
-
论文地址:https://arxiv.org/pdf/1906.08237.pdf
-
预训练模型及代码地址:https://github.com/zihangdai/xlnet
-
论文原理:(张俊林老师--讲的比较透彻) XLNet:运行机制及和Bert的异同比较 https://zhuanlan.zhihu.com/p/70257427
摘要
作者表示,BERT 这样基于去噪自编码器的预训练模型可以很好地建模双向语境信息,性能优于基于自回归语言模型的预训练方法。然而,由于需要 mask 一部分输入,BERT 忽略了被 mask 位置之间的依赖关系,因此出现预训练和微调效果的差异(pretrain-finetune discrepancy)。
基于这些优缺点,该研究提出了一种泛化的自回归预训练模型 XLNet。XLNet 可以:1)通过最大化所有可能的因式分解顺序的对数似然,学习双向语境信息;2)用自回归本身的特点克服 BERT 的缺点。此外,XLNet 还融合了当前最优自回归模型 Transformer-XL 的思路。
最终,XLNet 在 20 个任务上超过了 BERT 的表现,并在 18 个任务上取得了当前最佳效果(state-of-the-art),包括机器问答、自然语言推断、情感分析和文档排序。
以前超越 BERT 的模型很多都在它的基础上做一些修改,本质上模型架构和任务都没有太大变化。但是在这篇新论文中,作者从自回归(autoregressive)和自编码(autoencoding)两大范式分析了当前的预训练语言模型,并发现它们虽然各自都有优势,但也都有难以解决的困难。为此,研究者提出 XLNet,并希望结合大阵营的优秀属性。
1、介绍
1.1 AR 与 AE 两大阵营
什么是 XLNet
首先,XLNet 是一个类似 BERT 的模型,而不是完全不同的模型。总之,XLNet是一种通用的自回归预训练方法。
那么什么是自回归(AR)语言模型?
AR语言模型是一种使用上下文词来预测下一个词的模型。但是在这里,上下文单词被限制在两个方向,前向或后向。
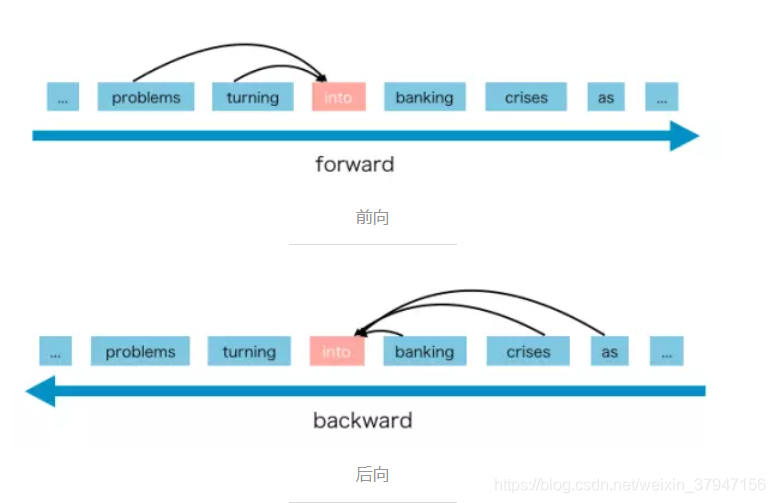
AR 语言模型的优势是擅长生成式自然语言处理任务。 因为在生成上下文时,通常是前向的。AR 语言模型很自然地适用于此类 NLP 任务。
但AR语言模型有一些缺点,它只能使用前向上下文或后向上下文,这意味着它不能同时使用前向和后向上下文。
XLNet和BERT有什么区别
与 AR 语言模型不同,BERT 被归类为自动编码器(AE)语言模型。
AE 语言模型旨在从损坏的输入重建原始数据。
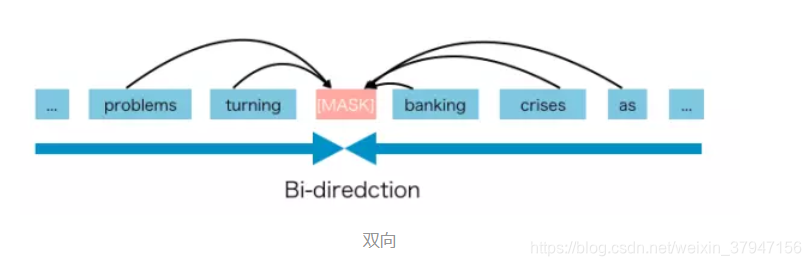
损坏的输入意味着我们在预训练阶段用 [MASK] 替换原始词 into。目标是预测 into 得到原始句子。
AE 语言模型的优势是,它可以从向前和向后的方向看到上下文。
但 AE 语言模型也有其缺点。它在预训练中使用 [MASK],但这种人为的符号在调优时在真实数据中并不存在,会导致预训练-调优的差异。[MASK] 的另一个缺点是它假设预测(掩蔽的)词 在给定未屏蔽的 词 的情况下彼此独立。例如,我们有一句话“它表明住房危机已经变成银行危机”。我们掩蔽“银行业”和“危机”。在这里注意,我们知道掩蔽的“银行业”和“危机”包含彼此的隐含关系。但 AE 模型试图预测“银行业”给予未掩蔽的 词,并预测“危机”分别给出未掩蔽的 词。它忽略了“银行业”与“危机”之间的关系。换句话说,它假设预测(掩蔽)的标记彼此独立。但是我们知道模型应该学习预测(掩蔽)词之间的这种相关性来预测其中一个词。
作者想要强调的是,XLNet 提出了一种让 AR 语言模型从双向上下文中学习的新方法,以避免 MASK 方法在 AE 语言模型中带来的缺点。
1.2 两大阵营间需要新的 XLNet
现有的语言预训练目标各有优劣,这篇新研究提出了一种泛化自回归方法 XLNet,既集合了 AR 和 AE 方法的优势,又避免了二者的缺陷。
首先,XLNet 不使用传统 AR 模型中固定的前向或后向因式分解顺序,而是最大化所有可能因式分解顺序的期望对数似然。由于对因式分解顺序的排列操作,每个位置的语境都包含来自左侧和右侧的 token。因此,每个位置都能学习来自所有位置的语境信息,即捕捉双向语境。
其次,作为一个泛化 AR 语言模型,XLNet 不依赖残缺数据。因此,XLNet 不会有 BERT 的预训练-微调差异。同时,自回归目标提供一种自然的方式,来利用乘法法则对预测 token 的联合概率执行因式分解(factorize),这消除了 BERT 中的独立性假设。
除了提出一个新的预训练目标,XLNet 还改进了预训练的架构设计。
受到 AR 语言建模领域最新进展的启发,XLNet 将 Transformer-XL 的分割循环机制(segment recurrence mechanism)和相对编码范式(relative encoding)整合到预训练中,实验表明,这种做法提高了性能,尤其是在那些包含较长文本序列的任务中。
简单地使用 Transformer(-XL) 架构进行基于排列的(permutation-based)语言建模是不成功的,因为因式分解顺序是任意的、训练目标是模糊的。因此,研究人员提出,对 Transformer(-XL) 网络的参数化方式进行修改,移除模糊性。
2、被提议的方法
2.1 背景
