文章目录
爬取结果下载: https://www.lanzous.com/i9fg9mb
1、爬取具体动态的内容及评论
1.1、分析网页
微博网址: https://m.weibo.cn/
进入微博后,点击《战疫情》主题下,并随便选择一个动态进行分析,我就选择了“央视新闻网”的一条动态https://m.weibo.cn/detail/4471652190688865进行分析。
建议: 选择的目标评论数量不要太多,评论太多的话分析起来比较费时,还有就是要尽量接近顶部,也不能太少,不然会导致分析不够全面。最好选择较新的文章,这样到首页获取它的URL分析时较为容易。
1.1.1、检查网页
把鼠标挪到网页任意地方,单击鼠标右键,选择检查,如图所示:

1.1.2、元素点位
方法一:把鼠标放在你需要查看的文字上,重新单击鼠标右键,进行检查
方法二:点击检查框左上角的箭头,移动鼠标直接点击文字进行定位
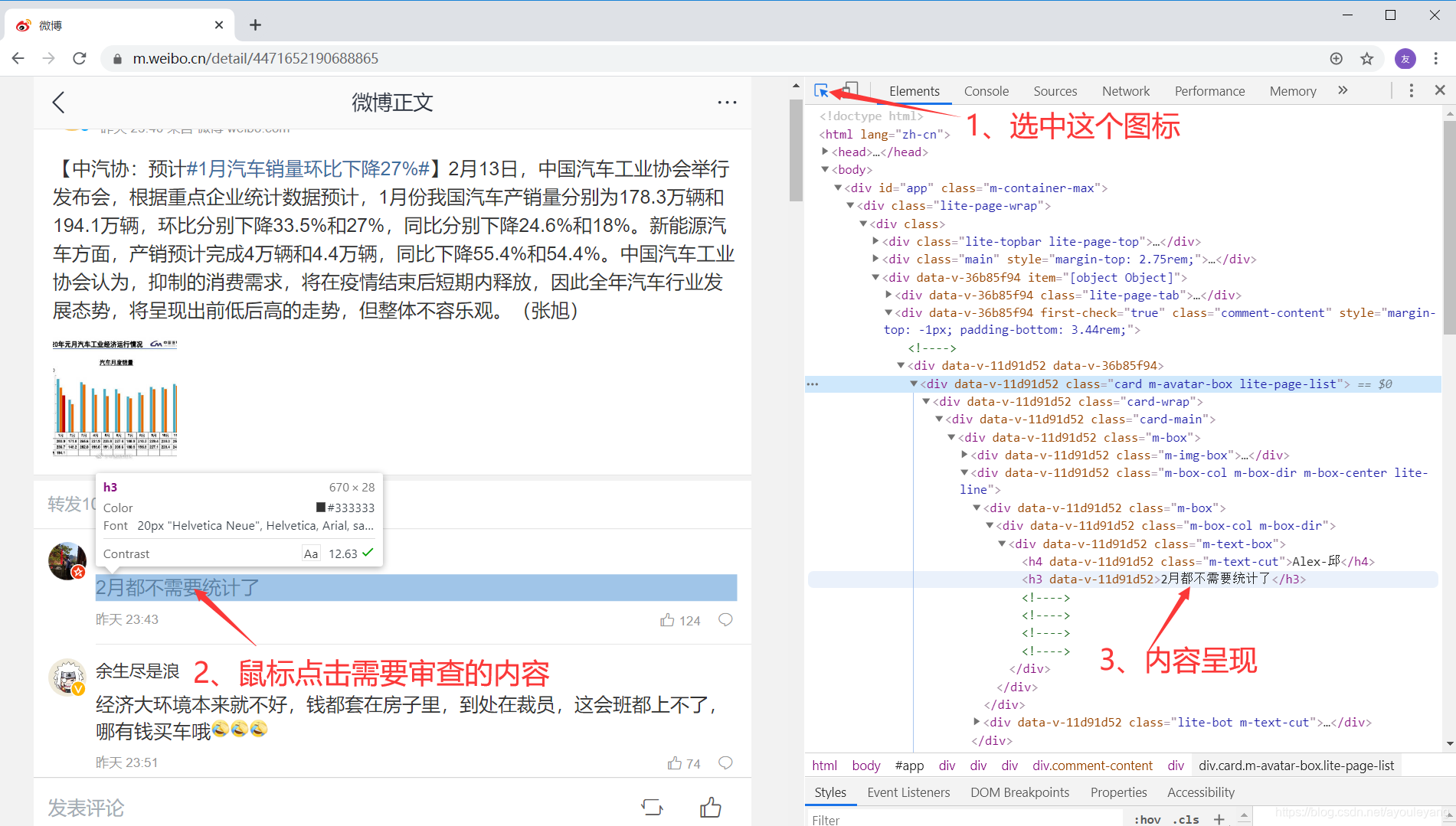
通过不断的进行定位分析,可以发现我们需要的内容没有字体反爬措施,不需要去做额外的工作了。
1.1.3、下拉加载
我们刚打开该话题的时候,它显示的是187条评论,但是在审查的时候可以看到:
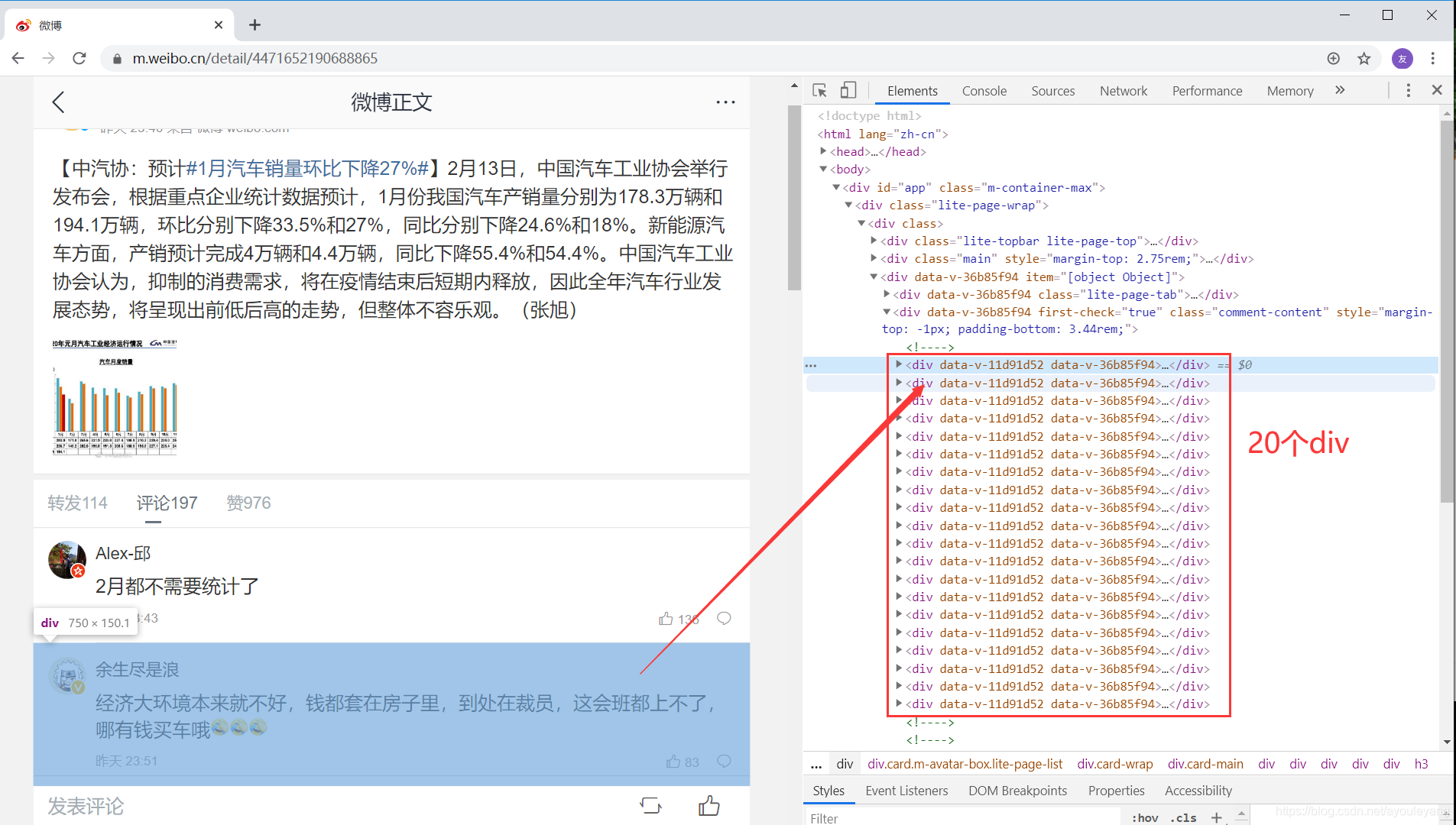
在文章中只有20个 div , 并且每个 div 中装载一条评论,每个页面原始就只能显示20条评论。
当我们把鼠标不断向下滑动的过程中,网页元素中的 div 也不断随评论的增加而增加,当活动到底部时,所有评论都加载出来了。可以初步判断该网页属于ajax加载类型,所以先就不要考虑用requests请求服务器了。
1.2、如何爬取下拉加载的信息
1.2.1、方法一:抓包
浏览器的中的每一条信息的加载都离不开 Network ,这就意味着我们可以通过它来查看网页加载出来的内容。
抓包的步骤:
- 鼠标右击,打开检查功能
- 选择Network
- 刷新网页
- 查看加载的数据
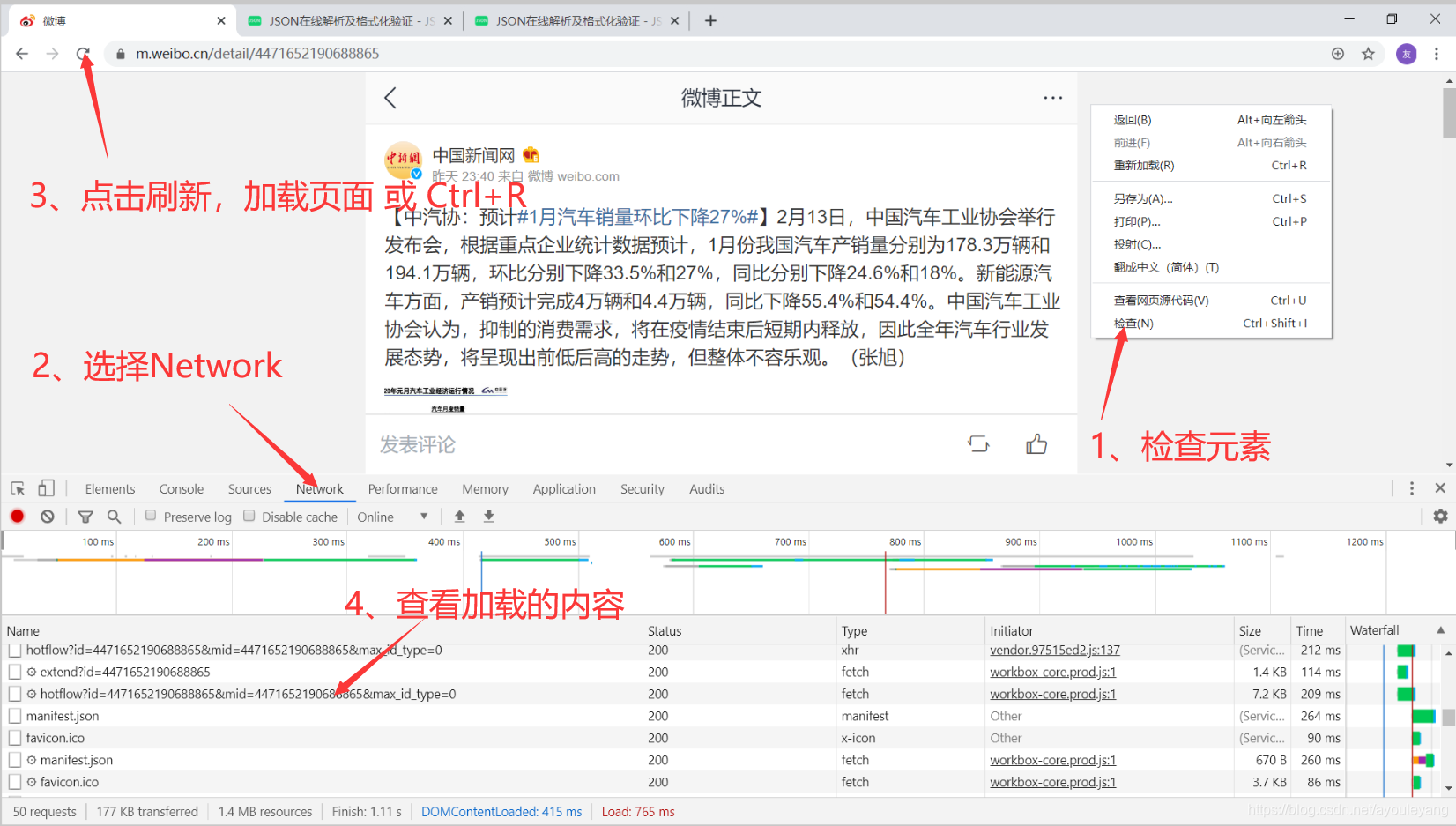
如何更好的查看加载的内容是什么?
