从数据搜集到机器学习的各个阶段,我们都面临着一个问题,就是到底需要多少数据来完成我们的分析任务。
数据搜集阶段
由于数据的搜集是高投入的,所以在开始数据搜集之前,业务负责人会向数据分析师抛出一些问题,例如“你需要什么样的数据?”,“你需要多少数据?”
数据分析阶段
在数据分析阶段,数据分析师会拿到一批数据,这时面临的问题是,哪些数据是和分析目标相关的?数据量是否够用?如果数据量够用,用多少数据进行分析呢?如果数据量不够,采样数据增强的方法是否可以解决数据量不足的问题?
机器学习中你所需要的数据数量和很多因素有关,你要解决问题的复杂程度,学习算法的复杂程度。上述问题可以总结为数据分析需要的数据变量种类、数据粒度、数据量的需求。
1、需要的数据变量种类
可以运用领域的专业知识明确与分析目的相关的变量,即分析必须的变量有哪些,对于那些不明确是否必须的变量,如果条件允许可以搜集,也可以通过学习别人的经验进行类比。变量对于解决问题有帮助,而不是完全无关或者关联性极低的数据
2、需要的数据粒度
数据的粒度即数据的采样频率,数据的采样频率越大,数据量越大。一般来说,我们追求尽量细分的数据,因为可以通过聚合来实现从具体数据到宏观数据的还原,但反之则不可得。数据收集的第一个重点是搞清楚,在什么粒度可以解决我们的问题,而不是盲目的收集一大堆数据,或者收集过于抽象的数据。
3、需要的数据量
数据量指的是有效数据量,即样本间的重复性比较低,不会存在大量的重复样本。
统计显著
显著性可以表征采集样本与总体的偏差,样本量的大小不取决于总体的多少,而取决于(1) 研究对象的变动程度;(2) 所要求或允许的误差大小;(3) 要求推断的置信程度。满足一定显著度时,统计结果才有意义。
数据量与特征量的关系
当特征数量较多时,训练样本就会越稀疏,会产生维数灾难问题,参考链接
机器学习的维度灾难
数据量与模型选择
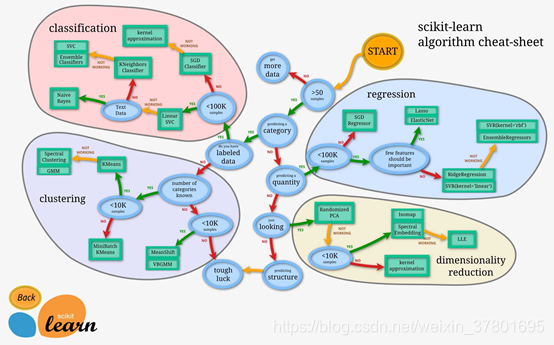
模型对数据量的需求取决于模型的参数个数,模型分类机制,分类模型要求至少每个类别都有数据,数据均衡。经验说法是训练数据量至少是模型参数的10倍。Sklearn中模型选择见下图。
4、评估数据集大小和模型表现
在实践中,需要评估不同大小数据集下模型的表现,通过绘制不同大小数据集与模型表现的关系,找到模型最适合的数据集规模。
参考链接
http://www.eeboard.com/news/jiqixuexi-3/
https://blog.csdn.net/sparkapi/article/details/79754041