在论文里作者使用了一些术语,比如自回归(Autoregressive, AR)语言模型和自编码(autoencoding)模型等,这可能让不熟悉的读者感到困惑,因此我们先简单的解释一下。自回归是时间序列分析或者信号处理领域喜欢用的一个术语,我们这里理解成语言模型就好了:一个句子的生成过程如下:首先根据概率分布生成第一个词,然后根据第一个词生成第二个词,然后根据前两个词生成第三个词,……,直到生成整个句子。而所谓的自编码器是一种无监督学习输入的特征的方法:我们用一个神经网络把输入(输入通常还会增加一些噪声)变成一个低维的特征,这就是编码部分,然后再用一个Decoder尝试把特征恢复成原始的信号。我们可以把BERT看成一种AutoEncoder,它通过Mask改变了部分Token,然后试图通过其上下文的其它Token来恢复这些被Mask的Token。如果读者不太理解或者喜欢这两个jargon,忽略就行了。
给定文本序列x=[x1,…,xT],语言模型的目标是调整参数使得训练数据上的似然函数最大:
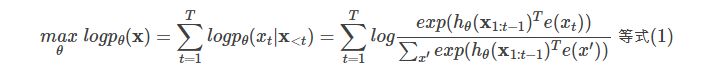
记号x<t表示t时刻之前的所有x,也就是x1:t−1。hθ(x1:t−1)是RNN或者Transformer(注:Transformer也可以用于语言模型,比如在OpenAI GPT)编码的t时刻之前的隐状态。e(x)是词x的embedding。
而BERT是去噪(denoising)自编码的方法。对于序列xx,BERT会随机挑选15%的Token变成[MASK]得到带噪声版本的x^。假设被Mask的原始值为x¯,那么BERT希望尽量根据上下文恢复(猜测)出原始值了,也就是:
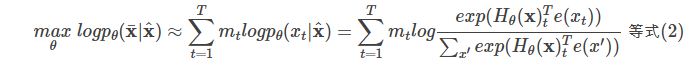
上式中mt=1表示t时刻是一个Mask,需要恢复。Hθ是一个Transformer,它把长度为TT的序列xx映射为隐状态的序列Hθ(x)=[Hθ(x)1,Hθ(x)2,...,Hθ(x)T]。注意:前面的语言模型的RNN在t时刻只能看到之前的时刻,因此记号是hθ(x1:t−1);而BERT的Transformer(不同与用于语言模型的Transformer)可以同时看到整个句子的所有Token,因此记号是Hθ(x)。
这两个模型的优缺点分别为:
- 独立假设
- 注意等式(2)的约等号≈≈,它的意思是假设在给定x^x^的条件下被Mask的词是独立的(没有关系的),这个显然并不成立,比如”New York is a city”,假设我们Mask住”New”和”York”两个词,那么给定”is a city”的条件下”New”和”York”并不独立,因为”New York”是一个实体,看到”New”则后面出现”York”的概率要比看到”Old”后面出现”York”概率要大得多。而公式(1)没有这样的独立性假设,它是严格的等号。
- 输入噪声
- BERT的在预训练时会出现特殊的[MASK],但是它在下游的fine-tuning中不会出现,这就是出现了不匹配。而语言模型不会有这个问题。
- 双向上下文
- 语言模型只能参考一个方向的上下文,而BERT可以参考双向整个句子的上下文,因此这一点BERT更好一些。
- ELMo和GPT最大的问题就是传统的语言模型是单向的——我们是根据之前的历史来预测当前词。但是我们不能利用后面的信息。比如句子”The animal didn’t cross the street because it was too tired”。我们在编码it的语义的时候需要同时利用前后的信息,因为在这个句子中,it可能指代animal也可能指代street。根据tired,我们推断它指代的是animal,因为street是不能tired。但是如果把tired改成wide,那么it就是指代street了。传统的语言模型,不管是RNN还是Transformer,它都只能利用单方向的信息。比如前向的RNN,在编码it的时候它看到了animal和street,但是它还没有看到tired,因此它不能确定it到底指代什么。如果是后向的RNN,在编码的时候它看到了tired,但是它还根本没看到animal,因此它也不能知道指代的是animal。Transformer的Self-Attention理论上是可以同时attend to到这两个词的,但是根据前面的介绍,由于我们需要用Transformer来学习语言模型,因此必须用Mask来让它看不到未来的信息,所以它也不能解决这个问题的。注意:即使ELMo训练了双向的两个RNN,但是一个RNN只能看一个方向,因此也是无法”同时”利用前后两个方向的信息的。也许有的读者会问,我的RNN有很多层,比如第一层的正向RNN在编码it的时候编码了animal和street的语义,反向RNN编码了tired的语义,然后第二层的RNN就能同时看到这两个语义,然后判断出it指代animal。理论上是有这种可能,但是实际上很难。举个反例,理论上一个三层(一个隐层)的全连接网络能够拟合任何函数,那我们还需要更多层词的全连接网络或者CNN、RNN干什么呢?如果数据不是足够足够多,如果不对网络结构做任何约束,那么它有很多中拟合的方法,其中很多是过拟合的。但是通过对网络结构的约束,比如CNN的局部特效,RNN的时序特效,多层网络的层次结构,对它进行了很多约束,从而使得它能够更好的收敛到最佳的参数。我们研究不同的网络结构(包括resnet、dropout、batchnorm等等)都是为了对网络增加额外的(先验的)约束。
2.2 目标:排列语言建模(Permutation Language Modeling)
从上面的比较可以得出,AR 语言建模和 BERT 拥有其自身独特的优势。我们自然要问,是否存在一种预训练目标函数可以取二者之长,同时又克服二者的缺点呢?
