1、问题描述:
爬取链家深圳二手房的详细信息,并将爬取的数据存储到Excel表
2、思路分析:
发送请求--获取数据--解析数据--存储数据
1、目标网址:https://sz.lianjia.com/ershoufang/
2、利用requests.get()方法向豆瓣读书首页发送请求,获取首页的HTML源代码
#目标网址
targetUrl = "https://sz.lianjia.com/ershoufang/"
#发送请求,获取响应
response = requests.get(targetUrl).text3、利用BeautifulSoup解析出二手房的详细信息:
链接href、名字name、户型houseType、面积area、朝向direction、楼层flood、价格totalPrice、单价unitPrice
(1)首先看一下链家深圳二手房网页的结构,可以很容易发现链家的规则,每个二手房的详细信息都在<li class="clear LOGCLICKDATA">中,所以我们只需要解析出这个class中包含的详细信息即可。
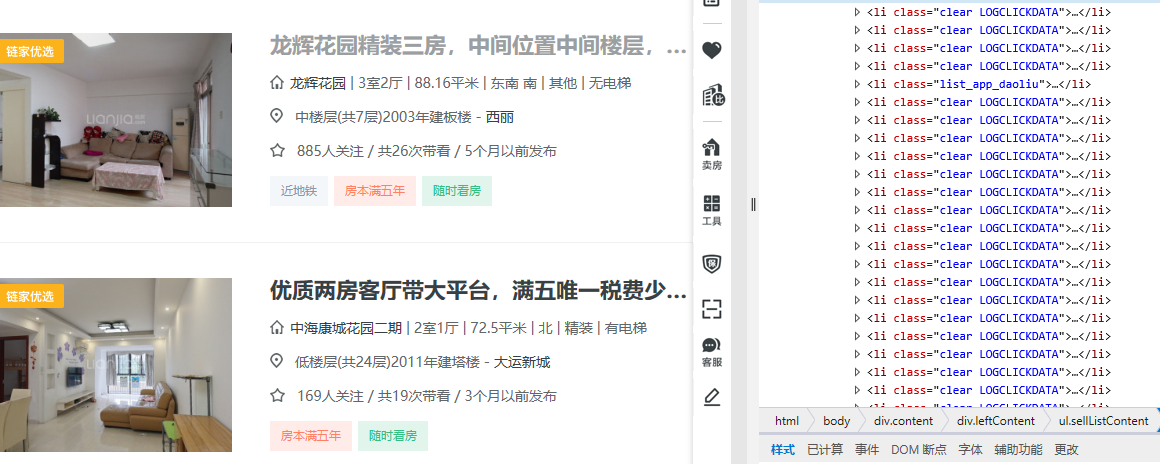

'''利用BeautifulSoup解析出二手房的详细信息:
链接href、名字name、户型houseType、面积area、朝向direction、楼层flood、价格totalPrice、单价unitPrice'''
soup = BeautifulSoup(response, "html.parser")
houseInfo = soup.find_all("div", class_ = "houseInfo")
priceInfo = soup.find_all("div", class_ = "priceInfo")
floodInfo = soup.find_all("div", class_ = "flood")
name = [house.text.split("|")[0].strip() for house in houseInfo]
houseType = [house.text.split("|")[1].strip() for house in houseInfo]
area = [house.text.split("|")[2].strip() for house in houseInfo]
direction = [house.text.split("|")[3].strip() for house in houseInfo]
flood = [flo.text.split("-")[0] for flo in floodInfo]
href = [house.find("a")["href"] for house in houseInfo]
totalPrice = [(re.findall("\d+", price.text))[0] for price in priceInfo]
unitPrice = [(re.findall("\d+", price.text))[1] for price in priceInfo]
#将爬取到的所有二手房的详细信息整合到house列表中
house = [name, href, houseType, area, direction, flood, totalPrice, unitPrice]4、将数据存储到Excel表格中
#将二手房的详细信息存储到Excel表格Lianjia_I.xlsx中
workBook = xlwt.Workbook(encoding="utf-8") #创建Excel表,并确定编码方式
sheet = workBook.add_sheet("Lianjia_I") #新建工作表Lianjia_I
headData = ["小区名称", "链接", "户型", "面积", "朝向", "楼层", "价格(万)", "单价"] #表头信息
for col in range(len(headData)):
sheet.write(0, col, headData[col])
for raw in range(1, len(name)):
