1-首先下载pyspider
pip install pyspider
2-在任意一个文件夹下执行命令 启动pyspider
pyspider 或者 pyspider all
3-执行命令后 创建项目
4-创建项目后 进入项目 编写代码
from pyspider.libs.base_handler import *
from fake_useragent import UserAgent
ua=UserAgent()
from pymongo import MongoClient
class Handler(BaseHandler):
crawl_config = {
'headers': {
'User-Agent': ua.random,
}
}
@every(minutes=4 * 60)
def on_start(self):
#只获取长春市南关区的最新二手房信息
self.crawl('https://cc.lianjia.com/ershoufang/nanguanqu/co32/',fetch_type='js', callback=self.index_page)
@config(age= 60)
def index_page(self, response):
maxpage = int(response.etree.xpath('//div[@class="page-box house-lst-page-box"]/a[last()-1]/text()')[0])
#print(maxpage)
#print(response.url) #https://cc.lianjia.com/ershoufang/nanguanqu/co32/
for index in range(1,maxpage+1):
baseUrl = response.url.replace('co32','pg%dco32'%index)
index+=1
#print(baseUrl)
self.crawl(baseUrl,callback=self.page)
@config(priority=4)
def page(self,response):
#print(response.url)
#获取每页的30条信息
for ele in response.etree.xpath('//ul[@class="sellListContent"]/li'):
#符合条件的信息
messages = ele.xpath('./div[1]/div[@class="followInfo"]/text()')[0]
if '刚刚发布' not in messages:
return
#print(messages)
#链接url
urls = ele.xpath('./a/@href')
for url in urls:
#print(url)
itemUrl=url
self.crawl(itemUrl,callback=self.detail)
@config(priority=2)
def detail(self,response):
print(response.url)
item={}
item['url']=response.url
item['title']=response.etree.xpath('//h1/text()')[0]
item['totalprice']=response.etree.xpath('//span[@class="total"]/text()')[0]+"万"
item['area']=response.etree.xpath('//div[@class="area"]/div[@class="mainInfo"]/text()')[0]
item['rooms']=response.etree.xpath('//div[@class="room"]/div[@class="mainInfo"]/text()')[0]
item['direction']=response.etree.xpath('//div[@class="type"]/div[@class="mainInfo"]/text()')[0]
item['averageprice']=response.etree.xpath('//div[@class="unitPrice"]/span/text()')[0]+'元/平米'
item['onsaleTime']=response.etree.xpath("//div[@class='transaction']//li[1]/span[2]/text()")[0]
print(item)
#把数据存储到数据库中
col = MongoClient()['LianJia']['ChangChun']
if col.find_one(item):
return
if item:
col.insert_one(item)
return {'item':item}
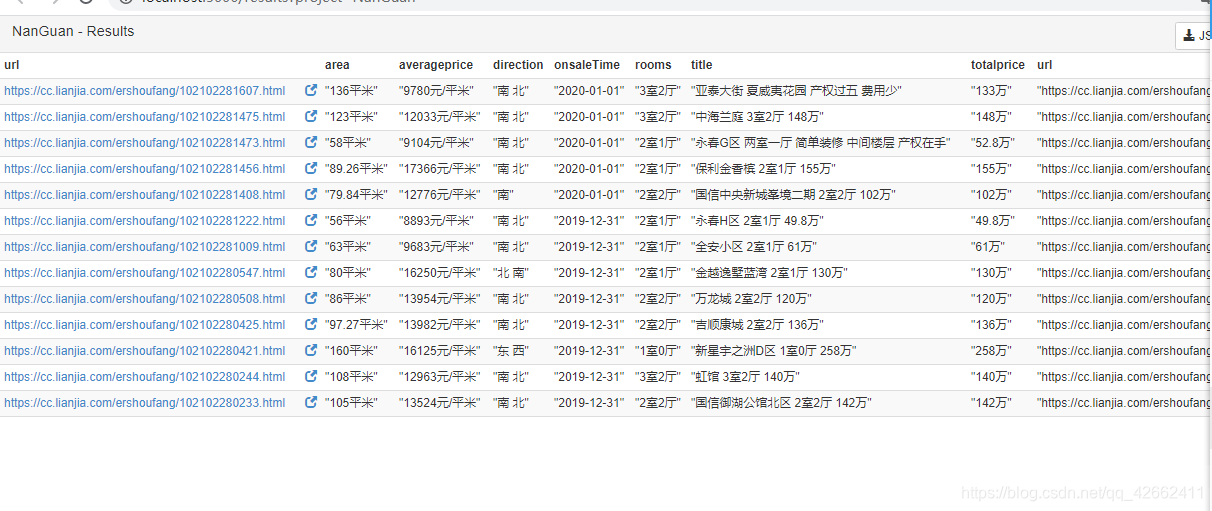
5-保存后 运行没问题
6-检查之后 发现数据也能正常存入数据库 就是在results中找不到数据 而且powershell中还出现中文乱码 这是为什么呢?