我们的目的只是找到自己需要的内容,没有必要全部都查看一遍,只需要知道一些关键的数据进行查看就好了。
- 最重要的是注意 Network 中的Type(加载的文件类型) 和 size(加载的文件大小) 这两个要素,如我们要查看的目标是文字文件,带有图片类型的文件都可以不用查看了,其二就是它的大小,上面的很多文件都没有显示大小,我们几乎可以把它忽略了。对于网页不是很了解的同学,不建议直接使用筛选功能。
- 查看内容:
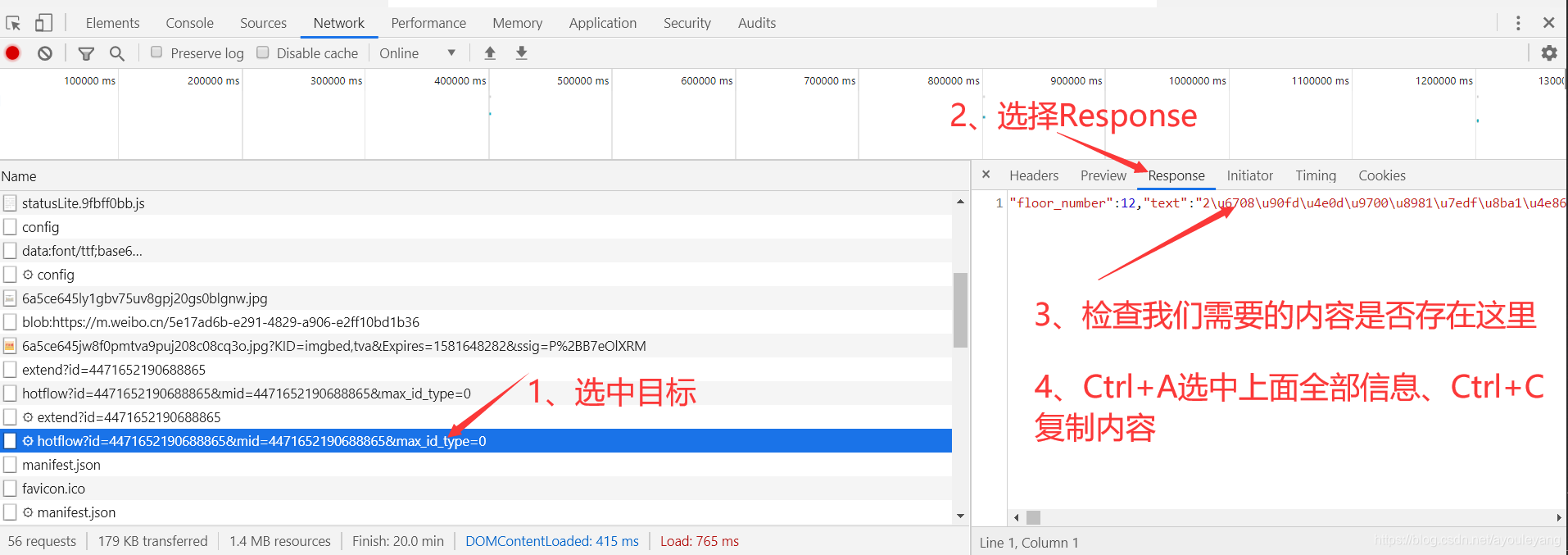
- 我们需要的内容疑似在其中,但是text的内容我们并不认识,不用怕,先把它复制,再找个json解析器在线解析一下。如我用这个解析器: https://www.json.cn/ ,把刚才的内容粘贴进来看看结果
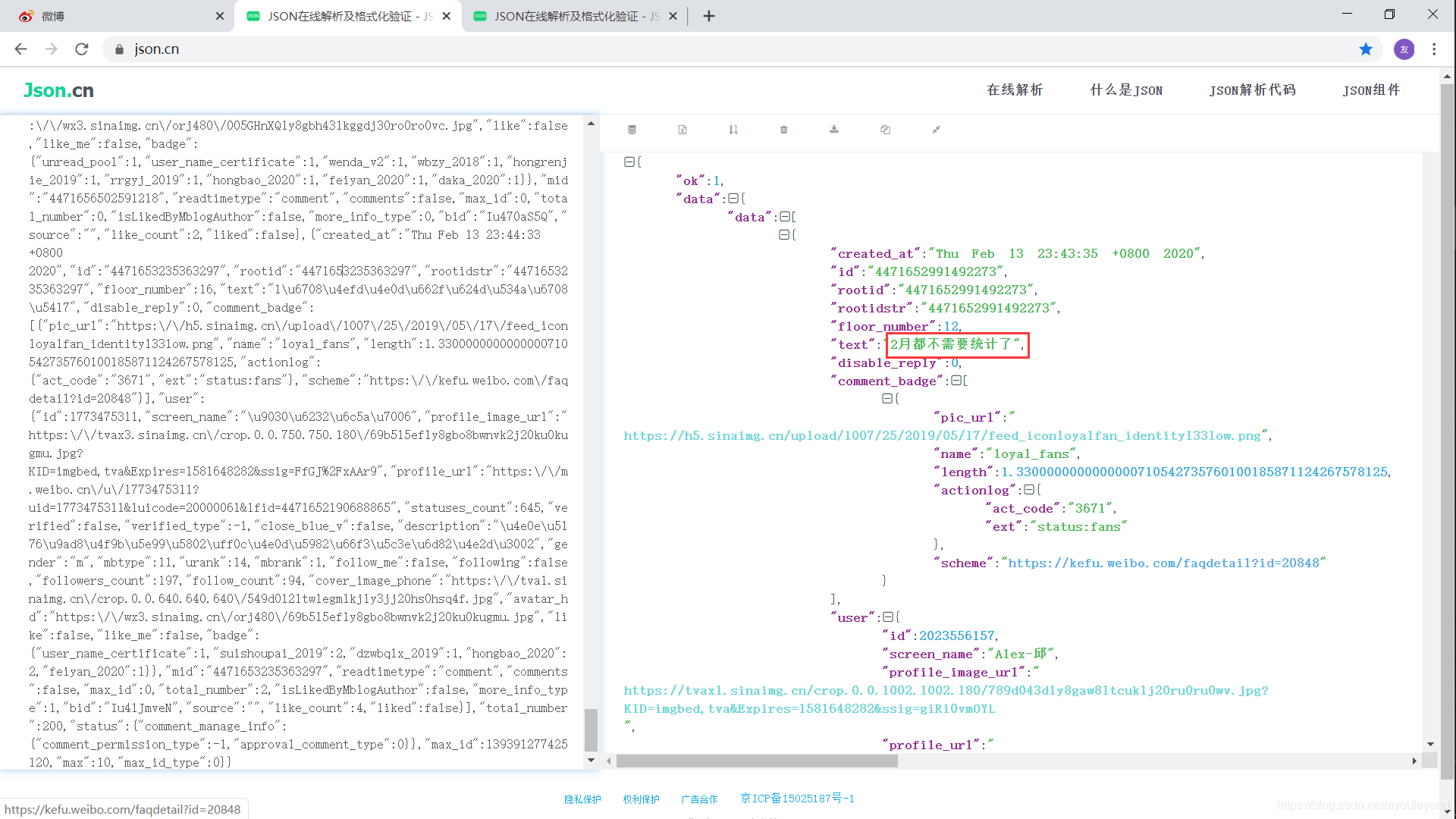
- 看到了吧,这个不就正式我们需要的结果吗,往下面查看,20条评论都在其中了。
- 复制这个路径,python请求看看:
import requests
import json
reponse = requests.get('https://m.weibo.cn/comments/hotflow?id=4471652190688865&mid=4471652190688865&max_id_type=0')
json.loads(reponse.text)
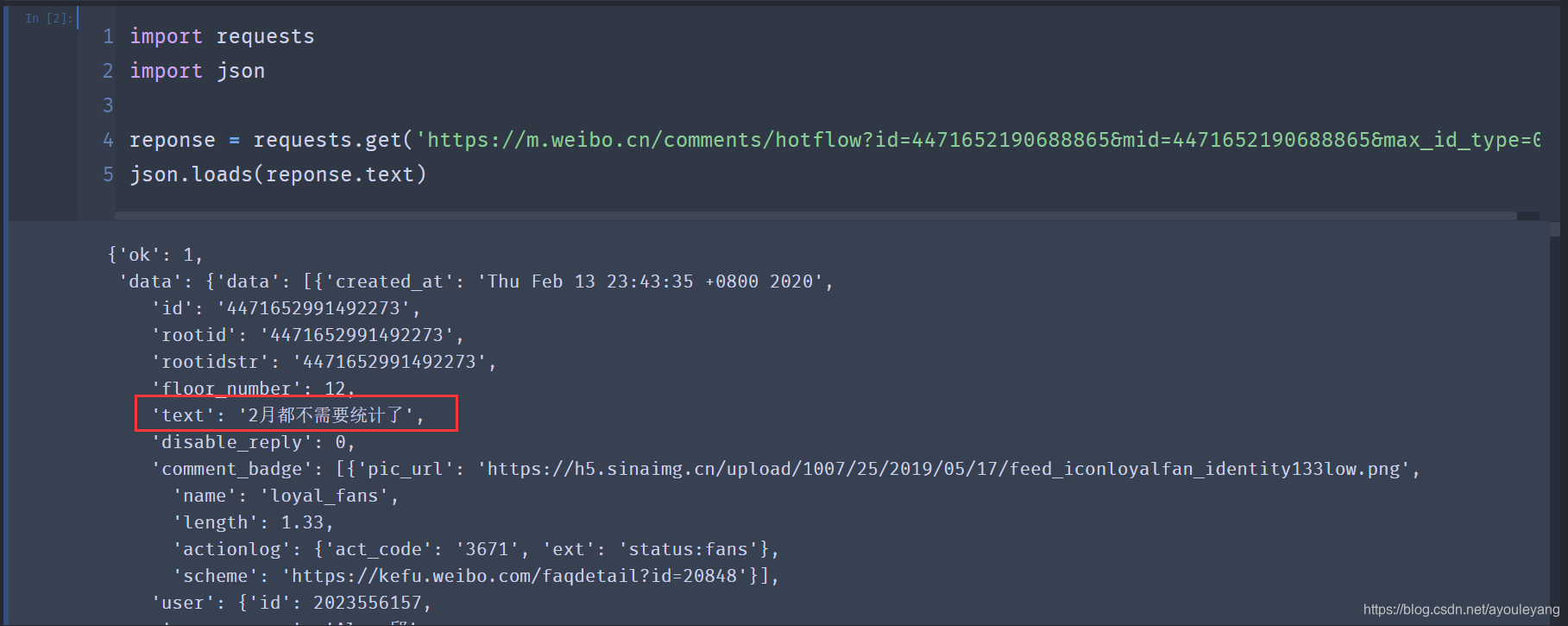
6. 完美拿到我们需要的数据,接下来就是再去抓其他的数据了,分析一下它们的URL

7. 我们可以看到,它们的不同之处都在 max_id 上,只要找出它们的关系,就可以拿到它的数据啦。
8. 如果它的关系不好找的话,那就换其他的方法爬取吧。
9. 但是,通过Ajax拿到数据才是最快最全的,所以必须想办法拿到它的 max_id , 下面第5节有关于它的讲解
1.2.2、方法二: selenium库
这个是开发来做自动化的库,但是用它来做爬虫几乎是无敌的存在,就不多介绍它了,直接开始吧
注意: 如谷歌浏览器,这个库需要配合 chromedriver.exe 来使用,才能控制浏览器。可以到 http://npm.taobao.org/mirrors/chromedriver/ 下载对应自己谷歌浏览器的版本,如果找不到合适自己谷歌的版本的 chromedriver.exe ,可以下载邻近版本的试试或者更新谷歌浏览器,然后进行相关的配置就好了,也可以直接把下载的 chromedriver.exe 放在Python的安装环境下,直接调用,前提是python配置过环境变量。当然也可以使用它的路径来调用。
1.2.2.1、对selenium库的基本用法认识
- 安装
pip install selenium
- 控制浏览器
from selenium import webdriver
driver = webdriver.Chrome() #需要调用对应的chromedriver.exe
- 使用IP代理,通常不需要都行
chrome_option = webdriver.ChromeOptions()
chrome_option.add_argument('--proxy--server=112.84.55.122:9999')#使用代理IP
- 等待网页加载
driver.implicitly_wait(5) #最长等待5秒,记载完成后自动跳过
- 打开网页
driver.get(url) # 需要打开的网页
- 点击网页节点
driver.find_element_by_xpath('这里放网页xpath路径').click()
- 输入内容
driver.find_element_by_xpath('这里放网页输入框的xpath路径').send_keys('输入词')
- 获取文本
driver.find_element_by_xpath('网页中文本xpath路径').text #直接获取某个具体文本
- 网页下拉
js="var q=document.documentElement.scrollTop=10000000" #滚动条,数值为每次下拉的长度,不叠加,以浏览器底部为最大值
driver.execute_script(js)#调用js
- 获取HTML源码
driver.page_source
1.2.2.2、认识xpath
xpath 可以理解成网页上的节点,由 html 的标签构成,可以进行具体定位,也可以模糊定位,使用起来很灵活。
