【实验】MySQL多少数据需要建立索引
数据准备
采用Python随机生成若干条数据,以备测试使用,代码如下
# db.py
import pymysql
# 默认数据返回的是二维列表:
# (
# (每一行)
# (每一行)
# )
# 加上 cursor=pymysql.cursors.DictCursor后的数据返回格式:
# [{'psw': 'e10adc3949ba59abbe56e057f20f883e'}]
class db:
host = ""
port = 3306
user = "root"
psw = ""
db_name = "testdb"
connect = None
cursor = None
def __init__(self):
self.connect = pymysql.connect(host=self.host,port=self.port,user=self.user,passwd=self.psw,db=self.db_name)
self.cursor = self.connect.cursor(cursor=pymysql.cursors.DictCursor)
pass
def query(self,sql):
connect = pymysql.connect(host=self.host,port=self.port,user=self.user,passwd=self.psw,db=self.db_name)
cursor = connect.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute(sql)
data = cursor.fetchall()
connect.close()
return data
def operate(self,sql):
# connect = pymysql.connect(host=self.host,port=self.port,user=self.user,passwd=self.psw,db=self.db_name)
# cursor = connect.cursor(cursor=pymysql.cursors.DictCursor)
try:
self.cursor.execute(sql)
self.connect.commit()
self.count = self.cursor.rowcount
return count
except Exception as e:
print(e)
print(sql)
return False
import db as db
import random
my_db = db.db()
def get_vcode():
v_code = chr(random.randint(65,90))
v_code = v_code + chr(random.randint(97,122))
v_code = v_code + chr(random.randint(65,90))
v_code = v_code + chr(random.randint(48,57))
v_code = v_code + chr(random.randint(65,90))
v_code = v_code + chr(random.randint(48,57))
return v_code
if __name__ == '__main__':
for i in range(1,1000000):
sql = "INSERT INTO `testdb`.`test_data_100w`(`data_1`, `data_2`, `data_3`) VALUES (%d, '%s', '%s')" % (i+1,get_vcode(),get_vcode())
my_db.operate(sql)
print("当前编号:"+str(i))
数据格式

开始测试
一万条数据
索引前

索引后


性能提升0.001秒,可忽略不计~
十万条数据
索引前

索引后

速度提升:0.014秒,但是提升了8倍!
一百万条数据
索引前

索引后

查询速度提升 0.14秒 ,71倍
3000W条数据

索引前

索引后
建立索引所用时长:1673.908s 约27分钟!
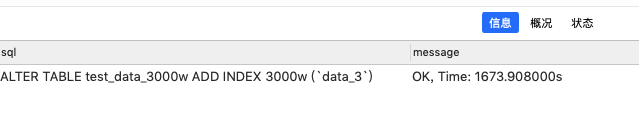

速度提升:约4.2秒,1411倍
扫描二维码关注公众号,回复:
9612830 查看本文章

结论
因为MySQL本身已经非常优秀了,
在几万条数据的情况之下,索引的优势并不明显。
数据达到几十万条以后,索引的效果显著,能明显提升查询速度,数据量越大,索引越发重要。当数据量有了千万级别时,有无索引可导致性能相差千倍!
