Hive安装
- alt+p打开sftp,上传apache-hive-2.3.4-bin.tar.gz到hadoop02。

在hadoop02虚拟机中进入到apps目录下,看到刚刚上传的hive安装包,解压tar zxvf apache-hive-2.3.4-bin.tar.gz,进入到bin目录下。

- 在bin目录下运行hive脚本
[hadoopUser@hadoop02 bin]$ ./hive
(这是安装derby,但是我们要安装mysql,所以这一步仅作了解,不安装derby无需运行)

- 修改配置文件
返回到apache-hive-2.3.4-bin的conf目录下,创建一个 hive-site.xml文件 ,touch hive-site.xml

- 在这个新创建的hive-site.xml文件下vim编辑以下内容,保存退出。
# 如果mysql和hive在同一个服务器节点,那么请把hadoop01修改为localhost
# mysql://mysql安装所在的服务器名称:3306/
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/hivedb?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
# mysql的用户名
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hadoopUser</value>
<description>username to use against metastore database</description>
</property>
# mysql的密码
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
# 可选配置,该配置信息用来指定hive数据仓库的数据存储在HDFS上的目录(该目录必须预先创建好)
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/home/hadoopUser/apps/hive/warehouse</value>
<description>hive default warehouse,you can change</description>
</property>

5. sftp上传mysql驱动包(mysql-connector-java-5.1.40-bin.jar),放在apache-hive-2.3.4-bin目录下的lib文件夹下。

6. 配置环境变量
在 vim ~/.bashrc下添加内容
export HIVE_HOME=/home/hadoopUser/apps/apache-hive-2.3.4-bin
export PATH=$ PATH:$HIVE_HOME/bin
执行文件(重新加载文件)就能生效:source ~/.bashrc

7.验证hive安装

7. 初始化元数据库
hive 2.x以后的版本需要手动初始化元数据库。
schematool -dbType mysql -initSchema

8. 启动Hive客户端
[hadoopUser@hadoop02 bin]$ hive --service cli
或者
[hadoopUser@hadoop02 bin]$ hive
9.查看数据库
成功!

Hive的两种连接方式
- CLI
进入hive的bin目录下
输入命令hive,成功的话就会是下图所示,就可以进行hive操作。

- HiveServer2服务和beeline客户端
hiveserver2是hive的服务器,beeline就是客户端,可以理解成mysql和navicat的关系。
①修改hadoop集群,进入到/apps/hadoop-2.7.6/etc/hadoop底下,ll可以看到很多配置文件,这里我们在hdfs-site.xml和core-site.xml上加入配置信息。

②修改vim hdfs-site.xml配置文件(集群内的每个节点都要配置),表示启用webhdfs。
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
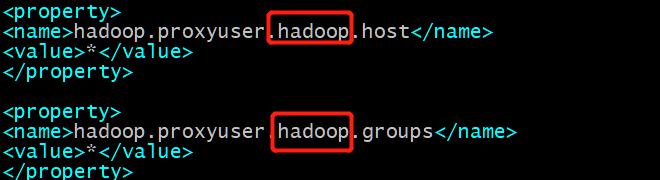
③修改vim core-site.xml配置文件(集群内的每个节点都要配置),设置hadoop代理用户。
<property>
<name>hadoop.proxyuser.XXX.host</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.XXX.groups</name>
<value>*</value>
</property>
# XXX是你的用户名,我是hadoopUser
# hadoop.proxyuser.XXX.host配置成*的意义在于:
# 表示任何节点使用hadoop集群的代理用户hadoop都能访问hdfs集群,
# hadoop.proxyuser.hadoop.groups表示代理用户的组所属。
配置完成后,重启hdfs集群才生效 (stop/start-dfs.sh和stop/start-yarn.sh)
④ 重启完成后,先启动hiveserver2服务
nohup(no hang up,不挂起)命令的一般形式:
nohup command &
如果你正在运行一个进行,你认为退出账户时该进程还不会结束,就可以使用nohup命令,。
输入命令:nohup hiveserver2 1>/home/hadoopUser/apps/hive/hiveserver.log 2>/home/hadoopUser/apps/hive/hiveserver.err &
其中,1后面跟着的是你存放hiveserver.log的路径,代表标准日志
2后面跟着的是你存放hiveserver.err的路径,代表错误日志
如果不输出路径,日志会默认生成在当前目录,默认命名为nohup.xxx
如果不想输入记录日志,可以采用以下命令,不挂起可省略nohup:
nohup hiveserver2 1>/dev/null 2>/dev/null &
或者
nohup hiveserver2 >/dev/null 2>&1 &

⑤ 然后启动beeline客户端去连接hiveserver2服务
beeline -u jdbc:hive2://hadoop02:10000 -n hadoopUser
-u:指定元数据库的连接信息,即你安装hive的虚拟机名称
-n:搭建集群的用户名和用户名
但是我这里出现错误Unauthorized connection for super-user,具体可以看下面的问题6。
如果成功连接,就可以使用beeline进行hive操作。
搭建过程存在的问题
- 初始化元数据库的问题,显示hive-site.xml文件第二行有问题,打开文件发现是configuration写错了(低级错误)。

- 继续初始化,还是存在问题,原因是我linux的mysql安装在hadoop01,这里报错因为我mysql路径在hive-site.xml中写成hadoop02了。

- 修改完毕后,还是存在问题,是因为我远程连接的mysql账号不是root,又改为正确的账号和密码,就初始化元数据库成功了。

- beeline客户端连接出现问题,原因是core-site.xml中hadoop要修改为你的用户名,我的用户名是hadoopUser(如下图)。
修改完成后要重启集群,jps一下看有没有runjar,有的话先kill掉再启动


6.重启集群后,再次运行beeline,发现另外一个错误。 hadoopUser没有赋予超级用户的权限?

打开sodoers配置文件,发现给hadoopUser配置root权限显示颜色与上面不一致,主要原因是用户名含大写,可能是这个原因导致没有授权成功。
无解了,以后创建linux用户名千万不要用大写!

所以在修改配置文件的时候,一定要细心谨慎一点,才不会出现问题。