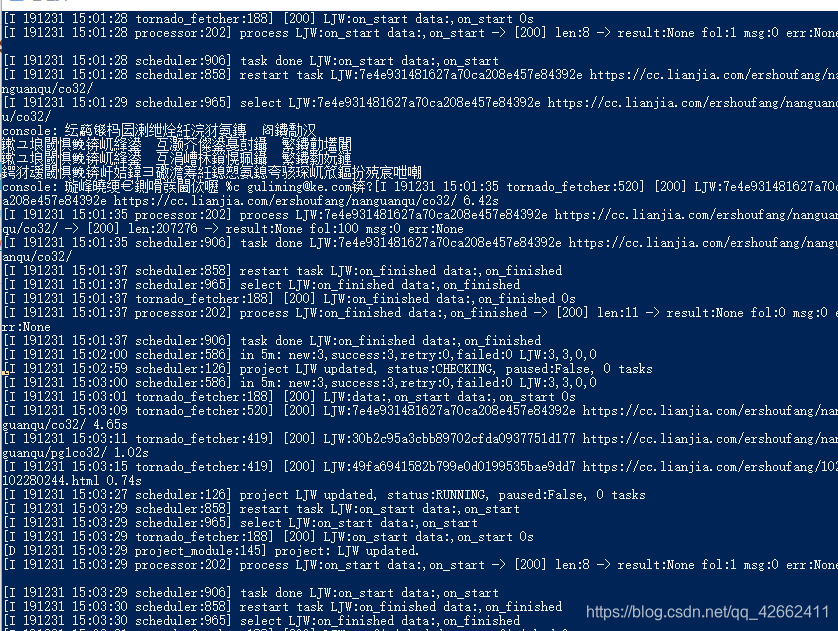

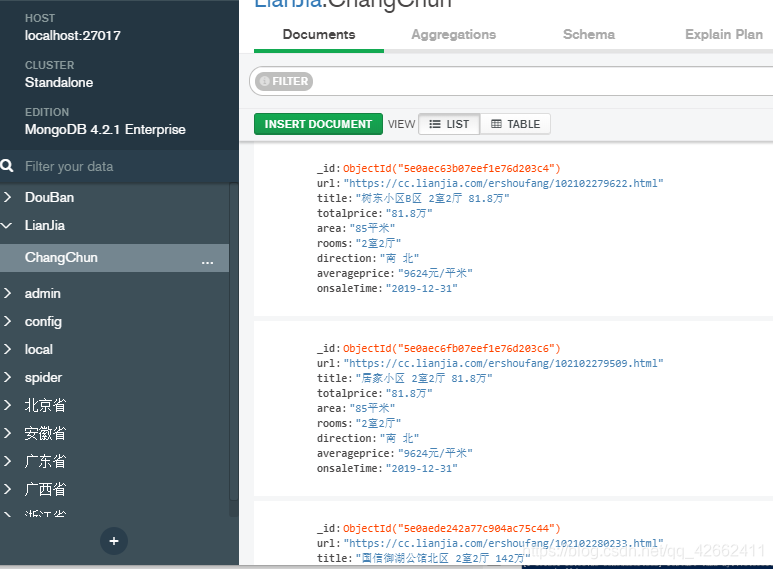
7-经过调试之后 发现是优先级的问题 @config(priority=2) 这里面priority=2数字越大 权重越高 越先执行 所以最后我改代码
from pyspider.libs.base_handler import *
from fake_useragent import UserAgent
ua=UserAgent()
from pymongo import MongoClient
class Handler(BaseHandler):
crawl_config = {
}
def __init__(self):
self.headers ={
'User-Agent': ua.random,
}
@every(minutes=4 * 60)
def on_start(self):
#只获取长春市南关区的最新二手房信息
self.crawl('https://cc.lianjia.com/ershoufang/nanguanqu/co32/',headers=self.headers,fetch_type='js',validate_cert=False, callback=self.index_page)
@config(age= 3*60)
def index_page(self, response):
maxpage = int(response.etree.xpath('//div[@class="page-box house-lst-page-box"]/a[last()-1]/text()')[0])
#print(maxpage)
#print(response.url) #https://cc.lianjia.com/ershoufang/nanguanqu/co32/
for index in range(1,maxpage+1):
baseUrl = response.url.replace('co32','pg%dco32'%index)
index+=1
#print(baseUrl)
self.crawl(baseUrl,validate_cert=False,callback=self.page)
@config(priority=2)
def page(self,response):
#print(response.url)
#获取每页的30条信息
for ele in response.etree.xpath('//ul[@class="sellListContent"]/li'):
#符合条件的信息
messages = ele.xpath('./div[1]/div[@class="followInfo"]/text()')[0]
if '刚刚发布' not in messages:
return
#print(messages)
#链接url
urls = ele.xpath('./a/@href')
for url in urls:
#print(url)
itemUrl=url
self.crawl(itemUrl,validate_cert=False,callback=self.detail)
@config(priority=2)
def detail(self,response):
print(response.url)
item={}
item['url']=response.url
item['title']=response.etree.xpath('//h1/text()')[0]
item['totalprice']=response.etree.xpath('//span[@class="total"]/text()')[0]+"万"
item['area']=response.etree.xpath('//div[@class="area"]/div[@class="mainInfo"]/text()')[0]
item['rooms']=response.etree.xpath('//div[@class="room"]/div[@class="mainInfo"]/text()')[0]
item['direction']=response.etree.xpath('//div[@class="type"]/div[@class="mainInfo"]/text()')[0]
item['averageprice']=response.etree.xpath('//div[@class="unitPrice"]/span/text()')[0]+'元/平米'
item['onsaleTime']=response.etree.xpath("//div[@class='transaction']//li[1]/span[2]/text()")[0]
return item
8-结果演示 获取最新二手房发布信息