网络爬虫是什么?
网络爬虫就是自动从互联网中定向或不定向地采集信息的一种程序
定向:聚焦,有固定目的,采集局部信息 如:采集电话号码、采集学员信息
不定向:没有规定目的,或者没有固定要求
网络爬虫有很多种类型,常用的有通用网络爬虫(不定向采集)、聚焦网络爬虫(定向采集)等。
网络爬虫能做什么?
比如,通用网络爬虫可以应用在搜索引擎中,聚焦网络爬虫可以从互联网中自动采集信息并代替我们筛选出相关数据出来。具体来说,网络爬虫经常可以应用在以下方面:1、搜索引擎;2、采集金融数据;3、采集商品数据;4、自动过滤广告;5、采集竞争对手的客户数据;6、采集行业相关数据,进行数据分析
总结:网络爬虫主要是进行网络信息提取和信息筛选
网络爬虫的工作原理
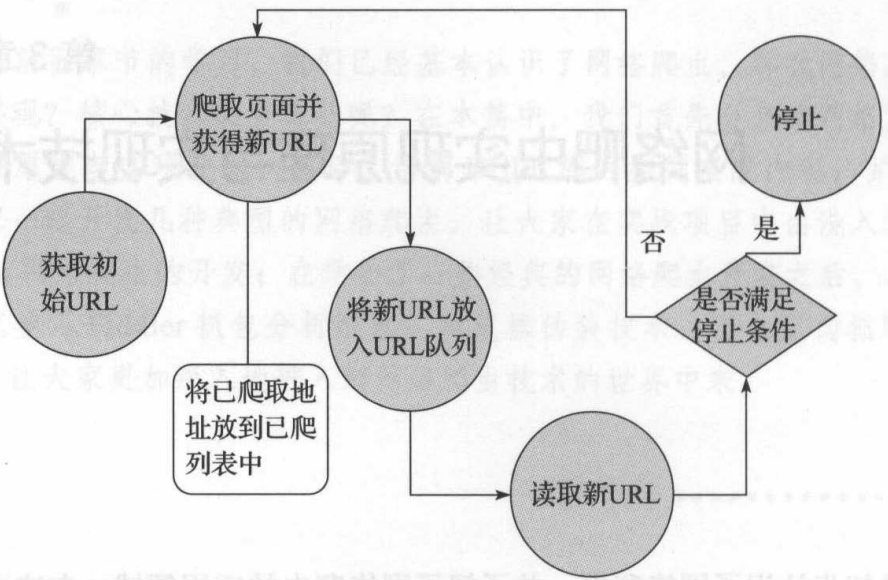
通用网络爬虫运行原理:
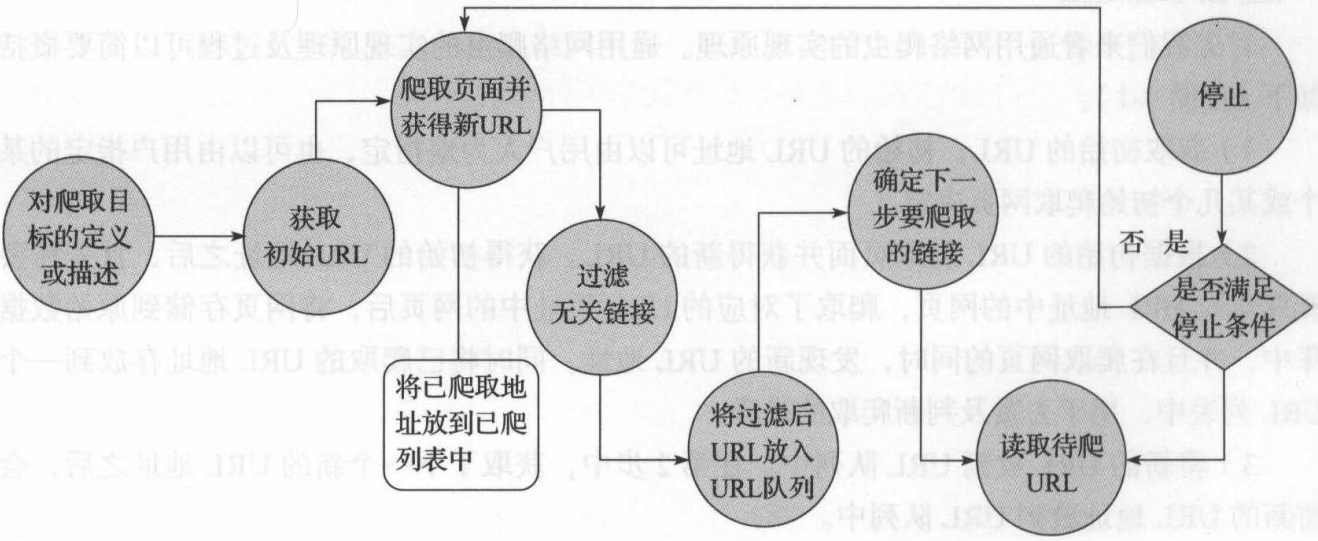
 聚焦网络爬虫运行原理:
聚焦网络爬虫运行原理:
正则表达式
如果只提取出所关注的数据,则可以通过一些表达式进行提取,正则表达式就是其中一种进行数据筛选的表达式
原子