研究者借鉴了无序 NADE 中的想法,提出了一种序列语言建模目标,它不仅可以保留 AR 模型的优点,同时也允许模型捕获双向语境。具体来说,一个长度为 T 的序列 x 拥有 T! 种不同的排序方式,可以执行有效的自回归因式分解。从直觉上来看,如果模型参数在所有因式分解顺序中共享,那么预计模型将学习从两边的所有位置上收集信息。
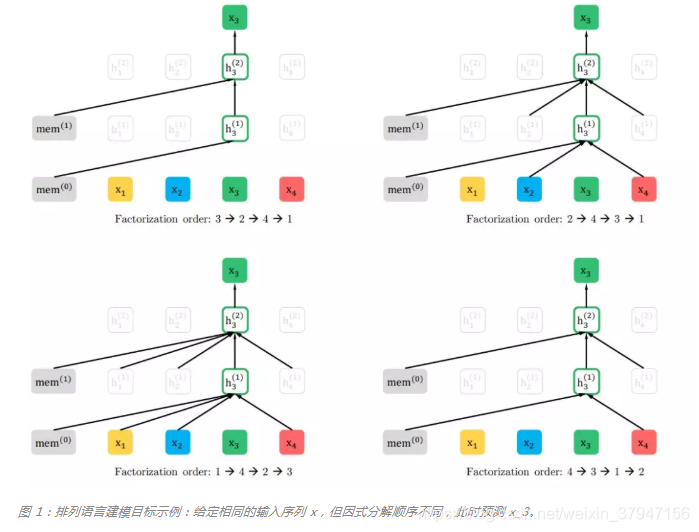
为了提供一个完整的概览图,研究者展示了一个在给定相同输入序列 x(但因式分解顺序不同)时预测 token x_3 的示例,如下图所示:比如图的左上,对应的分解方式是3→2→4→13→2→4→1,因此预测x3x3是不能attend to任何其它词,只能根据之前的隐状态memmem来预测。而对于左下,x3x3可以attend to其它3个词。
给定长度为T的序列xx,总共有T!种排列方法,也就对应T!种链式分解方法。比如假设x=x1x2x3,那么总共用3!=6种分解方法:
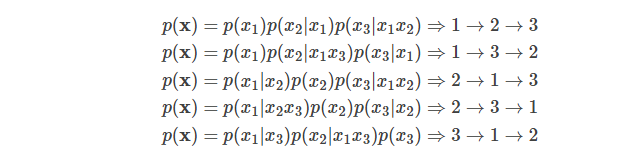
注意p(x2|x1x3)指的是第一个词是x1并且第三个词是x3的条件下第二个词是x2的概率,也就是说原来词的顺序是保持的。如果理解为第一个词是x1并且第二个词是x3的条件下第三个词是x2,那么就不对了。
如果我们的语言模型遍历T!种分解方法,并且这个模型的参数是共享的,那么这个模型应该就能(必须)学习到各种上下文。普通的从左到右或者从右往左的语言模型只能学习一种方向的依赖关系,比如先”猜”一个词,然后根据第一个词”猜”第二个词,根据前两个词”猜”第三个词,……。而排列语言模型会学习各种顺序的猜测方法,比如上面的最后一个式子对应的顺序3→1→2,它是先”猜”第三个词,然后根据第三个词猜测第一个词,最后根据第一个和第三个词猜测第二个词。
因此我们可以遍历T!种路径,然后学习语言模型的参数,但是这个计算量非常大(10!=3628800,10个词的句子就有这么多种组合)。因此实际我们只能随机的采样T!里的部分排列,为了用数学语言描述,我们引入几个记号。ZT表示长度为T的序列的所有排列组成的集合,则z∈ZT是一种排列方法。我们用zt表示排列的第t个元素,而z<t表示z的第1到第t-1个元素。
举个例子,假设T=3,那么ZT共有6个元素,我们假设其中之一z=[1,3,2],则z3=2,而z<3=[1,3]。
有了上面的记号,则排列语言模型的目标是调整模型参数使得下面的似然概率最大:

上面的公式看起来有点复杂,细读起来其实很简单:从所有的排列中采样一种,然后根据这个排列来分解联合概率成条件概率的乘积,然后加起来。
注意:上面的模型只会遍历概率的分解顺序,并不会改变原始词的顺序。实现是通过Attention的Mask来对应不同的分解方法。比如p(x1|x3)p(x2|x1x3)p(x3),我们可以在用Transformer编码x1时候让它可以Attend to x3,而把x2Mask掉;编码x3的时候把x1,x2都Mask掉。
2.3 模型架构:对目标感知表征的双流自注意力
例子一:
前面我们为预训练语言模型构建了新的任务目标,这里就需要调整 Transformer 以适应任务。如果读者了解一些 Transformer,那么就会知道某个 Token 的内容和位置向量在输入到模型前就已经加在一起了,后续的隐向量同时具有内容和位置的信息。但杨植麟说:「新任务希望在预测下一个词时只能提供位置信息,不能提供内容相关的信息。因此模型希望同时做两件事,首先它希望预测自己到底是哪个字符,其次还要能预测后面的字符是哪个。」
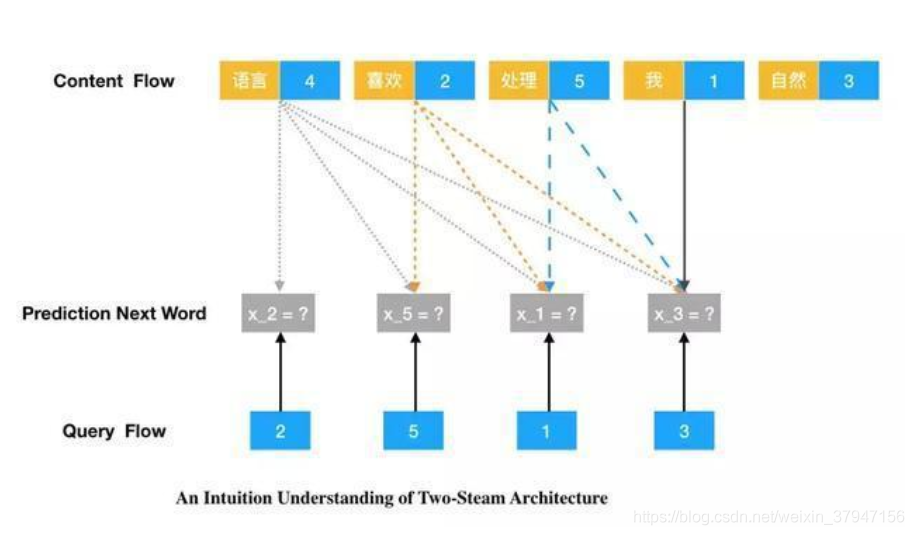
这两件事是有冲突的,如果模型需要预测位置 2 的「喜欢」,那么肯定不能用该位置的内容向量。但与此同时,位置 2 的完整向量还需要参与位置 5 的预测,且同时不能使用位置 5 的内容向量。
这类似于条件句:如果模型预测当前词,则只能使用位置向量;如果模型预测后续的词,那么使用位置加内容向量。因此这就像我们既需要标准 Transformer 提供内容向量,又要另一个网络提供对应的位置向量。
Transformer 中每个词的表征由其词向量和位置编码共同决定 -- 我们既拿到了词本身的性质,又有词的位置信息。所以 Transformer 天然就和乱序语言模型相契合。
例子二:
