1.在Transformer中实现单向语言模型
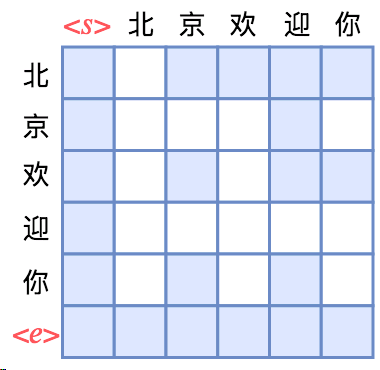
如图所示,Attention矩阵的每一行事实上代表着输出,而每一列代表着输入,而Attention矩阵就表示输出和输入的关联。对于句子“北京欢迎你”,假定白色方格都代表0,那么第1行表示“北”只能跟起始标记相关了,而第2行就表示“京”只能跟起始标记和“北”相关了,依此类推。所以,只需要在Transformer的Attention矩阵中引入下三角形形式的Mask,并将输入输出错开一位训练,就可以实现单向语言模型了。

2.Transformer实现乱序语言模型
还是以“北京欢迎你”的生成为例,假设随机的一种生成顺序为“ → 迎 → 京 → 你 → 欢 → 北 →
打乱后的Mask似乎没看出什么规律呀,难道每次都要随机生成一个这样的似乎没有什么明显概率的Mask矩阵?事实上有一种更简单的、数学上等效的训练方案。这个训练方案源于纯Attention的模型本质上是一个无序的模型,它里边的词序实际上是通过Position Embedding加上去的。也就是说,我们输入的不仅只有token本身,还包括token所在的位置id;再换言之,你觉得你是输入了序列“[北, 京, 欢, 迎, 你]”,实际上你输入的是集合“{(北, 1), (京, 2), (欢, 3), (迎, 4), (你, 5)}”。

3.思考:XLNET这么做真的有意义么?
很长一段时间,我能理解XLNET的模型实现机理,但是不理解为什么这种方式就是有效,深入参考了张俊林博士的https://zhuanlan.zhihu.com/p/70257427终于理解了。
假设仍然利用Bert目前的Mask机制,但是把Mask掉15%这个条件极端化,改成,每次一个句子只Mask掉一个单词,利用剩下的单词来预测被Mask掉的单词。那么,这个过程其实跟XLNet的PLM也是比较相像的,区别主要在于每次预测被Mask掉的单词的时候,利用的上下文更多一些(XLNet在实现的时候,为了提升效率,其实也是选择每个句子最后末尾的1/K单词被预测,假设K=7,意味着一个句子X,只有末尾的1/7的单词会被预测,这意味着什么呢?意味着至少保留了6/7的Context单词去预测某个单词,对于最末尾的单词,意味着保留了所有的句子中X的其它单词,这其实和上面提到的Bert只保留一个被Mask单词是一样的)。或者我们站在Bert预训练的角度来考虑XLNet,如果XLNet改成对于句子X,只需要预测句子中最后一个单词,而不是最后的1/K(就是假设K特别大的情况),那么其实和Bert每个输入句子只Mask掉一个单词,两者基本是等价的。