如何获取网页节点的xpath:
- 以百度为例,打开百度
- 鼠标右击——>检查
- 定位元素节点
- 在HTML源码上鼠标右击——> copy ——> Copy Xpath

1.2.2.3、爬取实战思路
- 控制浏览器打开网页
- 获取评论数量:
- 如果评论量大于20,就需要进行下拉加载,小于20不需要下拉,下拉次数 = 评论数 ÷ 20
- 但是这里需要下拉时需要登录才能继续加载,先手动QQ登录一下验证代码的可行性
- 获取源码
- 使用解析库提取信息
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from lxml import etree
import time,random
url = 'https://m.weibo.cn/detail/4471652190688865'
driver = webdriver.Chrome()
driver.implicitly_wait(5)
chrome_option = webdriver.ChromeOptions()
chrome_option.add_argument('--proxy--server=112.84.55.122:9999')#使用代理IP
driver.get(url)#打开网页网页
driver.implicitly_wait(6)#等待加载六秒
#获取评论数
comment_number = driver.find_element_by_xpath('//div[@class="lite-page-tab"]/div[2]/i[2]').text
print ("一共有%s条评论"%comment_number)
if int(comment_number) > 20: #低于20条的评论不用下拉加载
comment_number = int(int(comment_number) / 20) #每次下拉都加载20条评论
js="var q=document.documentElement.scrollTop=10000000" #滚动条
for i in range(comment_number):
driver.execute_script(js)#调用js,将页面拖到底
time.sleep(random.uniform(0, 1.2)) #暂停时间:0~1.2秒
if i == 1:
time.sleep(10) #暂停10秒,手动一键登录
source = driver.page_source
html_etree = etree.HTML(source)
#爬取主题文字
title = html_etree.xpath('//div[@class="weibo-text"]/text()')[0]
# 获取所有评论
div_item = html_etree.xpath('//*[@id="app"]/div[1]/div/div[3]/div[2]/div')
for item in div_item:
try:
comments = item.xpath('./div/div/div/div/div[2]/div[1]/div/div/h3/text()')[0]
except:
pass
print(comments)
输出结果:
一共有282条评论
2月都不需要统计了
经济大环境本来就不好,钱都套在房子里,到处在裁员,这会班都上不了,哪有钱买车哦
汽车行业雪上加霜。
家里车放了半个多月了~放那就是贬值,艹
人都出不去 难不成网购
钱都买房子了!天天还房贷,房地产是罪魁祸首!
汽车行业18,19那两年本来就已经很不景气了,今年加上这个疫情,估计后面几个月也高不到哪里去
疫情发生有的人生存都成问题,还买车
预计下2月份的呗??
疫情过来,我要买车
经济损失太大了
车不车的就不考虑了,2020年目标就一个“好好活着”就行。
大家关注一下
因为武汉政府的不作为,让携带病毒的人逃窜到各个地方,全国都停工在家,毫无生产力,一起吃国家老本儿!倘若当初他们能提早隔离病患,提早警示,哪怕后来迅速封城,我们都不至于此!全国其他省市都能复工,共同撑起大经济,医疗防护也不会短缺,这次疫情,经济上我们恐怕要缓上很长一段时间!
还有摇号、限号,无语了
......
接下来必须解决掉账号登录的问题,如果一直用QQ登录,爬取大量的信息,到时候被封号了就得不偿失了,先去注册一个微博的账号,直接使用它登录。
2、实现微博登录账号
- 为什么要登陆?