假设整句话为 ["我 1", "今天 2", "很 3",「开心 4」],我们只采样出一个样本 (["今天 2", "很 3", "开心 4"] → "我 1" ),XLNet 的做法和 BERT 有同有异。
和 BERT 一样,XLNet 同样是将目标词 "我 1" 替换成一个特殊字符 "MASK1"。和 BERT 不同,"MASK" 不会纳入表征的地址向量 k 以及内容向量 v 的计算,"MASK" 自始至终只充当了查询向量 q 的角色,因此所有词的表征中都不会拿到 "MASK" 的信息。这也杜绝了 "MASK" 的引入带来的预训练-微调差异 (Pretrain-Finetune Discrepancy) -- 这个改动也可以直接应用到 BERT 上面。
在下图中记 "MASK" 对应的词向量为 G,X2 - X4 为各自的词向量,G1, H1 - H4 为各自的表征。图中省略了位置编码 p。
上面只是讨论最简单的情况 -- 即一句话只产生一个样本。但我们还希望保证训练效率 -- 我们想和自回归语言模型一样,只进行一次整句的表征计算便可以获得所有样本的语境表征。这时所有词的表征就必须同时计算,此时便有标签泄露带来的矛盾:对于某个需要预测的目标词,我们既需要得到包含它信息以及位置的表征 h (用来进一步计算其他词的表征),又需要得到不包含它信息,只包含它位置的表征 g (用来做语境的表征)。
一个很自然的想法就是同时计算两套表征,这便是 XLNet 提出的双通道自注意力 (Two Stream Self-Attention),同时计算内容表征通道 (Content Stream) h 和语境表征通道 (Query Stream) g。注意这里采用的是意译而不是直译,请读者谅解。
假设我们要计算第 1 个词在第 l 层的语境表征 g{1}^{l} 和内容表征 h{1}^{l},我们只关注注意力算子查询向量 Q、地址向量 K 以及内容向量 V 的来源:
计算 g{1}^l 时用到了 h{j!=1}^{l-1},表示第 l-1 层除了第 1 个词外所有词的表征,这是为了保证标签不泄露;计算 h{1}^{l} 时用到了 h{:}^{l-1},表示第 l-1 层所有词的表征,这和标准的 Transformer 计算表征的过程一致。
但上述做法在堆叠多层自注意算子时仍然会带来标签泄露。
虽然计算 g{1}^{l} 时我们已经采取措施防止 h{1}^{l-1} 的信息泄露到 g{1}^{l} 中,但是考虑两层自注意力算子的计算:
我们看到第 l-2 层第 1 个词的表征 h{1}^{l-2} 会通过第 l-1 层的所有表征 h{j}^{l-1} 泄露给 g{1}^{l}。
和将 Transformer 应用到自回归语言模型的情况类似,我们还需要对每层的注意力使用注意力掩码 (Attention Mask),根据选定的分解排列 z,将不合理的注意力权重置零。我们记 z{t} 为分解排列中的第 t 个词,那我们在词 z{t} 的表征时,g{t}^{l} 和 h{t}^{l} 分别只能看到排列中前 t-1 个词 z{1:t-1} 和前 t 个词 z{1:t},即
在如此做完注意力掩码后,所有 g{z{t}}^l 便可以直接用来预测词 z{t},而不会有标签泄露的问题。
这里我们也可以看到,在具体实现效率的限制下,想要获得多样的语境并防止标签泄露,我们只能依据乱序语言模型的定义去使用注意力掩码。这也体现了 XLNet 设计的精巧性。
我们来看另一个例子:
假设输入的句子是”I like New York”,并且一种排列为z=[1, 3, 4, 2],假设我们需要预测z3=4,那么根据公式:
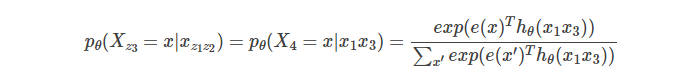
注意,我们通常用大写的X表示随机变量,比如X4,而小写的x表示某一个具体取值,比如x,我们假设x是”York”,则pθ(X4=x)表示第4个词是York的概率。用自然语言描述:上面的概率是第一个词是I,第3个词是New的条件下第4个词是York的概率。
另外我们再假设一种排列为z’=[1,3,2,4],我们需要预测z3=2,那么:
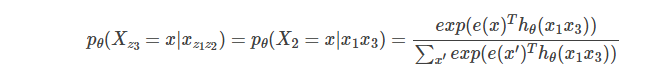
则上面是表示是第一个词是I,第3个词是New的条件下第2个词是York的概率。我们仔细对比一下公式会发现这两个概率是相等的。但是根据经验,显然这两个概率是不同的,而且上面的那个概率大一些,因为York跟在New之后是一个城市,而”York New”是什么呢?