原子是正则表达式中最基本的组成单位,每个正则表达式中至少要包含一个原子。常见的原子类型有:
普通字符作为原子;非打印字符作为原子;通用字符作为原子;原子表
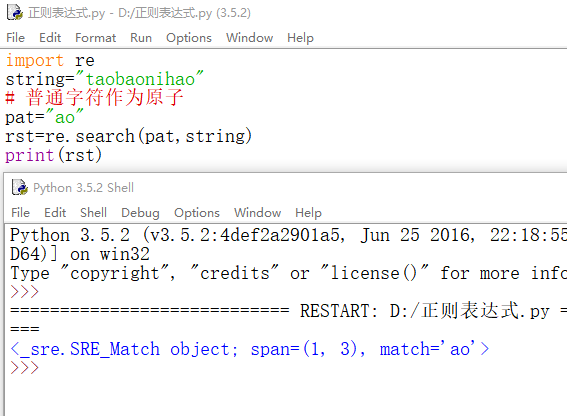
普通字符作为原子
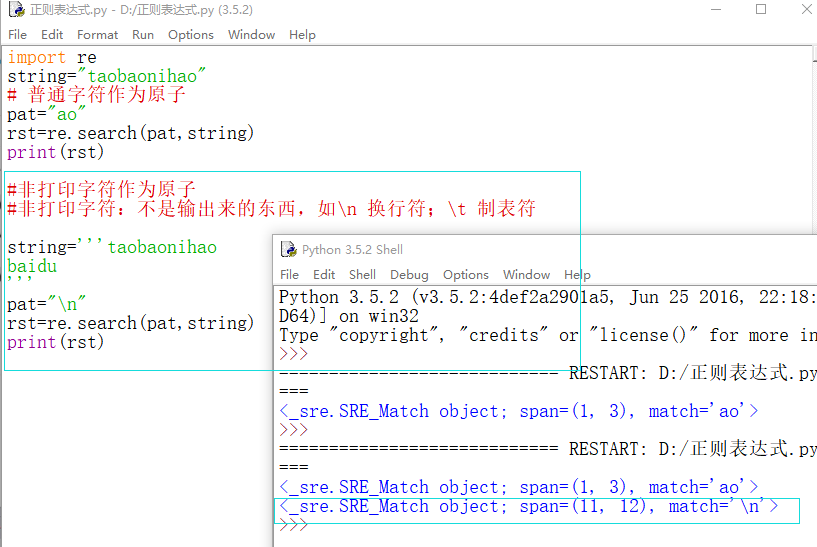
非打印字符作为原子
非打印字符:不是输出来的东西,如\n 换行符;\t 制表符
通用字符作为原子
通用字符:用一个字符代替一类东西
\w :匹配任意一个字母、数字、下划线
\W:匹配除字母、数字、下划线以外的任意一个字符
\d:匹配十进制数
\D:匹配除十进制以外的任意一个字符
\s:匹配任意一个空白字符
\S:匹配除空白字符的任意一个字符
 原子表
原子表
将几个原子组成一个表,这个表就是原子表。里面的原子都是平等的,从原子表中任意选一个原子出来
格式:[原子1原子2原子3…]
如:[abc] 在abc中选一个字符
[^abc] 除了abc以外任选一个字符,^代表非

 上图中没有匹配到
上图中没有匹配到
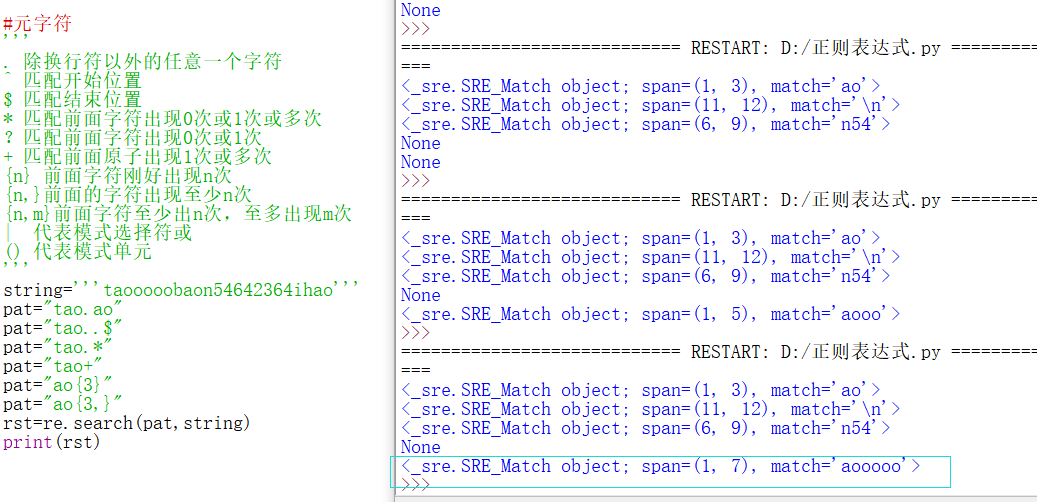
