本篇文章以Python爬虫为实例,以应用为目标介绍正则表达式
- 获取某网站图片的爬虫算法
- 正则——初识
- 正则——元字符
- 正则——分组
- 正则——常用函数
1. 爬虫算法
import re
import urllib.request
def getHtml(url):
page=urllib.request.urlopen(url)
html=page.read()
return html
def getImg(html):
reg=r'src="(.*?\.jpg)"'
image=re.compile(reg)
imglist=re.findall(image,html.decode('utf-8'))
count=0
for i in imglist:
urllib.request.urlretrieve(i,'%s.jpg'% count)
count+=1
html=getHtml("https://xxx")
getImg(html)注意
- 1.因为py2.x和3.x不兼容,在2.x中引urllib包直接import urllib,但在3.x中,需要改为import urllib.request,并且每处使用相关函数都需改动。
- 2.因为html用decode(utf-8)进行解码,内容由bytes变成了String,而py3中urlopen返回的是bytes,所以需要改为decode(“utf-8”)。
详解
- 1.py中用到正则,必须要引包re,程序中需要打开网页,因为笔者是py3,所以引包urllib.request。
- 2.定义两个方法①getHtml(url)②getImg(html)。顾名思义,方法一是为了拿到网站中所有资源,方法二是为了从所有资源中找到目标资源,笔者以图片为例。
- 3.算法关键在第二个方法中的正则表达式内容reg=r’src=”(.?.jpg)”’,reg是匹配规则的名称,相当于变量名,加r是为了保持字符串的原意,这段正则匹配的内容是“src=xxx.jpg”,其中xxx可以用任何字符代替(可直接换成某网站,将代码复制粘贴即可看到效果,下载内容默认保存工程文件目录下)。能达到这个效果的原因即正则表达式在接下来的内容中介绍。
2. 正则——初始
正则表达式 (或RE)是一种小型的,高度专业化的编程语言,它内嵌在Python中,并通过re模块实现。
- 可以为想要匹配的相应字符串集指定相应规则
- 该字符集可能包含英文语句、email等等
- 可以得出字符串是否匹配相关模式的回答
- 也可以使用re来修改或分割字符串
- 也是一门小型的功能有限的语言,并非所有字符串处理都能用正则表达式解决
3.正则——元字符
| 元字符 | 意义 |
|---|---|
| [] | 常用来指定一个字符集,如t[io]p 可以表示top或者tip |
| ^ | 常用来匹配段首,如“^hello”表示在开始位置的hello |
| $ | 常用来表示匹配行尾,如‘hello$’,表示在行尾的hello |
| . | 匹配任意字符 |
| * | 表示前面字符出现0次或以上 |
| + | 表示前面字符至少出现一次 |
| ? | 表示前面字符至多只能出现一次 |
| {} | 括号中可以填数字表示前面字符重复的次数 |
以上是部分元字符,还有一些结合\的特殊字符。
| 字符 | 意义 |
|---|---|
| \d | 匹配任何十进制数,相当于类【0-9】 |
| \D | 匹配任何非数字字符,相当于类【^0-9】 |
| \s | 匹配任何空白字符,相当于类【\t\n\r\f\v】 |
| \S | 匹配任何非空白字符,相当于类【^\t\n\r\f\v】 |
| \w | 匹配任何数字字母字符,相当于类【a-aA-Z0-9_】 |
| \W | 匹配任何非数字字母字符,相当于类【^a-aA-Z0-9_】 |
举例:
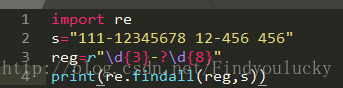

1.电话——假设某地区电话格式为010-12345678,用正则表达式来表示为\d{3}-?\d{8},可以看到,在定义的字符串中有多个元素,但只有111-12345678符合。
补充说明:findall(a,b)方法用来匹配,表示用规则a来匹配字符串s,若s中有符合条件则范围结果,否则返回空。同样可用来匹配的还有match()等,以match()为例,和findall()不同的是前者返回的是一个object对象。另外,正则匹配也有贪婪和非贪婪之分,例如“ab+”是一个贪婪的匹配,或将字符串中所有符合的都找出,而“ab+?”则是非贪婪匹配,只会出现一次,归根究底,还是?元字符发挥了作用。


2.网站——以www.baidu.com为例,正则为“w{3}.\w+.(com|cn)”,可以看到定义的s字符串中只有一个符合(此处用的match(注意返回的是一个对象))。另外,由于网址中的‘.’是元字符,有点计算机常识的都清楚需要加转义字符\。
因为网址最后的顶级域名有com cn等不确定的内容,所以用了另外一个知识“分组”,即表达式中的(),具体的内容会在下面继续介绍。
4.正则——分组
分组可以把相关数据化为一个整体,在这个整体中可以进行‘或’等操作,当有分组时,findall()会优先返回分组内容。


可以看到,将match()换成findall()以后,返回的结果就由对象换成了分组内容。
分组应用的场景很多,在对网页做分析或者做爬虫是非常有用
5.正则——常用函数
正则的常用函数之前环节就有介绍,例如用作匹配的findall()、match()等等。此处补充一个编译。
首先是编译的语法规则,如下图所示。

可以看到编译的函数是re.compile()参数是已经定义好的正则。
为什么要经编译呢?
对于使用次数较多的正则,通过编译可以提速,从而减少运行的时间。这对于规模较大的工程来说,非常有用。
上面内容中,通过爬虫算法以及一些小程序简单地介绍了正则表达式,笔者认为,对于一位计算机行业工作者来说,掌握正则的必要性不言而喻,很多时候能较大程度上提高工作效率。
以上内容,如有不足之处,还望多多批评指正,谢谢。