先用微博账号登录我控制的浏览器,这样它就自带cookie值了,然后再去访问其他的动态,它就不会再提示让你去登录了。
微博登录入口: https://passport.weibo.cn/signin/login
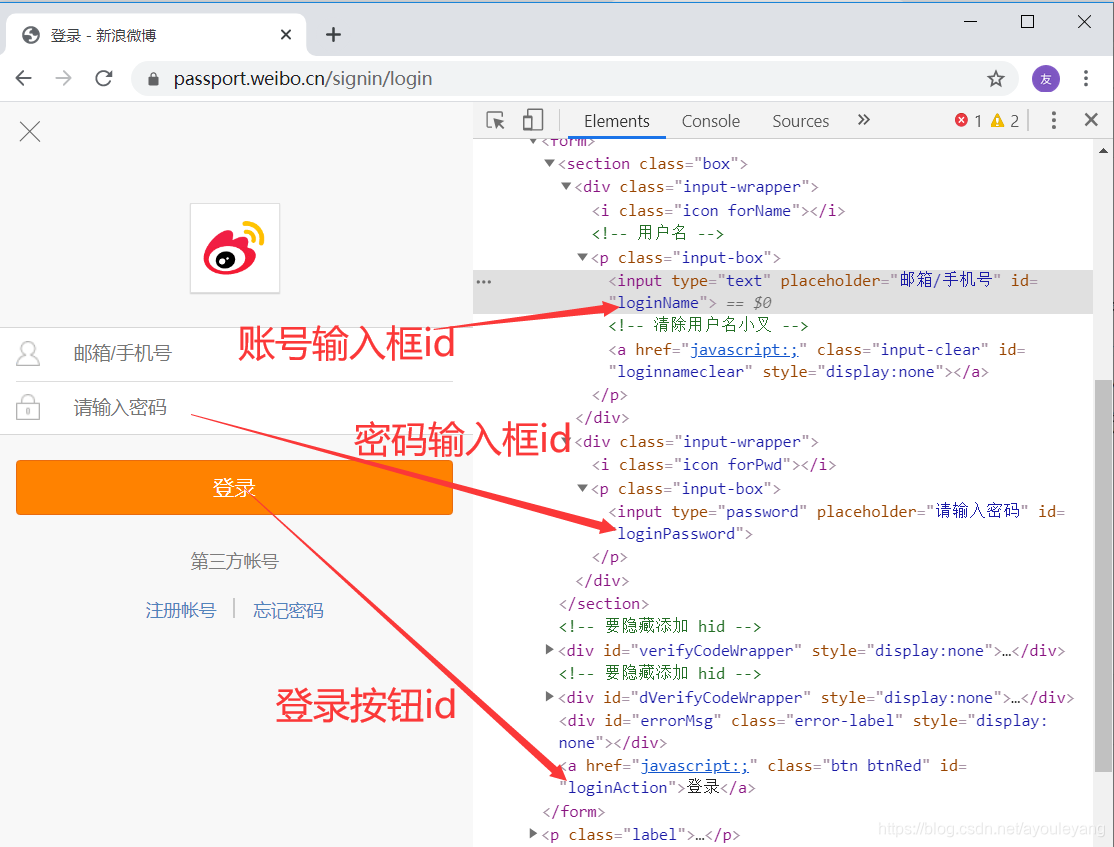
2.1、分析网页
- 账号 id = “loginName”
- 密码 id = “loginPassword”
- 登录 id = “loginAction”
2.2、实现登录思路
- 通过 id 找到账号框和密码框分别输入账号和密码,再点击登录
- 接下来它会跳转到验证码。它是三种随机的验证码,分别为滑动条,滑块,点击文字,做起来比较复杂,这里先不管验证码,让代码暂停一会儿,进行手动验证吧。
2.3、登录模块源码
from selenium import webdriver
import time
url = 'https://passport.weibo.cn/signin/login'
driver = webdriver.Chrome()
driver.implicitly_wait(5)
chrome_option = webdriver.ChromeOptions()
chrome_option.add_argument('--proxy--server=112.84.55.122:9999')#使用代理IP
driver.get(url)#打开网页网页
driver.find_element_by_id('loginName').send_keys('账号') #输入账号
driver.find_element_by_id('loginPassword').send_keys('密码') #输入密码
time.sleep(1)
driver.find_element_by_id('loginAction').click()
#暂停一会儿,手动验证码
time.sleep(15)
3、首页具体动态链接获取
3.1、怎样寻找Ajax加载的数据
对于这样的网页,如何获取它文章的链接也是一个难题,它的这些数据都是通过Ajax动态加载的。从微博的官网,点击到《战疫情》主题,发现它的URL并没有变化,如果通过 selenium 点击转到《战疫情》获取网页HTML,找遍怎么网页都没有链接,这是就不是 selenium 获取HTML能搞定的了,还是通过抓包吧,具体方法见 1.2.1、方法一:抓包 :
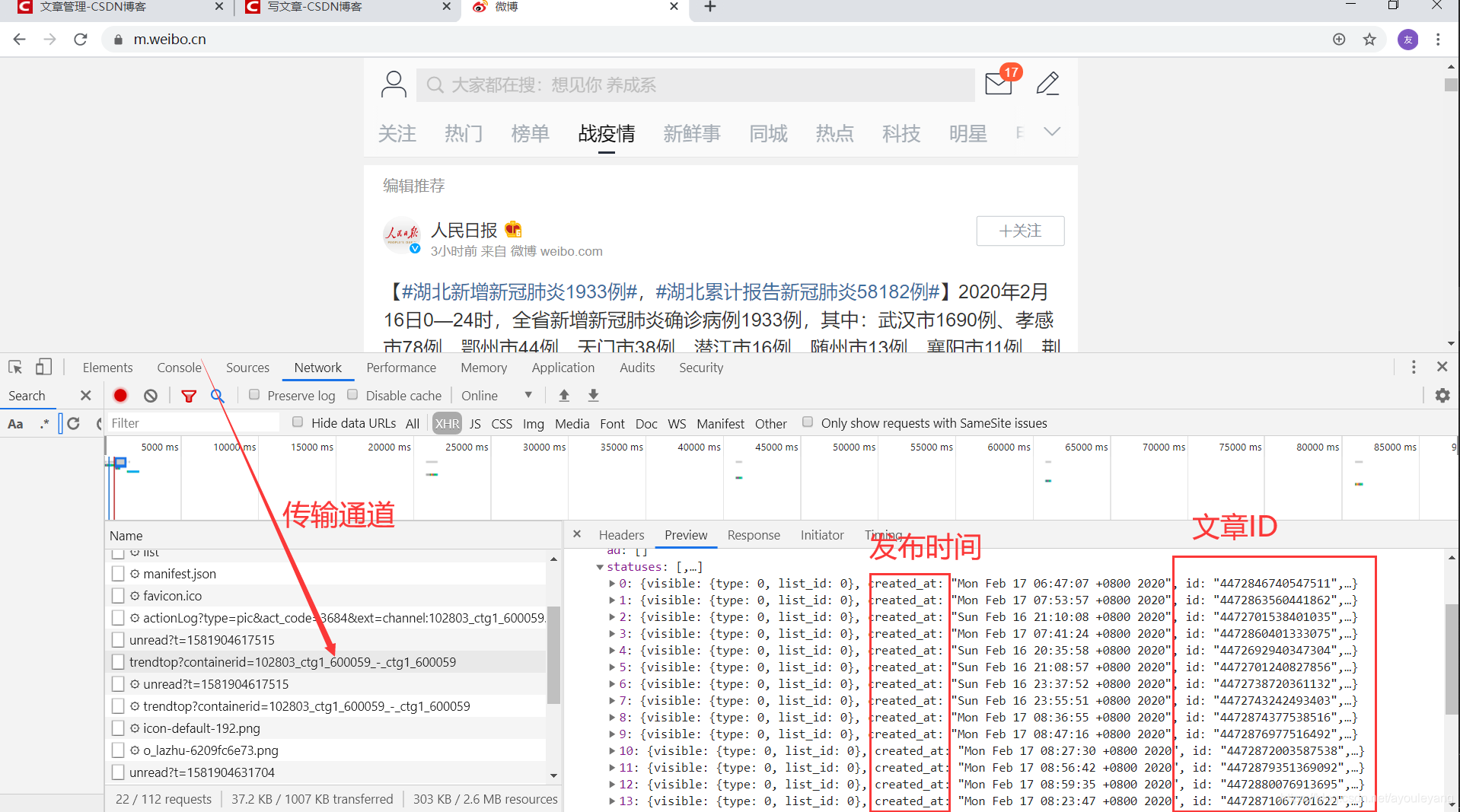
具体浏览几篇文章后发现,它的的部分 URL 都是统一的,文章链接 = 'https://m.weibo.cn/detail/'+ 发布时的id ,可以通过刚找到的 id 在浏览器中拼接试试
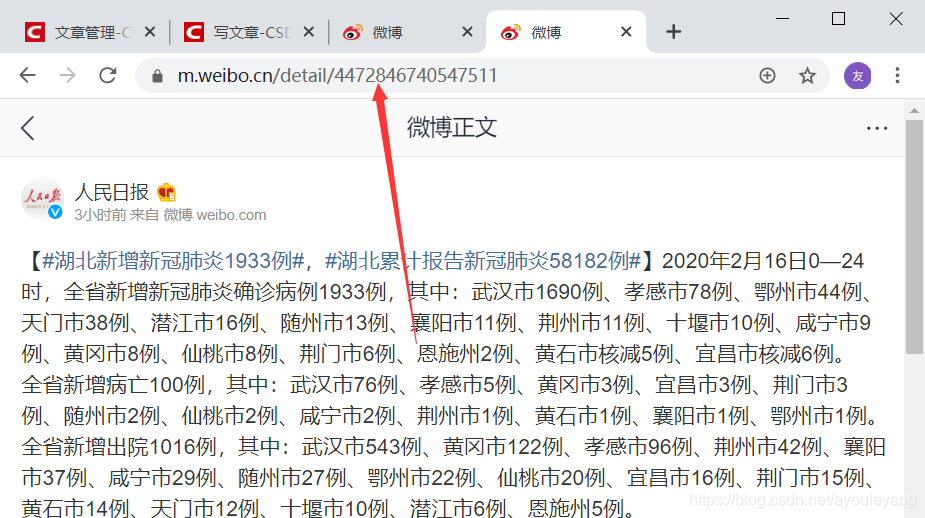
恭喜,没有毛病,成功的找出了它的链接规律了!!!