上面的问题的关键是模型并不知道要预测的那个词在原始序列中的位置。了解Transformer的读者可能会问:输入的位置编码在哪里呢?位置编码的信息不能起作用吗?注意:位置编码是和输入的Embedding加到一起作为输入的,因此pθ(X4=x|x1x3)里的x1和x3是带了位置信息的,模型(可能)知道(根据输入的向量猜测)I是第一个词,而New是第三个词,但是第四个词的向量显然这个是还不知道(知道了还要就不用预测了),因此就不可能知道它要预测的词到底是哪个位置的词,因此我们必须”显式”的告诉模型我要预测哪个位置的词。
为了后面的描述,我们再把上面的两个公式写出更加一般的形式。给定排列z,我们需要计算![]() ,如果我们使用普通的Transformer,那么计算公式为:
,如果我们使用普通的Transformer,那么计算公式为:
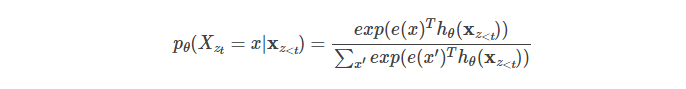
根据前面的讨论,我们知道问题的关键是模型并不知道要预测的到底是哪个位置的词,为了解决这个问题,我们把预测的位置ztzt放到模型里:
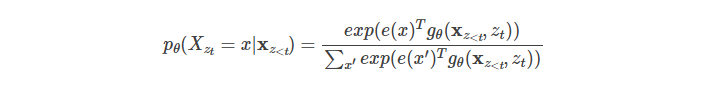
上式中![]() 表示这是一个新的模型g,并且它的参数除了之前的词
表示这是一个新的模型g,并且它的参数除了之前的词![]() ,还有要预测的词的位置
,还有要预测的词的位置![]()
2.3.1Two-Stream Self-Attention
接下来的问题是用什么模型来表示![]() 。当然有很多种可选的函数(模型),我们这里通过位置
。当然有很多种可选的函数(模型),我们这里通过位置![]() 来从context
来从context ![]() 里通过Attention机制提取需要的信息来预测这个位置的词。那么它需要满足如下两点要求:
里通过Attention机制提取需要的信息来预测这个位置的词。那么它需要满足如下两点要求:
-
为了预测
 只能使用位置信息
只能使用位置信息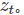 而不能使用
而不能使用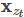 。这是显然的:你预测一个词当然不能知道要预测的是什么词。
。这是显然的:你预测一个词当然不能知道要预测的是什么词。 -
为了预测
之后的词,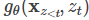 必须编码了的信息(语义)。
必须编码了的信息(语义)。
但是上面两点要求对于普通的Transformer来说是矛盾的无法满足的。因为上面是理解为什么要搞出两个Stream的关键,所以我这里再啰嗦一点举一个例子。
假设输入的句子还是”I like New York”,并且一种排列为z=[1, 3, 4, 2],假设t=2,我们现在是在计算![]() ,也就是给定第一个位置的词为I预测第三个位置为New的概率,显然我们不能使用New本身的而只能根据第一个位置的I来预测。假设我们非常幸运的找到了一很好的函数g,它可以能够比较好的预测这个概率
,也就是给定第一个位置的词为I预测第三个位置为New的概率,显然我们不能使用New本身的而只能根据第一个位置的I来预测。假设我们非常幸运的找到了一很好的函数g,它可以能够比较好的预测这个概率![]() 。现在我们又需要计算t=3,也就是根据
。现在我们又需要计算t=3,也就是根据![]() 和
和![]() 来预测York,显然知道第三个位置是New对于预测第四个位置是York会非常有帮助,但是
来预测York,显然知道第三个位置是New对于预测第四个位置是York会非常有帮助,但是![]() 并没有New这个词的信息。读者可能会问:你不是说g可以比较好的根据第一个词I预测第三个词New的概率吗?这里有两点:I后面出现New的概率并不高;在预测York时我们是知道第三个位置是New的,只不过模型的限制我们没有重复利用这信息。
并没有New这个词的信息。读者可能会问:你不是说g可以比较好的根据第一个词I预测第三个词New的概率吗?这里有两点:I后面出现New的概率并不高;在预测York时我们是知道第三个位置是New的,只不过模型的限制我们没有重复利用这信息。
为了解决这个问题,论文引入了两个Stream,也就是两个隐状态:

下面我们介绍一下计算过程。我们首先把查询隐状态![]() 初始化为一个变量w,把内容隐状态
初始化为一个变量w,把内容隐状态![]() 初始化为词的Embedding
初始化为词的Embedding ![]() 。这里的上标0表示第0层(不存在的层,用于计算第一层)。因为内容隐状态可以编码当前词,因此初始化为词的Embedding是比较合适的。
。这里的上标0表示第0层(不存在的层,用于计算第一层)。因为内容隐状态可以编码当前词,因此初始化为词的Embedding是比较合适的。
接着从m=1一直到第M层,我们逐层计算:

下面我们通过下图来直观的了解计算过程。
图:Two Stream排列模型的计算过程

2.3.2部分预测

2.4 融入Transformer-X的理念
由于我们的目标函数符合AR框架,我们纳入了最先进的AR语言模型Transformer-XL[9]进入我们的预培训框架,并以它命名我们的方法。我们集成了转换xl中的两个重要技术,即相对位置编码方案和分段递归机制。我们应用相对位置编码的基础上如前所述的原始序列,这很简单。现在我们讨论如何积分将递归机制引入到提出的置换设置中,使模型能够重用隐藏前一节的状态。