元字符
元字符:是正则表达式中具有一些特殊含义的字符,比如重复N次前面的字符等
. 除换行符以外的任意一个字符
^ 匹配开始位置
$ 匹配结束位置
* 匹配前面字符出现0次或1次或多次
?匹配前面字符出现0次或1次
+ 匹配前面原子出现1次或多次
{n} 前面字符刚好出现n次
{n,}前面的字符出现至少n次
{n,m}前面字符至少出n次,至多出现m次
| 代表模式选择符或
() 代表模式单元
 模式修正符
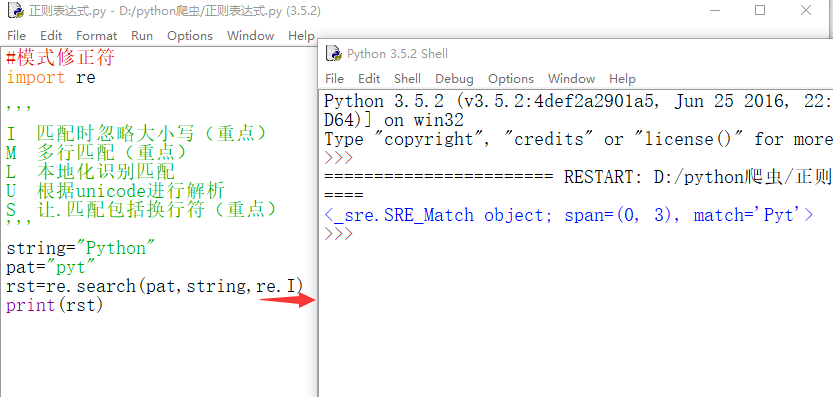
模式修正符
模式修正符:是指在不改变正则表达式的情况下,通过模式修正符改变正则表达式的含义,从而实现一些匹配结果的调整等功能
I 匹配时忽略大小写(重点)
M 多行匹配(重点)
L 本地化识别匹配
U 根据unicode进行解析
S 让.匹配包括换行符(重点)
格式:re.模式修正符
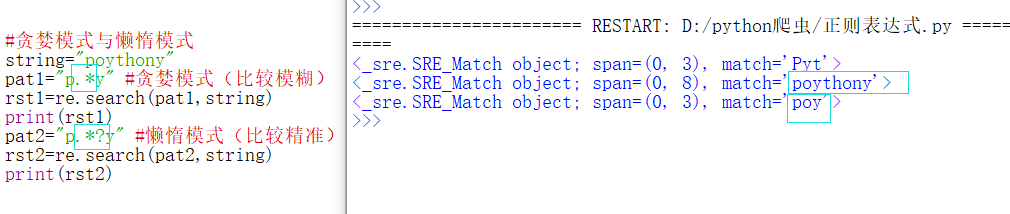
贪婪模式与懒惰模式
贪婪模式:尽可能多的匹配,可以用于模糊查询,经常用 .*
懒惰模式:尽可能少的匹配,可以用于精准查询 ,经常用 .*?