接下来就是获取它下一个加载数据的通道了,照样是通过抓包的方式获取,不断的下拉网页,加载出其他的Ajax数据传输通道,再进行对比
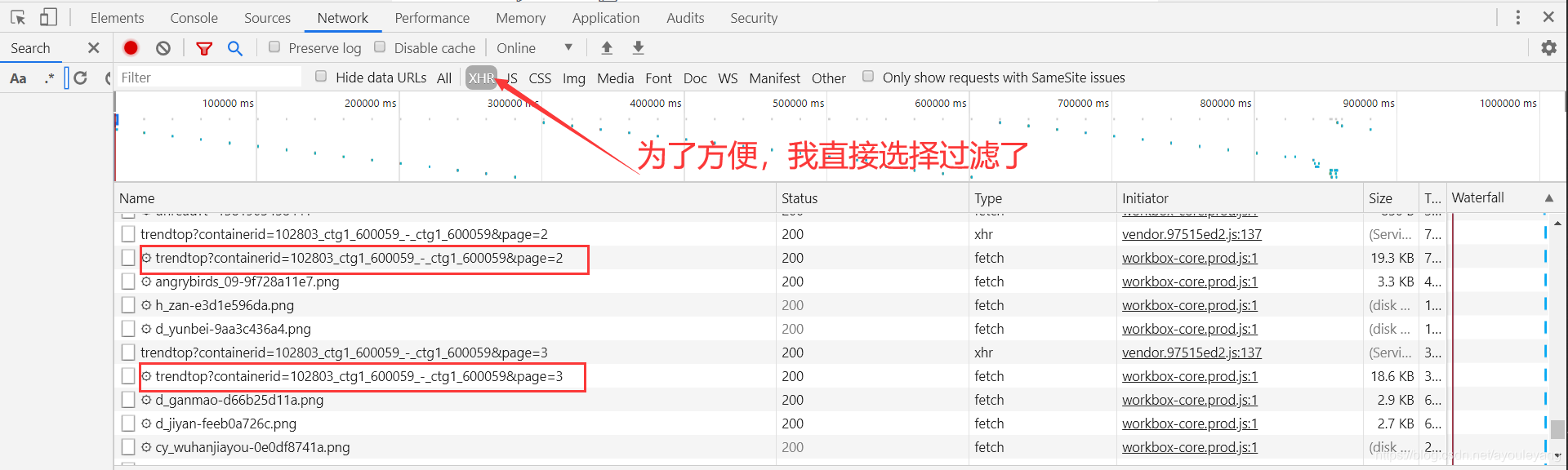
可以很明显的看出,它的当前链接就只是带上了&page=当前数字 的标签,并且每次加载出18篇动态文章
3.2、怎么解析美化json数据
现在我们拿到的数据是json格式,再提取信息前需要把 str文本 转化为json数据,进行查找
可以使用json库查看它的结构 ,也 可以在线json解析 查看它的结构,更推荐在线解析,方法结构比较清晰
方法一:json.loads()
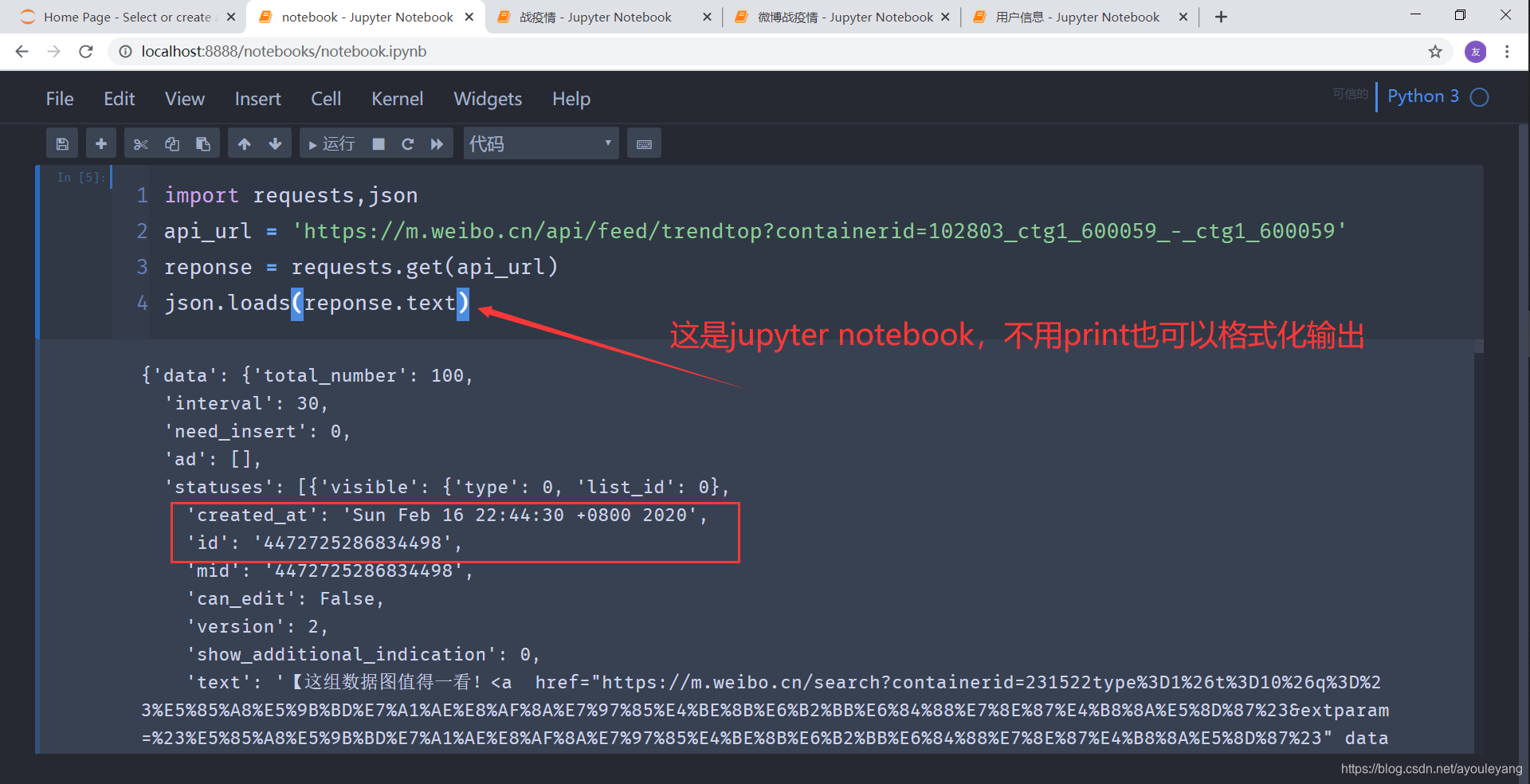
- python格式化的包
pprint也可以直接美化它
方法二:在线解析
结构把结果复制到在线解析网页中就可以查看结果啦,上面 1.2.1、方法一:抓包 讲过方法
3.3、怎么提取json数据
在线解析后的结果,简单的给它打上标签,每一个等级为一块,一级包括二级和三级,二级包括三级… 然后通过前面的标签进行迭代输出,索引出来
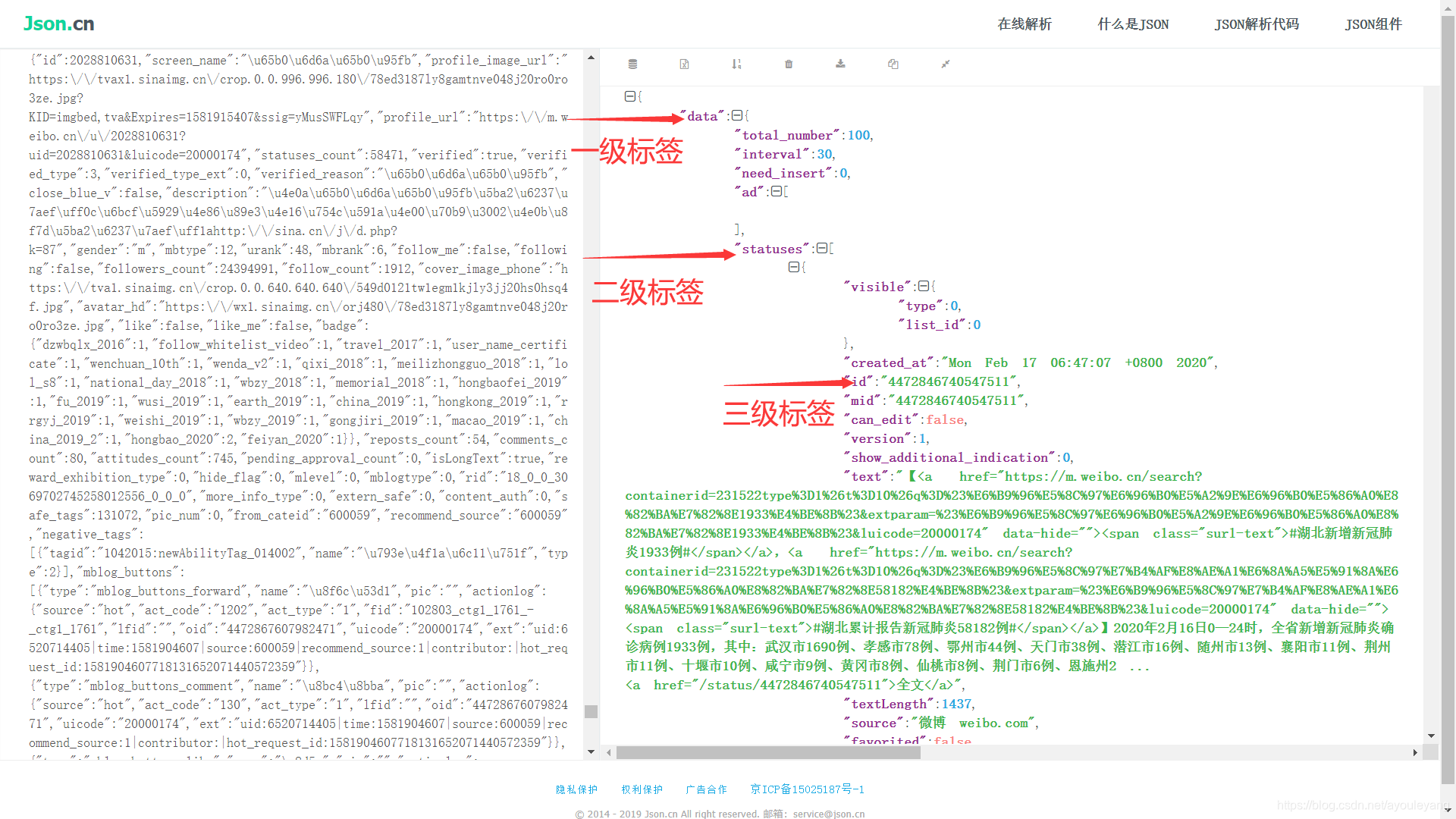
方法实现:
import requests
api_url = 'https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_600059_-_ctg1_600059'
reponse = requests.get(api_url)
for json in reponse.json()['data']['statuses']:
comment_ID = json['id']
print (comment_ID)
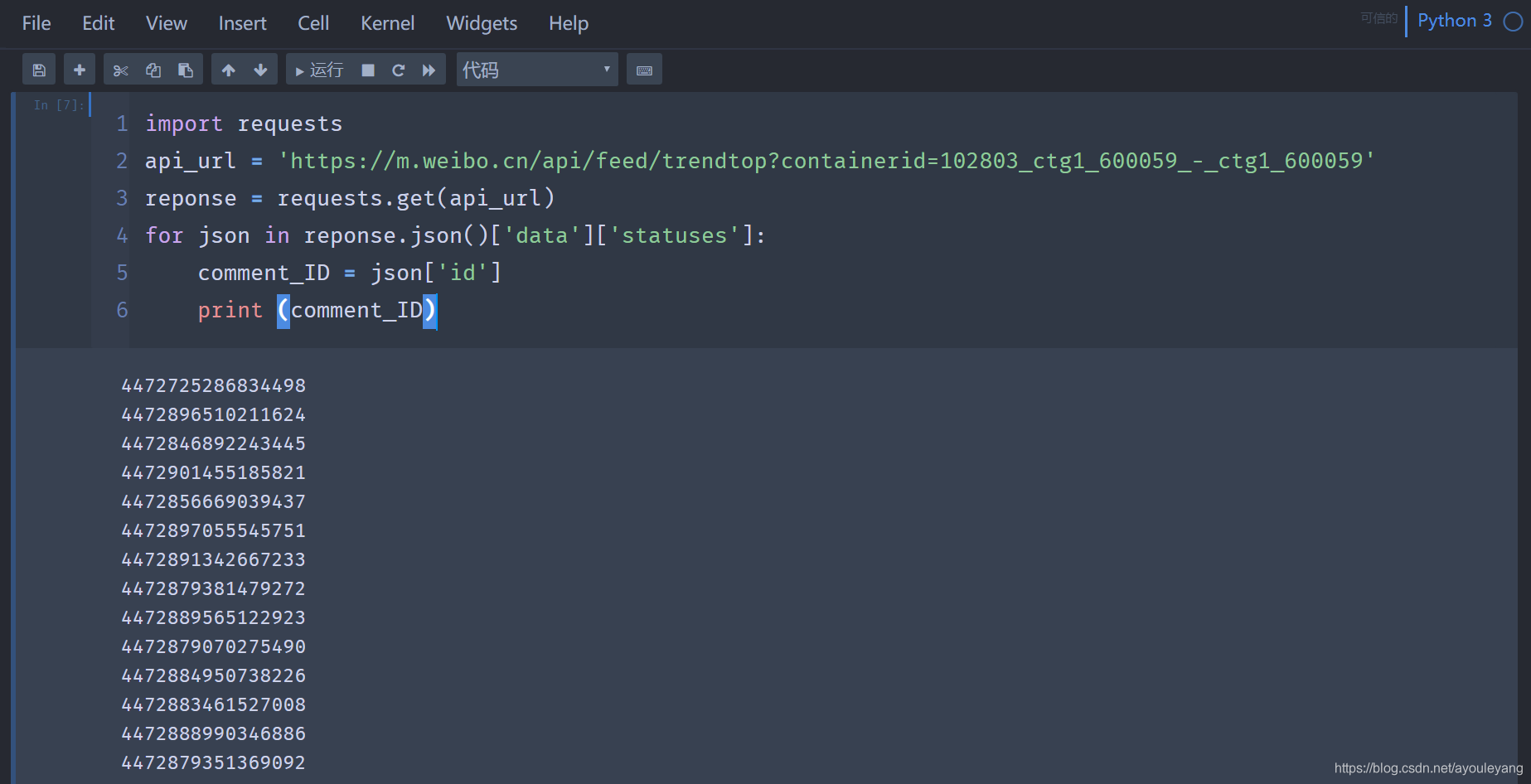
然后把拿到的id加在https://m.weibo.cn/detail/ 的后面就可以访问具体的文章了
3.4、提取所有链接代码汇总
import requests,time
from fake_useragent import UserAgent
comment_urls = []
def get_title_id():
'''爬取战疫情首页的每个主题的ID'''
for page in range(1,3):# 这是控制ajax通道的量
headers = {
"User-Agent" : UserAgent().chrome #chrome浏览器随机代理
}
time.sleep(2)
# 该链接通过抓包获得
api_url = 'https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_600059_-_ctg1_600059&page=' + str(page)
print (api_url)
rep = requests.get(url=api_url, headers=headers)
for json in rep.json()['data']['statuses']:
comment_url = 'https://m.weibo.cn/detail/' + json['id']
print (comment_url)
comment_urls.append(comment_url)
get_title_id()
输出结果:
https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_600059_-_ctg1_600059&page=1
https://m.weibo.cn/detail/4472725286834498
https://m.weibo.cn/detail/4472896510211624
https://m.weibo.cn/detail/4472846892243445
https://m.weibo.cn/detail/4472901455185821
https://m.weibo.cn/detail/4472856669039437
https://m.weibo.cn/detail/4472897055545751
https://m.weibo.cn/detail/4472891342667233
https://m.weibo.cn/detail/4472879381479272
https://m.weibo.cn/detail/4472889565122923
https://m.weibo.cn/detail/4472884950738226
https://m.weibo.cn/detail/4472883461527008
https://m.weibo.cn/detail/4472904014106917
......
现在成功的拿到了每个文章的链接,接下来可以使用 selenium 控制浏览器 进行爬虫了
4、selenium爬取评论
如果对它不熟悉,可以先看看它的文档,也可以在上面1.2.2.1、对selenium库的基本用法认识 了解它的基本用法。
实战思路:
- 自定义浏览器
- 登录微博,让浏览器记录cookie值
- 通过ajax获取文章链接
- 分别访问每篇文章
- 通过评论数判断下拉次数,进行下拉加载数据
- 下拉完成后就获取源码
- 解析网页提取信息
- 保存数据
import requests,json,time,random
from fake_useragent import UserAgent
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from lxml import etree
startTime = time.time() #记录起始时间
driver = webdriver.Chrome()
driver.implicitly_wait(5)
chrome_option = webdriver.ChromeOptions()
chrome_option.add_argument('--proxy--server=112.84.55.122:9999')#使用代理IP
fileName = "./微博战疫情.txt"
comment_urls = [] #盛放每个动态的链接
def login_weibo():
'''登录微博,获取cookie值'''
login_url = 'https://passport.weibo.cn/signin/login'
driver.get(login_url)#打开网页网页
driver.find_element_by_id('loginName').send_keys('13985968945')
driver.find_element_by_id('loginPassword').send_keys('ayouleyang')
time.sleep(1)
driver.find_element_by_id('loginAction').click()
time.sleep(20)#验证码,需要自己动手验证
def get_title_id():
'''爬取战疫情首页的每个主题的ID'''
for page in range(1,11):
headers = {
"User-Agent" : UserAgent().chrome #chrome浏览器随机代理
}
time.sleep(2)
# 该链接通过抓包获得
api_url = 'https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_600059_-_ctg1_600059&page=' + str(page)
print (api_url)
rep = requests.get(url=api_url, headers=headers)
for json in rep.json()['data']['statuses']:
comment_url = 'https://m.weibo.cn/detail/' + json['id']