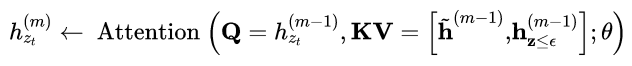
(表示沿序列维级联。注意位置编码只取决于原始序列中的实际位置。因此,以上注意事项更新如下独立于z h˜˜一旦表示(m)得到了。这允许缓存和重用不知道前一段的因式分解顺序的内存。在预期中,模型学习在最后一段的所有因数分解顺序上使用内存。查询流可以用同样的方法计算。最后,图2 (c)给出了所提议的置换的概述关注两流的语言建模(参见附录A.4获得更详细的说明)。
2.4.1Transformer-XL思想简介

为了在内存的限制下让 Transformer 学到更长的依赖,Transformer-XL 借鉴了 TBPTT(Truncated Back-Propagation Through Time) 的思路,将上一个片段 s{t-1} 计算出来的表征缓存在内存里,加入到当前片段 s{t} 的表征计算中。
如上图所示,由于计算第 l 层的表征时,使用的第 l-1 层的表征同时来自于片段 s{t} 和 s{t-1},所以每增加一层,模型建模的依赖关系长度就能增加 N。在上图中,Transformer-XL 建模的最长依赖关系为 3*2=6。
但这又会引入新的问题。Transformer 的位置编码 (Position eEmbedding) 是绝对位置编码 (Absolute Position Embedding),即每个片段内,各个位置都有其独立的一个位置编码向量。所以片段 s{t} 第一个词和片段 s{t-1} 第一个词共享同样的位置编码 -- 这会带来歧义。
Transformer-XL 引入了更加优雅的相对位置编码 (Relative Position Embedding)。
因为位置编码只在自注意力算子中起作用,我们将 Transformer 的自注意力权重的计算拆解成:
我们可以将其中的绝对位置编码 p{j} 的计算替换成相对位置编码 r{i-j},把 p{i} 替换成一个固定的向量 (认为位置 i 是相对位置的原点)。这样便得到相对位置编码下的注意力权重:
Transformer-XL 的实际实现方式与上式有所不同,但思想是类似的。
相对位置编码解决了不同片段间位置编码的歧义性。通过这种拆解,我们可以进一步将相对位置编码从词的表征中抽离,只在计算注意力权重的时候加入。这可以解决 Transformer 随着层数加深,输入的位置编码信息被过多的计算抹去的问题。Transformer-XL 在 XLNet 中的应用使得 XLNet 可以建模更长的依赖关系。
图:普通的Transformer语言模型的训练和预测
上图做是普通的Transformer语言模型的训练过程。假设Segment的长度为4,如图中我标示的:根据红色的路径,虽然x8的最上层是受x1影响的,但是由于固定的segment,x_8无法利用x1的信息。而预测的时候的上下文也是固定的4,比如预测x6时我们需要根据[x2,x3,x4,x5]来计算,接着把预测的结果作为下一个时刻的输入。接着预测x7的时候需要根据[x3,x4,x5,x6]完全进行重新的计算。之前的计算结果一点也用不上。
而Transformer-XL如下图所示:
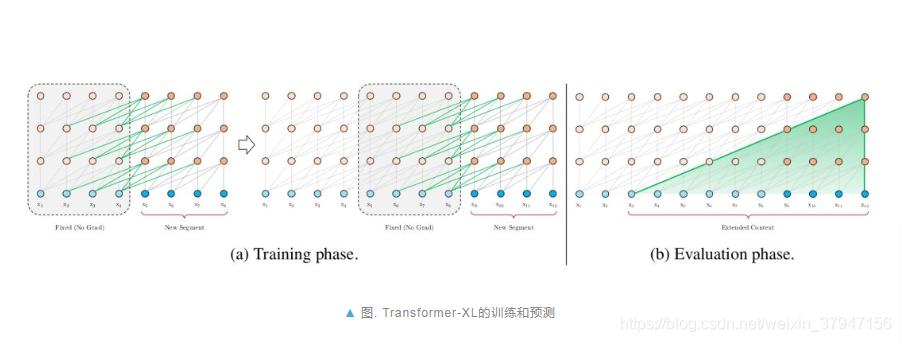
图:Transformer-XL的训练和预测

2.4.2 Segment基本的状态重用

2.4.3 Transformer-XL的相对位置编码
这里是相对位置编码,注意这里的”相对”位置指的是两个位置的差,而不是Transformer里的相对位置编码。
BERT是使用”绝对”位置编码,它把每一个位置都编码成一个向量。而在Transformer里,每个位置还是编码成一个向量,不过这个向量是固定的,而且是正弦(余弦)的函数形式,这样上层可以通过它来学习两个词的相对位置的关系,具体读者可以参考Transformer代码阅读。
而这里的”相对”位置编码是Transformer-XL里提出的一种更加一般的位置编码方式(作者在XLNet原理里的说法是不正确的,当时只是阅读了论文,没有详细看代码)。
而Transformer-XL(包括follow它的XLNet)为什么又要使用一种新的”相对”位置编码呢?这是由于Transformer-XL引入了之前的context(cache)带来的问题。
在标准的Transformer里,如果使用绝对位置编码,假设最大的序列长度为![]() ,则只需要一个位置编码矩阵
,则只需要一个位置编码矩阵![]() ,其中
,其中![]() 表示第i个位置的Embedding。而Transformer的第一层的输入是Word Embedding加上Position Embedding,从而把位置信息输入给了Transformer,这样它的Attention Head能利用这里面包含的位置信息。那Transformer-XL如果直接使用这种编码方式行不行呢?我们来试一下:
表示第i个位置的Embedding。而Transformer的第一层的输入是Word Embedding加上Position Embedding,从而把位置信息输入给了Transformer,这样它的Attention Head能利用这里面包含的位置信息。那Transformer-XL如果直接使用这种编码方式行不行呢?我们来试一下:
和前面一样,假设两个相邻的segment为![]() 和
和 ![]() ,假设segment
,假设segment ![]() 的第n层的隐状态序列为