 正则表达式函数
正则表达式函数
正则表达式本身不实现任何功能,只能实现信息匹配。若实现功能,需要通过正则表达式函数。正则表达式函数有re.match()函数、re.search() 函数、全局匹配函数、re.sub()函数等
1、match:从头开始匹配
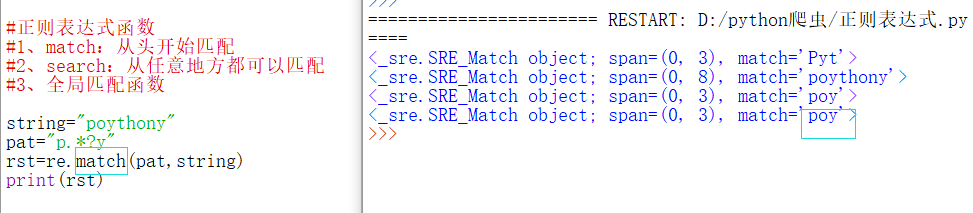 2、search:从任意地方都可以匹配
2、search:从任意地方都可以匹配
3、全局匹配函数
全局匹配格式:re.compile(正则表达式).findall(数据)
compile 是先编译一下;
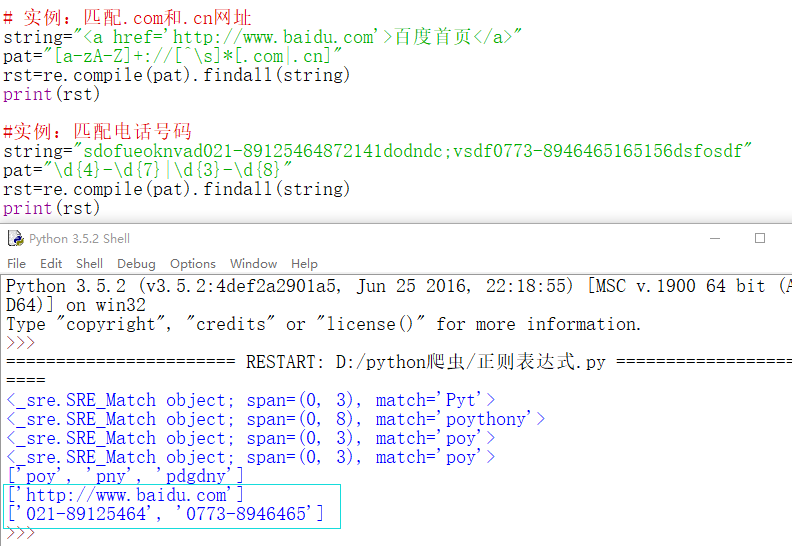
 简单的实例匹配
简单的实例匹配
简单的爬虫
直接使用urllib进行编写
简单爬虫的编写:

自动提取课程页面的微信联系方式:

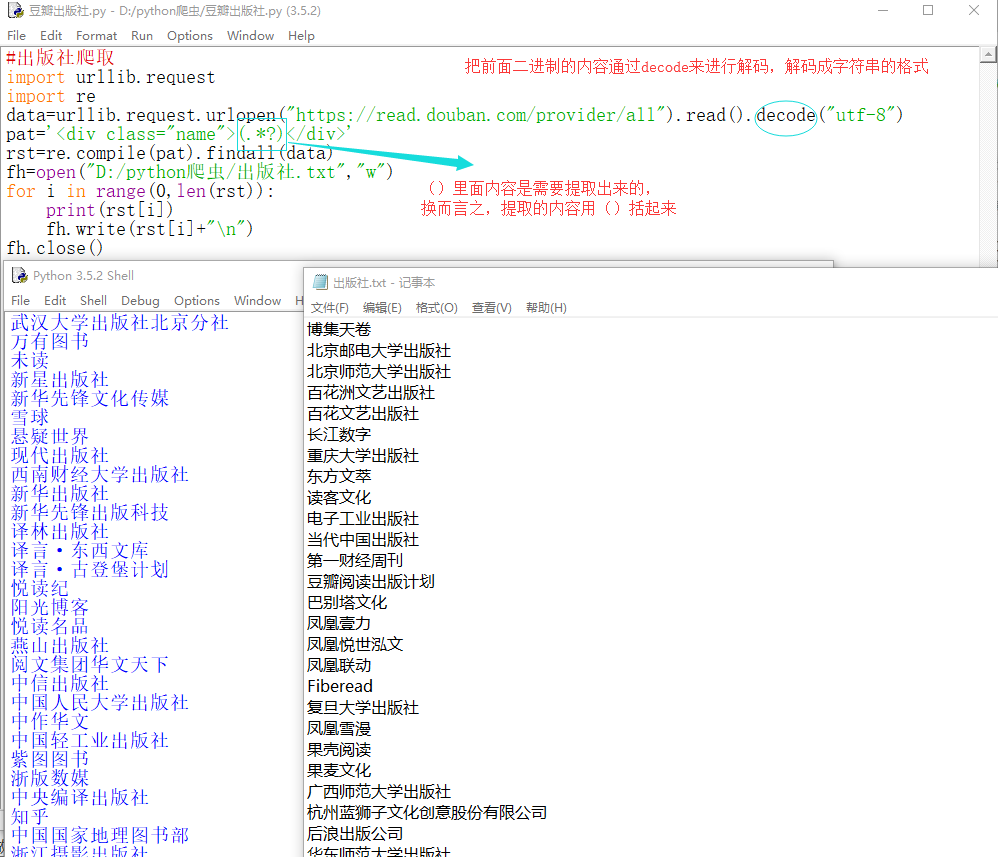
豆瓣图书中出版社信息的爬取
Urllib库实战
适合写爬虫脚本,爬虫项目适合scrapy框架做
学习Urllib可以更好的理解爬虫底层的处理流程
Urllib 适合写中小型的
scrapy适合大型的,不注重细节
urllib基础
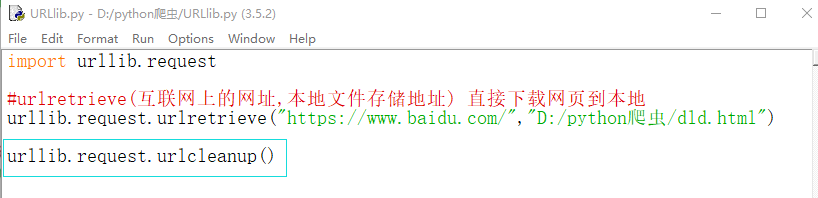
1、urlretrieve(互联网上的网址,本地文件存储地址) :直接下载网页到本地

在本地可以打开
2、urlcleanup() :清除爬虫所产生的缓存,清除完后,系统就会又恢复原来速度
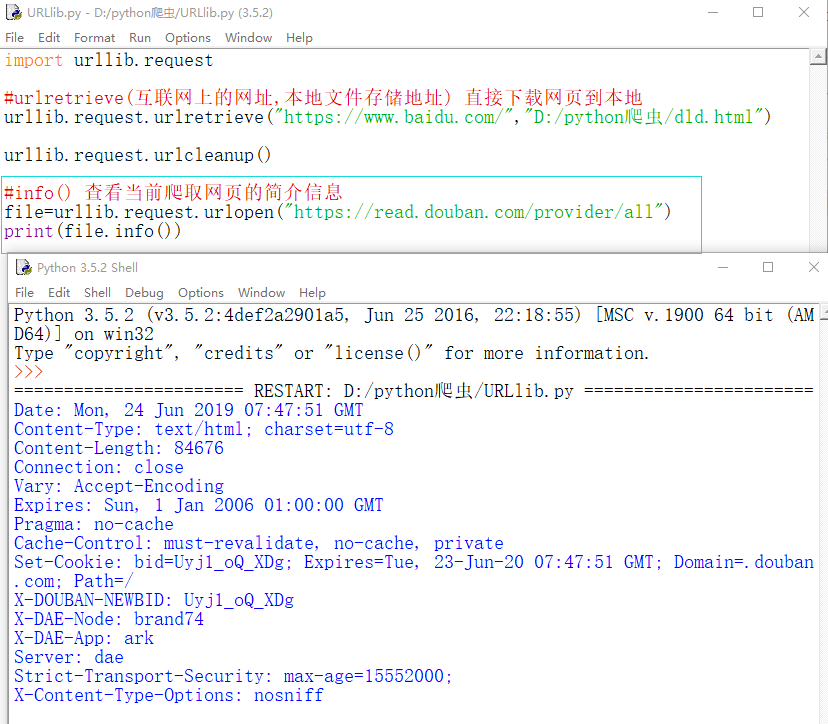
3、info() :查看当前爬取网页的简介信息