comment_urls.append(comment_url)
# print (comment_url)
def spider_comments():
'''爬取所有评论并保存'''
comment_url_sum = len(comment_urls)
js="var q=document.documentElement.scrollTop=10000000" #滚动条
for count,comment_url in enumerate(comment_urls):
driver.get(comment_url)
driver.implicitly_wait(5)
try:
#获取评论
comment_number = driver.find_element_by_xpath('//div[@class="lite-page-tab"]/div[2]/i[2]').text
print ("正在爬取第%s个话题,该话题包括%s条评论,总共有%s个话题"%(count+1, comment_number,comment_url_sum))
if int(comment_number) > 20: #低于20条的评论不用下拉加载
comment_number = int(int(comment_number) / 20) #每次下拉都加载20条评论
for i in range(comment_number):
driver.execute_script(js)#调用js,将页面拖到底
time.sleep(random.uniform(0, 1.2)) #暂停时间:0~1.2秒
source = driver.page_source
html_etree = etree.HTML(source)
#爬取主题文字
title = html_etree.xpath('//div[@class="weibo-text"]/text()')[0]
with open(fileName,'a', encoding='utf-8') as f:
f.write(title)
f.close()
# 获取所有评论
div_item = html_etree.xpath('//*[@id="app"]/div[1]/div/div[3]/div[2]/div')
for item in div_item:
try:
comments = item.xpath('./div/div/div/div/div[2]/div[1]/div/div/h3/text()')[0]
# 保存数据
with open(fileName,'a', encoding='utf-8') as f:
f.write(str(comments))
f.close()
except:
pass
except:
print ("该页面无法查看")
if __name__ == '__main__':
login_weibo()
get_title_id()
spider_comments()
endTime =time.time()#获取结束时的时间
useTime =(endTime-startTime)/60
print ("该次所获的信息一共使用%s分钟"%useTime)
5、requests ajax 爬取更多信息
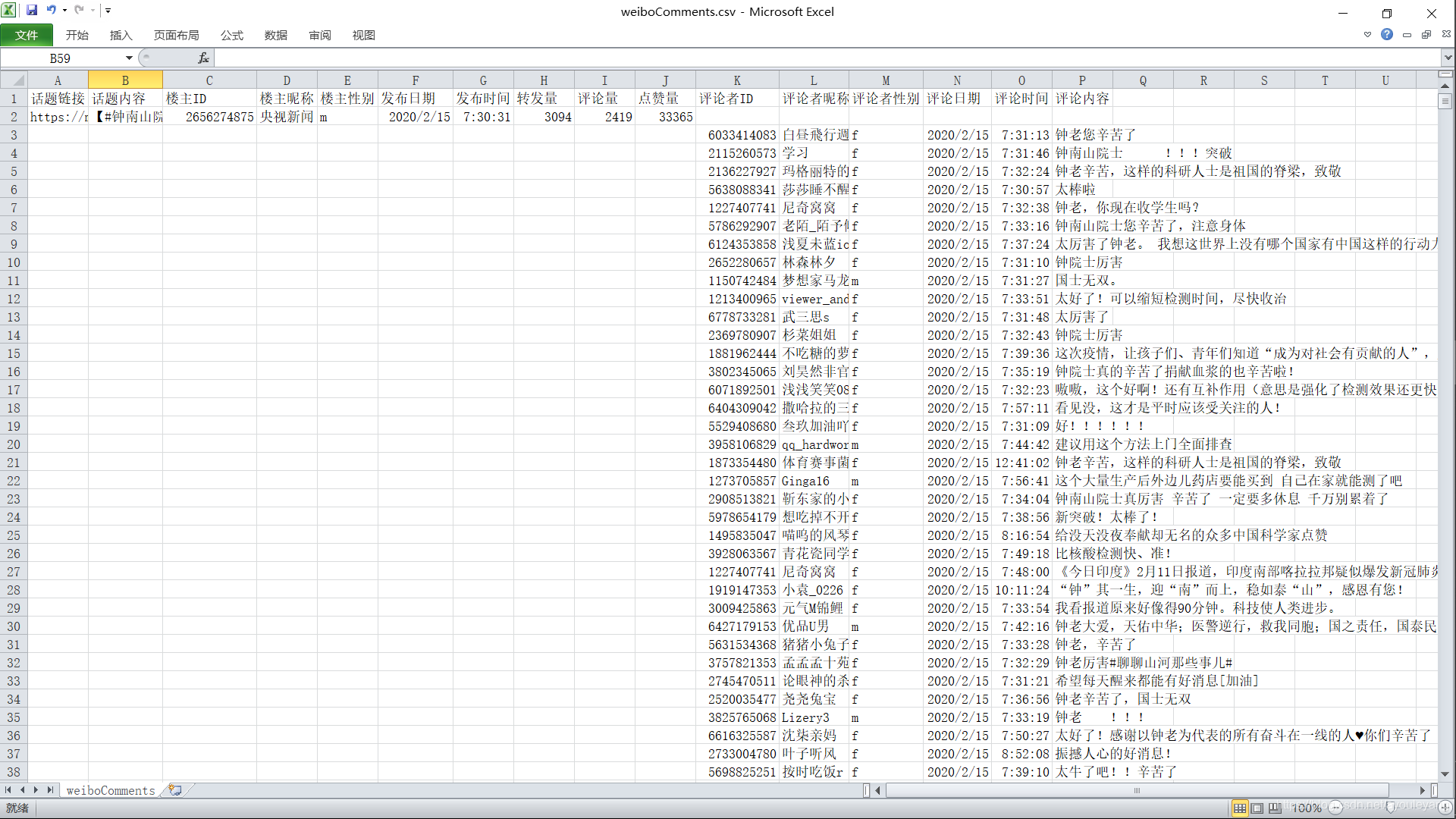
目标:话题链接、话题内容、楼主ID、楼主昵称、楼主性别、发布日期、发布时间、转发量、评论量、点赞量、评论者ID、评论者昵称、评论者性别、评论日期、评论时间、评论内容
现在我需要获取更多的信息,如用户id, 性别之类的,这就不是selenium可以完成的操作了,还得使用ajax的方式获取json数据,提取详细的信息;如果您看了1.2.1、方法一:抓包 ,相信也几乎明白了,上面遗留的 max_id 问题,其实找到这个也不难,始终坚信计算机数据不可能无中生有,一定是在某地我们没有找到。果不其然,它就在上一个json文件底部。
- 第一个通道
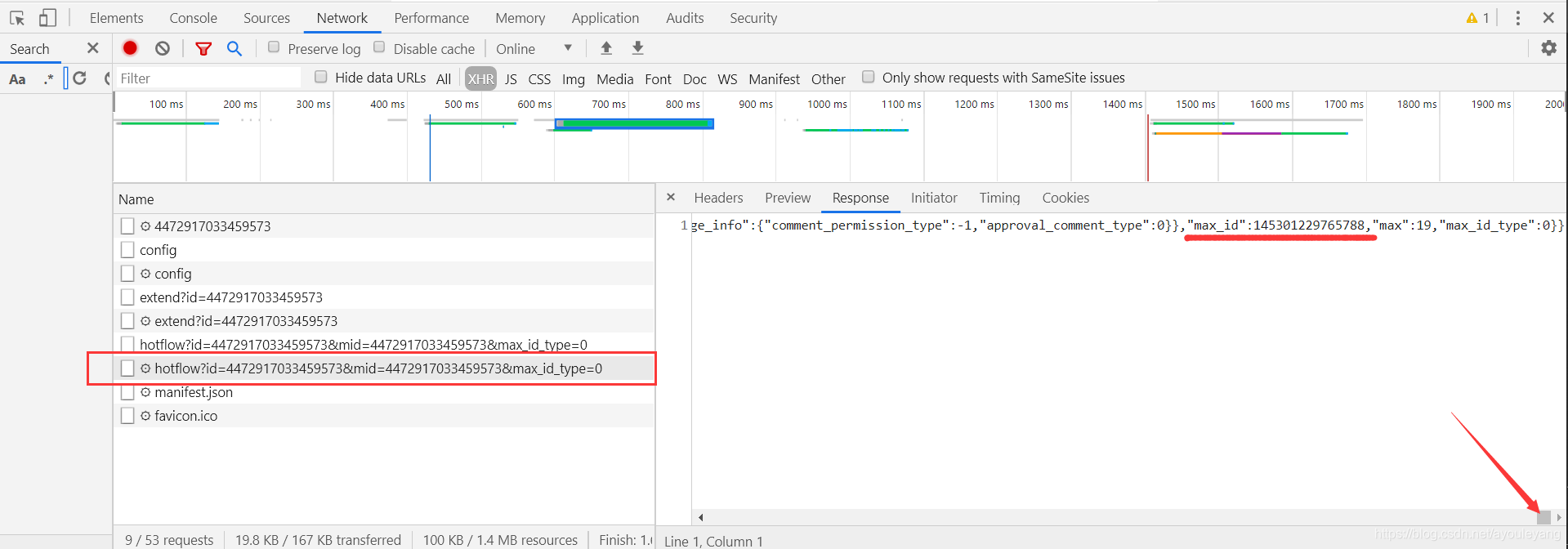
- 现在可以预测下一个
max_id了
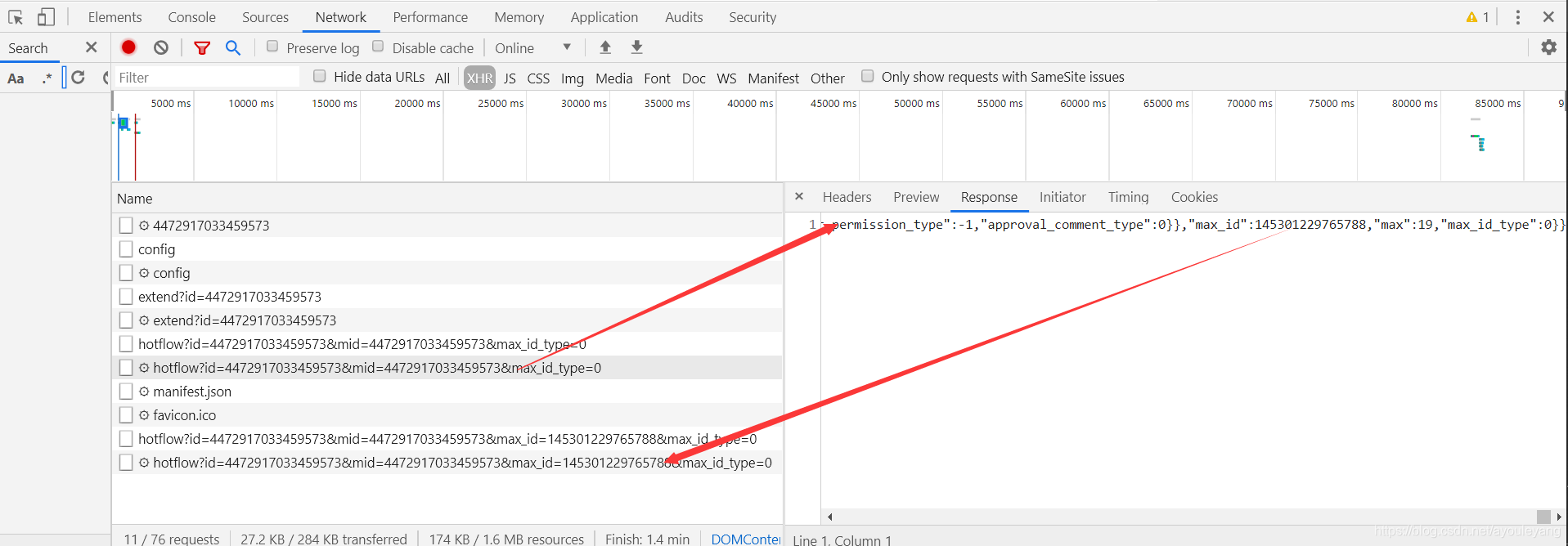
成功的通过上一个通道拿到了下一个通道的max_id,现在不就可以使用ajax加载数据了吗
贴上全部代码
# -*- coding: utf-8 -*-
import requests,random,re
import time
import os
import csv
import sys
import json
import importlib
importlib.reload(sys)
from fake_useragent import UserAgent
from lxml import etree
startTime = time.time() #记录起始时间
# 存为csv
path = os.getcwd() + "/weiboComments.csv"
csvfile = open(path, 'a', newline='', encoding = 'utf-8-sig')
writer = csv.writer(csvfile)
writer.writerow(('话题链接','话题内容','楼主ID', '楼主昵称', '楼主性别','发布日期', '发布时间', '转发量','评论量','点赞量', '评论者ID', '评论者昵称', '评论者性别', '评论日期', '评论时间','评论内容')) #csv头部
headers = {
'Cookie': '_T_WM=22822641575; H5_wentry=H5; backURL=https%3A%2F%2Fm.weibo.cn%2F; ALF=1584226439; MLOGIN=1; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5RJaVYrb.BEuOvUQ8Ca2OO5JpX5K-hUgL.FoqESh-7eKzpShM2dJLoIp7LxKML1KBLBKnLxKqL1hnLBoMceoBfeh2EeKBN; SCF=AnRSOFp6QbWzfH1BqL4HB8my8eWNC5C33KhDq4Ko43RUIzs6rjJC49kIvz5_RcOJV2pVAQKvK2UbAd1Uh6j0pyo.; SUB=_2A25zQaQBDeRhGeBM71cR8SzNzzuIHXVQzcxJrDV6PUJbktAKLXD-kW1NRPYJXhsrLRnku_WvhsXi81eY0FM2oTtt; SUHB=0mxU9Kb_Ce6s6S; SSOLoginState=1581634641; WEIBOCN_FROM=1110106030; XSRF-TOKEN=dc7c27; M_WEIBOCN_PARAMS=oid%3D4471980021481431%26luicode%3D20000061%26lfid%3D4471980021481431%26uicode%3D20000061%26fid%3D4471980021481431',
'Referer': 'https://m.weibo.cn/detail/4312409864846621',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
comments_ID = []
def get_title_id():
'''爬取战疫情首页的每个主题的ID'''
for page in range(1,21):# 每个页面大约有18个话题
headers = {
"User-Agent" : UserAgent().chrome #chrome浏览器随机代理
}
time.sleep(1)
# 该链接通过抓包获得
api_url = 'https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_600059_-_ctg1_600059&page=' + str(page)
