对应的项目:PWC-Net
对应的论文:PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume, CVPR 2018 (Oral)
在这里由于原项目是使用pytorch和caffee的,所以我找的是一个tensorflow版本
项目地址
PWC-net是一个能够根据两张图像来输出对应的光流图,光流是一种矢量
概念介绍
-
对于光流
- 矢量方向代表色相
- 矢量长度代表饱和度
-
评估光流估计的质量方法——angular error 和 endpoint error
- angular error(AE) :arccos((u0,v0)*(u1,v1))
- endpoint error:(PE) sqrt((u0-u1)^2)
- (u0,v0),(u1,v1)为两个光流矢量
- AE*PE越小,质量越好
基本思想
PWC在FlowNet2的基础上添加了domain knowledge
光流估计的基本思路是像素在从frame 1切换到frame 2的过程中,尽管位置发生了改变,但是大部分亮度依旧保持。我们能够在frame 1抓取一个小的patch,在frame 2找到另一个小的patch,最大化两个patches之间的一些关系
在frame 1中滑动patch,寻找到一个peak,生成cost volume,这样的结果非常robust,但是计算代价太大。一些情况下,需要一个更大的patch来减少frame 1中的false positives数量,进一步提升复杂性
为了减少生成的cost volume,
第一步优化 ,pyramidal processing ,使用一个低分辨率图像滑动更小的patch,在较小版本上执行从frame 1到 frame 2的搜索。因此返回一个更小的运动矢量,再将这个运动矢量作为hint到下一层金字塔去执行更有针对性的搜索
这样的“多层运动估算”能够在图像域或者特征域(使用convnet生成的缩减特征图)中执行。
PWC将使用 以较低分辨率估算的运动流的上采样版本来warps frame1,因为这样可以在金字塔的下一个更高分辨率的层中搜索一个较小的运动增量
这里是2层金字塔说明的过程

相对于SpyNet,FlowNet2,PWC-Net的下面三种方法都不是针对图像的
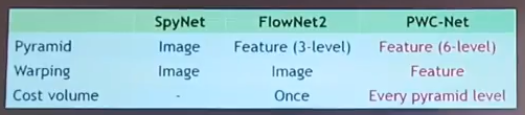
这里的Pyramid,Warping,Cost volume都是优化方法。
除此之外,数据扩充可以得到更好的性能,训练多个数据集(Sintel+KITTI+HD1K)可以提升robustness
因为算法仅仅在两个连续的frames中运行,所以这个算法与仅仅使用图像对的方法有相同的局限性。也就是说,如果一个物体移出了帧,那么预测流很可能有很大的EPE.所以,使用较大数量的frames可以提高容错性,但是有时候对于较小较快的运动物体,模型会失败
代码使用
使用的代码在pwcnet_predict_from_img_pairs.ipynb文件中
对于这段代码
# Build a list of image pairs to process
img_pairs = []
for pair in range(1, 4):
image_path1 = f'./samples/mpisintel_test_clean_ambush_1_frame_00{pair:02d}.png'
image_path2 = f'./samples/mpisintel_test_clean_ambush_1_frame_00{pair+1:02d}.png'
image1, image2 = imread(image_path1), imread(image_path2)
img_pairs.append((image1, image2))
修改其中的文件位置,比如将其改为两张图片的位置
注意,两张图片一定要相同大小,否则报错
运行即可得到最后的光流图

当然,还可以将一个视频截取为很多的图像文件,放入文件夹中,通过
files=os.listdir(srcPath)
获得这个文件夹的所有图片,然后执行循环两两配对,就可以得到整个视频的光流运动了