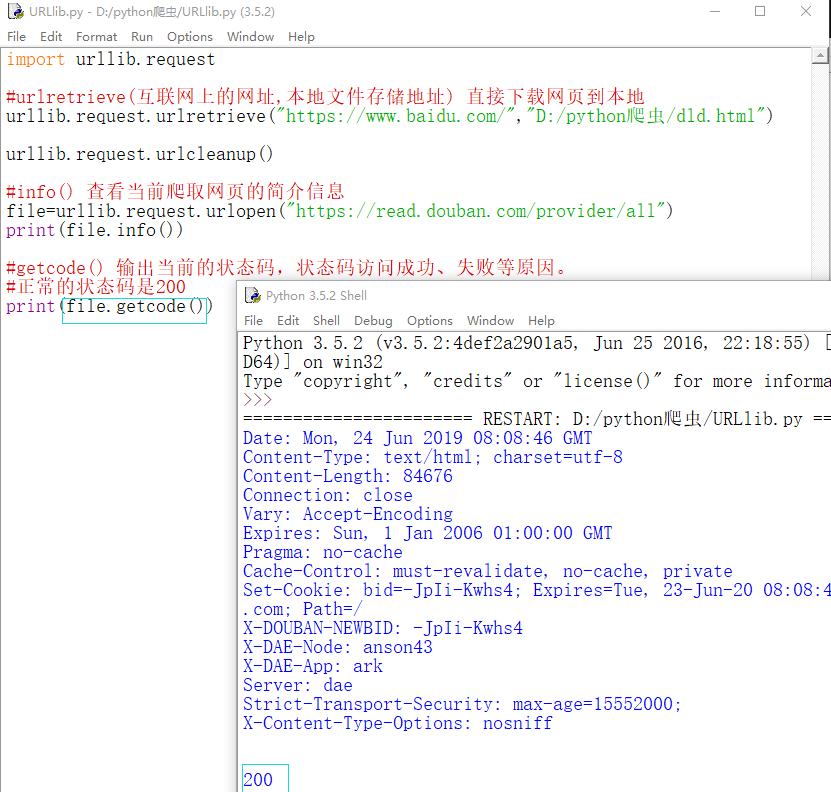
4、getcode() 输出当前爬取页面的的状态码,若成功返回200,若失败,返回失败的状态
5、geturl() 获取当前访问的网页的url
6、urlopen(网页地址) 爬取当前的网页

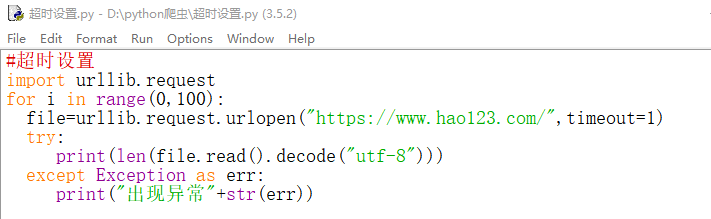
超时设置
由于网络速度或对方服务器问题,我们爬取一个网页的时候,都需要时间。访问一个网页,如果该网页长时间无响应,那么系统会判断该网页超时,即无法打开该网页。
有时候,可以根据自己的需要,来设置超时的时间值,比如:有些网站反应快,我们希望2秒钟没有反应,则判断为超时,那么此时,timeout的值就是2,再比如,有些网站服务器反应慢,那么此时,我们希望100秒没有反应,才判断为超时,那么此时timeout的值为100.