print (api_url)
rep = requests.get(url=api_url, headers=headers)
for json in rep.json()['data']['statuses']:
comment_ID = json['id']
comments_ID.append(comment_ID)
def spider_title(comment_ID):
try:
article_url = 'https://m.weibo.cn/detail/'+ comment_ID
print ("article_url = ", article_url)
html_text = requests.get(url=article_url, headers=headers).text
# 话题内容
find_title = re.findall('.*?"text": "(.*?)",.*?', html_text)[0]
title_text = re.sub('<(S*?)[^>]*>.*?|<.*? />', '', find_title) #正则匹配掉html标签
print ("title_text = ", title_text)
# 楼主ID
title_user_id = re.findall('.*?"id": (.*?),.*?', html_text)[1]
print ("title_user_id = ", title_user_id)
# 楼主昵称
title_user_NicName = re.findall('.*?"screen_name": "(.*?)",.*?', html_text)[0]
print ("title_user_NicName = ", title_user_NicName)
# 楼主性别
title_user_gender = re.findall('.*?"gender": "(.*?)",.*?', html_text)[0]
print ("title_user_gender = ", title_user_gender)
# 发布时间
created_title_time = re.findall('.*?"created_at": "(.*?)".*?', html_text)[0].split(' ')
#日期
if 'Feb' in created_title_time:
title_created_YMD = "{}/{}/{}".format(created_title_time[-1], '02', created_title_time[2])
elif 'Jan' in created_title_time:
title_created_YMD = "{}/{}/{}".format(created_title_time[-1], '01', created_title_time[2])
else:
print ('该时间不在疫情范围内,估计数据有误!URL = ')
pass
print ("title_created_YMD = ", title_created_YMD)
#发布时间
add_title_time = created_title_time[3]
print ("add_title_time = ", add_title_time)
# 转发量
reposts_count = re.findall('.*?"reposts_count": (.*?),.*?', html_text)[0]
print ("reposts_count = ", reposts_count)
# 评论量
comments_count = re.findall('.*?"comments_count": (.*?),.*?', html_text)[0]
print ("comments_count = ", comments_count)
# 点赞量
attitudes_count = re.findall('.*?"attitudes_count": (.*?),.*?', html_text)[0]
print ("attitudes_count = ", attitudes_count)
comment_count = int(int(comments_count) / 20)#每个ajax一次加载20条数据,
position1 = (article_url, title_text, title_user_id, title_user_NicName,title_user_gender, title_created_YMD, add_title_time, reposts_count, comments_count, attitudes_count, " ", " ", " ", " "," ", " ")
writer.writerow((position1))#写入数据
return comment_count
except:
pass
def get_page(comment_ID, max_id, id_type):
params = {
'max_id': max_id,
'max_id_type': id_type
}
url = ' https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id'.format(comment_ID, comment_ID)
try:
r = requests.get(url, params=params, headers=headers)
if r.status_code == 200:
return r.json()
except requests.ConnectionError as e:
print('error', e.args)
pass
def parse_page(jsondata):
if jsondata:
items = jsondata.get('data')
item_max_id = {}
item_max_id['max_id'] = items['max_id']
item_max_id['max_id_type'] = items['max_id_type']
return item_max_id
def write_csv(jsondata):
for json in jsondata['data']['data']:
#用户ID
user_id = json['user']['id']
# 用户昵称
user_name = json['user']['screen_name']
# 用户性别,m表示男性,表示女性
user_gender = json['user']['gender']
#获取评论
comments_text = json['text']
comment_text = re.sub('<(S*?)[^>]*>.*?|<.*? />', '', comments_text) #正则匹配掉html标签
# 评论时间
created_times = json['created_at'].split(' ')
if 'Feb' in created_times:
created_YMD = "{}/{}/{}".format(created_times[-1], '02', created_times[2])
elif 'Jan' in created_times:
created_YMD = "{}/{}/{}".format(created_times[-1], '01', created_times[2])
else:
print ('该时间不在疫情范围内,估计数据有误!')
pass
created_time = created_times[3] #评论时间时分秒