的第n层的隐状态序列为![]() ,那么计算公式如下:
,那么计算公式如下:
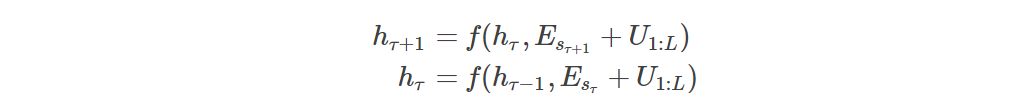
上式中Esτ是segment的每一个词的Embedding的序列。我们发现Esτ和Esτ+1都是加了U1:L,因此假设模型发现了输入有这个向量(包含),那么它也无法通过这个向量判断到底是当前segment的第i个位置还是前一个segment的第i个位置。
举个例子:比如一种情况是”a b c | d e f”(它表示context是”a b c”,当前输入是”d e f”);第二种情况是”d b c | a e f”。那么在第二个时刻,这两种情况计算e到a的attention时都是用e的Embedding(Word Embedding+Position Embedding)去乘以a的Embedding(WordEmbedding+Position Embedding)【当然实际还要把它们经过Q和K变换矩阵,但是这不影响结论】,因此计算结果是相同的,但是实际上一个a是在它的前面,而另一个a是在很远的context里。
因此我们发现问题的关键是Transformer使用的是一种”绝对”位置的编码(之前的那种使用正弦函数依然是绝对位置编码,但是它能够让上层学习到两个位置的相对信息,所以当时也叫作相对位置编码。但是对于一个位置,它还是一个固定的编码,请一定要搞清楚)。
为了解决这个问题,Transformer-XL引入了”真正”的相对位置编码方法。它不是把位置信息提前编码在输入的Embedding里,而是在计算attention的时候根据当前的位置和要attend to的位置的相对距离来”实时”告诉attention head。比如当前的query是![]() 要attend to的key是
要attend to的key是![]() ,那么只需要知道i和j的位置差,然后就可以使用这个位置差的位置Embedding。
,那么只需要知道i和j的位置差,然后就可以使用这个位置差的位置Embedding。
我们回到前面的例子,context大小是96,而输入的序列长度是128。因此query的下标i的取值范围是96-223,而key的下标j的取值范围是0-223,所以它们的差的取值范围是(96-223)-(223-0),所以位置差总共有352种可能的取值,所以上面返回的pos_emb的shape是(352, 8, 1024)。
下面是详细的相对位置编码的原理和代码,不感兴趣的读者可以跳过,但是至少需要知道前面的基本概念以及pos_emb的shape的含义。
相对位置编码的详细计算过程:
在标准的Transformer里,同一个segment的qi和kj的attention score可以这样分解:
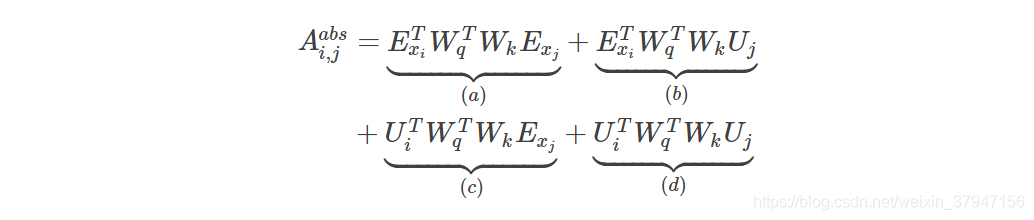
参考上面的公式,并且因为希望只考虑相对的位置,所以我们(Transformer-XL)提出如下的相对位置Attention计算公式:
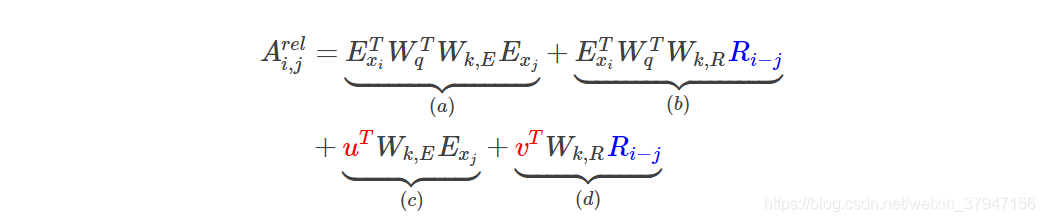



2.5多段建模
2.5.1建模多个segment
许多下游的任务会有多余一个输入序列,比如问答的输入是问题和包含答案的段落。下面我们讨论怎么在自回归框架下怎么预训练两个segment。和BERT一样,我们选择两个句子,它们有50%的概率是连续的句子(前后语义相关),有50%的概率是不连续(无关)的句子。我们把这两个句子拼接后当成一个句子来学习排列语言模型。输入和BERT是类似的:[A, SEP, B, SEP, CLS],这里SEP和CLS是特殊的两个Token,而A和B代表两个Segment。而BERT稍微不同,这里把CLS放到了最后。原因是因为对于BERT来说,Self-Attention唯一能够感知位置是因为我们把位置信息编码到输入向量了,Self-Attention的计算本身不考虑位置信息。而前面我们讨论过,为了减少计算量,这里的排列语言模型通常只预测最后1/K个Token。我们希望CLS编码所有两个Segment的语义,因此希望它是被预测的对象,因此放到最后肯定是会被预测的。
但是和BERT不同,我们并没有增加一个预测下一个句子的Task,原因是通过实验分析这个Task加进去后并不是总有帮助。【注:其实很多做法都是某些作者的经验,后面很多作者一看某个模型好,那么所有的Follow,其实也不见得就一定好。有的时候可能只是对某个数据集有效果,或者效果好是其它因素带来的,一篇文章修改了5个因素,其实可能只是某一两个因素是真正带来提高的地方,其它3个因素可能并不有用甚至还是有少量副作用。】
2.5.2相对Segment编码

2.6讨论与分析
2.6.1 与BERT比较
XLNet和BERT都是预测一个句子的部分词,但是背后的原因是不同的。BERT使用的是Mask语言模型,因此只能预测部分词(总不能把所有词都Mask了然后预测?)。而XLNet预测部分词是出于性能考虑,而BERT是随机的选择一些词来预测。
除此之外,它们最大的区别其实就是BERT是约等号,也就是条件独立的假设——那些被MASK的词在给定非MASK的词的条件下是独立的。但是我们前面分析过,这个假设并不(总是)成立。下面我们通过一个例子来说明(其实前面已经说过了,理解的读者跳过本节即可)。
假设输入是[New, York, is, a, city],并且假设恰巧XLNet和BERT都选择使用[is, a, city]来预测New和York。同时我们假设XLNet的排列顺序为[is, a, city, New, York]。那么它们优化的目标函数分别为:
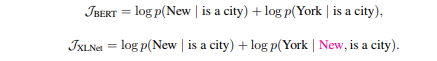
从上面可以发现,XLNet可以在预测York的使用利用New的信息,因此它能学到”New York”经常出现在一起而且它们出现在一起的语义和单独出现是完全不同的。
2.6.2. XLNet 的模型改进增益
文章最后的消融分析很好地证明了乱序语言模型和 Transformer-XL 主干网络带来的提升。这部分实验采用和 BERT 一致的训练数据。以 BERT 为基础,将 BERT 的主干网络从 Transformer 换成 Transformer-XL 后,在需要建模较长上下文的阅读理解任务 RACE 和 SQuAD2.0 均有比较明显地提升 (对比 1&2 行)。而在此基础上加上乱序语言模型后,在所有任务上都有不同程度的提升 (对比 2&3 行)。
2.6.3. 如何评价 XLNet
自词向量到如今以 XLNet 为代表的预训练语言模型,他们的主要区别在于对语境的不同粒度的建模:
XLNet 的成功来自于三点:
-
分布式语义假设的有效性,即我们确实可以从语料的统计规律中习得常识及语言的结构。
-
对语境更加精细的建模:从"单向"语境到"双向"语境,从"短程"依赖到"长程"依赖,XLNet 是目前对语境建模最精细的模型。
-
在模型容量足够大时,数据量的对数和性能提升在一定范围内接近正比 [3] [4]:XLNet 使用的预训练数据量可能是公开模型里面最大的。
可以预见的是资源丰富的大厂可以闭着眼睛继续顺着第三点往前走,或许还能造出些大新闻出来,这也是深度学习给的承诺。这些大新闻的存在也渐渐堵住调参式的工作的未来,迫使研究者去思考更加底层,更加深刻的问题。
对语境的更精细建模自然是继续发展的道路,以语言模型为代表的预训练任务和下游任务之间的关系也亟待探讨。
退后一步讲,分布式语义假设的局限性在哪里?根据符号关联假设 (Symbol Interdependency Hypothesis)[5],虽然语境的统计信息可以构建出符号之间的关系,从而确定其相对语义。但我们仍需要确定语言符号与现实世界的关系 (Language Grounding),让我们的 AI 系统知道,「红色」对应的是红色,「天空」对应的是天空,「国家」对应的是国家。这种对应信息是通过构建知识库,还是通过和视觉、语音系统的联合建模获得?解决这一问题可能是下一大新闻的来源,也能将我们往 AI 推进一大步。
基于分布式语义假设的预训练同时受制于报道偏差 (Reporting Bias)[6]:不存在语料里的表达可能是真知识,而存在语料里面的表达也可能是假知识,更不用提普遍存在的模型偏见 (Bias) 了。我们不能因为一百个人说了「世上存在独角兽」就认为其为真,也不能因为只有一个人说了「地球绕着太阳转」便把它当做无益的噪声丢弃掉。
为了达到足够大的模型容量,我们真的需要这么大的计算量吗?已经有工作证明训练充分的 Transformer 里面存在很多重复冗余的模块 [6]。除了把网络加深加宽外,我们还有什么办法去增大模型容量的同时,保持一定的计算量?
参考文献
[1] Firth, J. R. (1957). Papers in linguistics 1934–1951. London: Oxford University Press.
[2] Levy O, Goldberg Y. Neural word embedding as implicit matrix factorization[C]//Advances in neural information processing systems. 2014: 2177-2185.
[3] Mahajan D, Girshick R, Ramanathan V, et al. Exploring the limits of weakly supervised pretraining[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 181-196.
[4] Hestness J, Narang S, Ardalani N, et al. Deep learning scaling is predictable, empirically[J]. arXiv preprint arXiv:1712.00409, 2017.
[5] Louwerse M M. Knowing the meaning of a word by the linguistic and perceptual company it keeps[J]. Topics in cognitive science, 2018, 10(3): 573-589.
[6] Gordon J, Van Durme B. Reporting bias and knowledge acquisition[C]//Proceedings of the 2013 workshop on Automated knowledge base construction. ACM, 2013: 25-30.
[7] Michel P, Levy O, Neubig G. Are Sixteen Heads Really Better than One?[J]. arXiv preprint arXiv:1905.10650, 2019.