for col in range(len(headData)):
sheet.write(raw, col, house[col][raw-1])
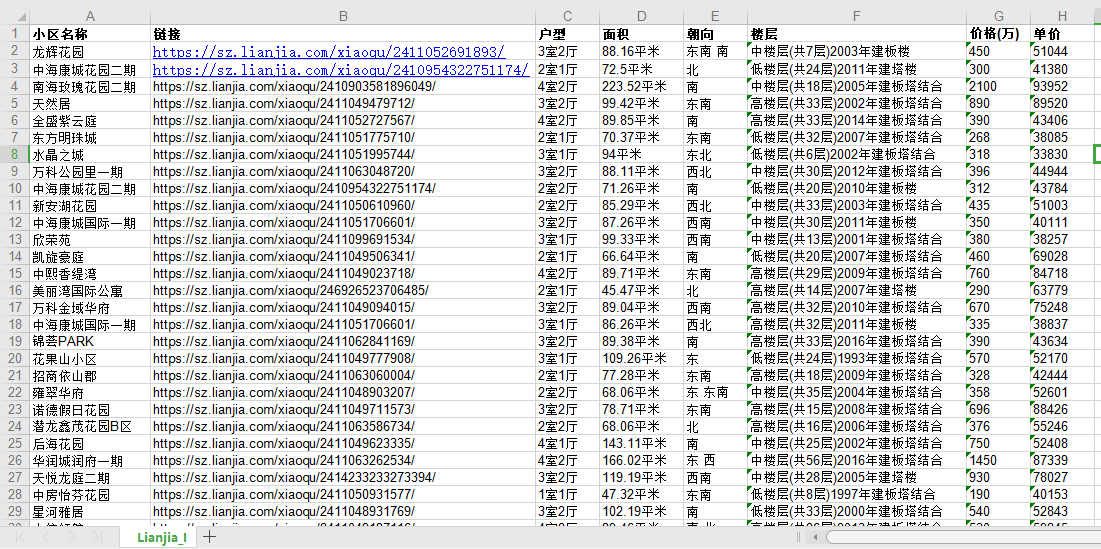
workBook.save(".\Lianjia_I.xlsx")3、效果展示
4、完整代码:
# -* coding: utf-8 *-
# author: wangshx6
# date: 2018-11-04
# description: 爬取链家深圳二手房首页的房子名称、户型、面积、价格等详细信息
import requests
import re
import xlwt
from bs4 import BeautifulSoup
# 目标网址
targetUrl = "https://sz.lianjia.com/ershoufang/"
#发送请求,获取响应
response = requests.get(targetUrl).text
'''利用BeautifulSoup解析出二手房的详细信息:
链接href、名字name、户型houseType、面积area、朝向direction、楼层flood、价格totalPrice、单价unitPrice'''
soup = BeautifulSoup(response, "html.parser")
houseInfo = soup.find_all("div", class_ = "houseInfo")
priceInfo = soup.find_all("div", class_ = "priceInfo")
floodInfo = soup.find_all("div", class_ = "flood")
name = [house.text.split("|")[0].strip() for house in houseInfo]
houseType = [house.text.split("|")[1].strip() for house in houseInfo]
area = [house.text.split("|")[2].strip() for house in houseInfo]
direction = [house.text.split("|")[3].strip() for house in houseInfo]
flood = [flo.text.split("-")[0] for flo in floodInfo]
href = [house.find("a")["href"] for house in houseInfo]
totalPrice = [(re.findall("\d+", price.text))[0] for price in priceInfo]
unitPrice = [(re.findall("\d+", price.text))[1] for price in priceInfo]
house = [name, href, houseType, area, direction, flood, totalPrice, unitPrice]
# print(href, name, houseType, area, direction, totalPrice, unitPrice)
#将数据列表存储到Excel表格Lianjia_I.xlsx中
workBook = xlwt.Workbook(encoding="utf-8")
sheet = workBook.add_sheet("Lianjia_I")
headData = ["小区名称", "链接", "户型", "面积", "朝向", "楼层", "价格(万)", "单价"]
for col in range(len(headData)):
sheet.write(0, col, headData[col])
for raw in range(1, len(name)):
for col in range(len(headData)):
sheet.write(raw, col, house[col][raw-1])
workBook.save(".\Lianjia_I.xlsx")