# if len(comment_text) != 0:
position2 = (" ", " ", " ", " "," ", " ", " ", " ", " ", " ", user_id, user_name, user_gender, created_YMD, created_time, comment_text)
writer.writerow((position2))#写入数据
# print (user_id, user_name, user_gender, created_YMD, created_time)
def main():
count_title = len(comments_ID)
for count, comment_ID in enumerate(comments_ID):
print ("正在爬取第%s个话题,一共找到个%s话题需要爬取"%(count+1, count_title))
maxPage = spider_title(comment_ID) # 评论占的最大页数
print ('maxPage = ', maxPage)
m_id = 0
id_type = 0
if maxPage != 0: #小于20条评论的不需要循环
try:
for page in range(0, maxPage):#用评论数量控制循环
jsondata = get_page(comment_ID, m_id, id_type)
write_csv(jsondata)
results = parse_page(jsondata)
time.sleep(1)
m_id = results['max_id']
id_type = results['max_id_type']
except:
pass
print ("--------------------------分隔符---------------------------")
csvfile.close()
if __name__ == '__main__':
get_title_id()
main()
endTime =time.time()#获取结束时的时间
useTime =(endTime-startTime)/60
print ("该次所获的信息一共使用%s分钟"%useTime)
编辑器运行结果:
https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_600059_-_ctg1_600059&page=1
https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_600059_-_ctg1_600059&page=2
......
https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_600059_-_ctg1_600059&page=18
https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_600059_-_ctg1_600059&page=19
https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_600059_-_ctg1_600059&page=20
正在爬取第1个话题,一共找到个361话题需要爬取
article_url = https://m.weibo.cn/detail/4472132886924452
title_text = 【#钟南山院士指导研发快速检测试剂盒# #采一滴血15分钟内可获检测结果#】昨天,呼吸疾病国家重点实验室对外透露,近日,在钟南山院士的指导下,实验室联合多家研究机构,最新研发出新型冠状病毒IgM抗体快速检测试剂盒,并已在实验室和临床完成初步评价。据介绍,仅需采取一滴血就可在15分钟内肉眼观察获得检测结果,且患者的血浆稀释500至1000倍后,仍能检测出阳性条带。呼吸疾病国家重点实验室表示,这一试剂盒在湖北某医院进行了应用试验。通过对部分临床已确诊为新型冠状病毒感染阳性(但PCR核酸检测阴性的)患者血样进行复检,该试剂盒能检出相当部分(IgM)阳性,提示可与核酸检测形成互补。目前该试剂盒(科研用)样品已大批送至湖北省武汉市、黄冈市、大冶市等地基层卫生机构等,与核酸检测等技术联合用于检测新型冠状病毒感染的测试评估。(总台央视记者陈旭婷)
title_user_id = 2656274875
title_user_NicName = 央视新闻
title_user_gender = m
title_created_YMD = 2020/02/15
add_title_time = 07:30:31
reposts_count = 3094
comments_count = 2419
attitudes_count = 33365
maxPage = 120
--------------------------分隔符---------------------------
正在爬取第2个话题,一共找到个361话题需要爬取
article_url = https://m.weibo.cn/detail/4472213728267581
title_text = 【#新冠病毒疫苗研发已完成基因序列合成#】2月15日中国医药集团有限公司在京披露,该集团与中国疾病预防控制中心合作,新型冠状病毒疫苗的研发已经取得进展。国药集团旗下的国药中生研究院启动了新型冠状病毒基因工程疫苗研发,现已完成了基因序列合成,正在进行重组质粒构建和工程菌筛选工作。国药集团方面进一步介绍,目前国药集团正在多路出击,攻坚新冠病毒疫苗的研发。其中国药中生武汉公司也担负着新型冠状病毒疫苗的研发任务,目前正在持续进行病毒培养。国药中生北京公司则与中国疾病预防控制中心紧密合作,正在开发新型冠状病毒灭活疫苗,目前正在进行毒种库的建库工作。据介绍,研究发现在新冠康复者血浆中,有着丰富的新型冠状病毒综合抗体。为此,国药中生在研究中还提出了“用新冠康复者血浆治疗危重患者”的建议,并已获得科技部紧急立项。目前国药中生已按照国家卫健委和国家药监局的标准制备了新冠康复者血浆,并用于11名危重病人治疗。在使用“血浆疗法”后,截至目前所有治疗的危重病人未发生任何不良反应,各项重要检测指标全面向好。其中一位86岁危重患者应用此治疗方案后,临床体征和症状已经获得了明显改善。现在国药中生又开始用新冠康复者血浆治疗另外12例危重患者,并发出公开倡议,呼吁能有更多的新冠康复者献出自己的一份血浆。同时国药集团方面表示,新冠康复者献出的血浆将接受呼吸道、消化道以及其他传染病等30多种致病病原体的检测,随后这一血浆也将接受灭活处理,所以能保障患者的安全使用。当日在武汉大学人民医院的献血屋内,国药集团的工作人员在现场连线时介绍,目前已有20多人提出明确的捐赠意向,昨天这一献血屋已成功采集了3位康复者的血浆,今天则有5人预计将来现场献出自己的血浆。另外经过紧急扩产,国药集团所属中生捷诺的新冠病毒诊断试剂盒产能目前已经放大到每天20万人份。(北京日报客户端)
title_user_id = 1618051664
title_user_NicName = 头条新闻
title_user_gender = f
title_created_YMD = 2020/02/15
add_title_time = 12:51:45
reposts_count = 321
comments_count = 180
attitudes_count = 1756
maxPage = 9
--------------------------分隔符---------------------------
正在爬取第3个话题,一共找到个361话题需要爬取
.......
保存数据截图:
这个代码还可以进行优化,比如 spider_title(comment_ID) 模块,也可以使用ajax加载,在 3、首页具体动态链接获取 中就有关于这个方法的介绍,它的信息全部在这个json文件中,直接提取出来就行啦,这里就不多介绍了~
万众一心,众志成城,全民抗击疫情,在家里也不要忘记学习哈,中国加油,武汉加油!!!
