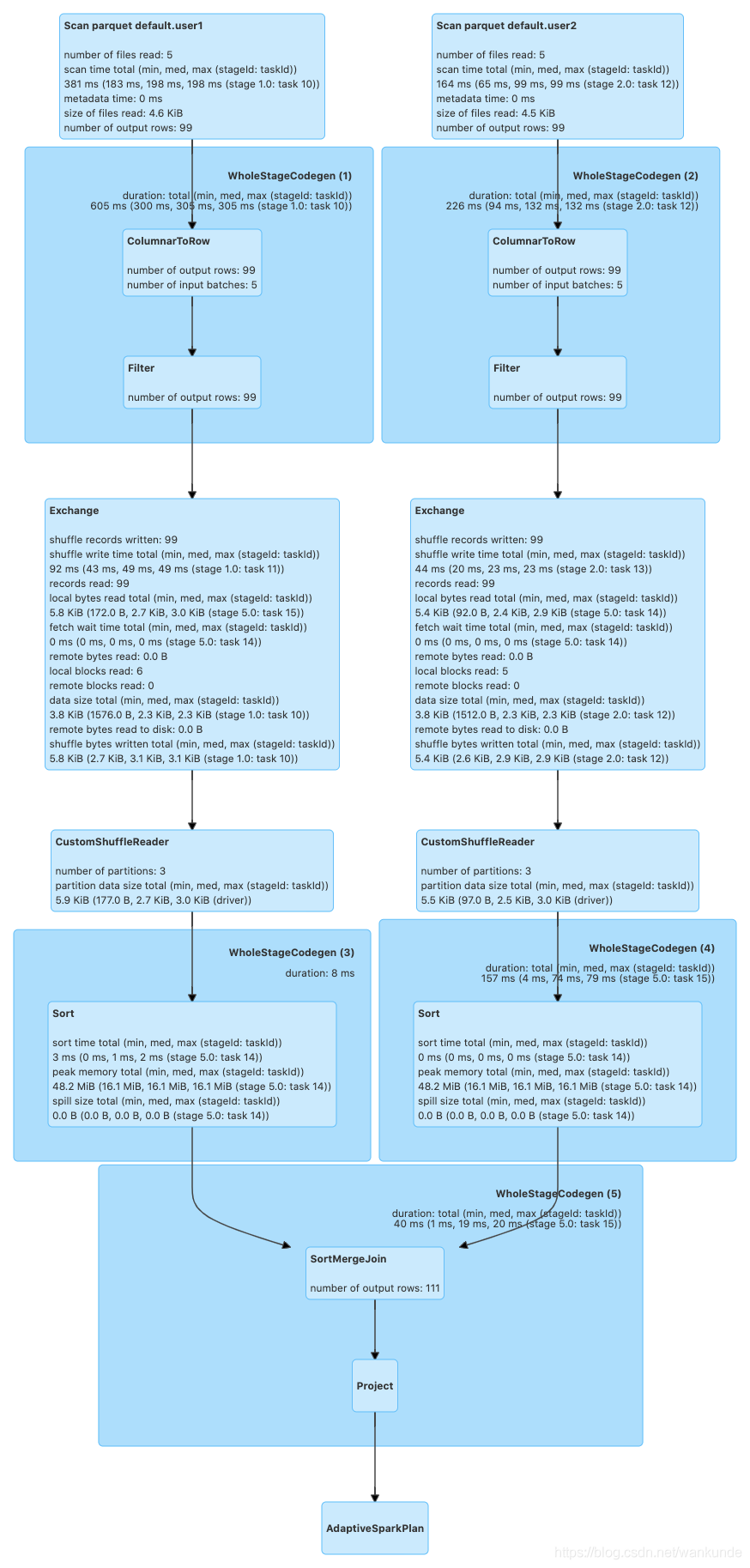
通过对比,Bucket Table的Join少了一次Shuffle的过程。