TF-Slim是一个轻量级库,用于定义,训练和评估TensorFlow中的复杂模型。 tf-slim的组件可以与本地tensorflow以及其他框架(如tf.contrib.learn)自由混合。
使用:
import tensorflow.contrib.slim as slim
为什么用TF-Slim?
TF-Slim是一个使构建,训练和评估神经网络更加简单的库:
- 允许用户通过消除样板代码来更加紧凑地定义模型。 这是通过使用argument scoping和许多high level layers 和 variables.来完成的。 这些工具提高了代码的可读性和可维护性,通过复制和粘贴超参数值降低了错误发生的可能性,并简化了超参数的调整。
- 通过提供常用的正则化使开发模型变得简单。
- 提供几种广泛使用的计算机视觉模型(例如,VGG,AlexNet)。 这些可以用作black box,或者可以以各种方式扩展,例如通过向不同内部层添加"multiple heads"。
- Slim使得扩展复杂模型变得很容易,并且通过使用预训练模型来热启动训练算法。
各种组件
TF-Slim由独立存在的几个部分组成。 这些包括以下主要部分(在下面详细解释)。
- arg_scope:provides a new scope named
arg_scopethat allows a user to define default arguments for specific operations within that scope. - data:contains TF-slim's dataset definition,data providers,parallel_reader,and decoding utilities.
- evaluation:contains routines for evaluating models.
- layers:contains high level layers for building models using tensorflow.
- learning:contains routines for training models.
- losses:contains commonly used loss functions.
- metrics:contains popular evaluation metrics.
- nets:contains popular network definitions such as VGG and AlexNet models.
- queues:provides a context manager for easily and safely starting and closing Queue Runners.
- regularizers:contains weight regularizers.
- variables:provides convenience wrappers for variable creation and manipulation.
通过组合
variables,layers 和 scopes,可以使用TF-Slim简洁地定义模型。 以下定义了每个元素。
在本地张量流中创建变量需要预定义值或初始化机制(例如从高斯分布中随机采样)。 此外,如果需要在特定设备(例如GPU)上创建变量,则必须明确规定。 为了减轻变量创建所需的代码,TF-Slim在variables.py中提供了一套简洁的包装函数,它允许调用者轻松定义变量。
例如,要创建weights变量,使用截断的正态分布对其进行初始化,使用l2_loss对其正则化,并在CPU上运行 ,只需声明以下内容:
weights = slim.variable('weights',
shape=[10, 10, 3 , 3],
initializer=tf.truncated_normal_initializer(stddev=0.1),
regularizer=slim.l2_regularizer(0.05),
device='/CPU:0')
请注意,在本地TensorFlow中,有两种类型的变量:常规变量regularvariables和本地(瞬态)local (transient) variables变量。 绝大多数变量是常规变量:一旦创建,它们可以使用保存程序保存到磁盘。 局部变量是仅在会话session期间存在并且不保存到磁盘的那些变量。
TF-Slim通过定义模型变量进一步区分变量,模型变量
model_variable是表示模型参数的变量。 模型变量在学习期间经过训练或微调,并在
evaluation或inference过程中从
checkpoint加载。 示例包括由slim.fully_connected或slim.conv2d图层创建的变量。 非模型变量是在学习或
evaluation
过程中使用的所有其他变量,但不是实际执行
inference所需的变量。 例如,global_step是在学习和
evaluation过程中使用的变量,但它实际上并不是模型的一部分。 同样,移动平均值变量
moving average variables 可能会反映模型变量,但移动平均值本身不是模型变量。
通过TF-Slim可以很容易地创建和获取模型变量和常规变量:
# Model Variables
weights = slim.model_variable('weights',
shape=[10, 10, 3 , 3],
initializer=tf.truncated_normal_initializer(stddev=0.1),
regularizer=slim.l2_regularizer(0.05),
device='/CPU:0')
model_variables = slim.get_model_variables()
# Regular variables
my_var = slim.variable('my_var',
shape=[20, 1],
initializer=tf.zeros_initializer())
regular_variables_and_model_variables = slim.get_variables()
当你通过TF-Slim的layer或直接通过slim.model_variable函数创建模型变量时,TF-Slim将该变量添加到tf.GraphKeys.MODEL_VARIABLES集合中。 如果您有自己的自定义layer或变量创建例程,但仍希望TF-Slim管理或了解模型变量,该怎么办? TF-Slim提供了一个方便的功能来将模型变量添加到其集合中:
my_model_variable = CreateViaCustomCode() # Letting TF-Slim know about the additional variable. slim.add_model_variable(my_model_variable)
尽管TensorFlow操作集相当多,但神经网络的开发人员通常会根据
"layers", "losses", "metrics", 和 "networks"等更高级概念来考虑模型。 诸如卷积层,完全连接层或BatchNorm层的层比单个TensorFlow操作更抽象,并且通常涉及多个操作。 此外,与更原始的操作不同,通常(但并非总是)的层具有与其关联的变量(可调参数)。 例如,神经网络中的卷积层由几个低层操作组成:
- Creating the weight and bias variables 建立权重和偏置
- Convolving the weights with the input from the previous layer 权重与之前层的输入进行卷积运算
- Adding the biases to the result of the convolution. 卷积和再加上偏置
- Applying an activation function. 激活函数
这样是很麻烦的:
input = ... with tf.name_scope('conv1_1') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 64, 128], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(input, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[128], dtype=tf.float32), trainable=True, name='biases') bias = tf.nn.bias_add(conv, biases) conv1 = tf.nn.relu(bias, name=scope)
为了减少重复复制代码的需要,TF-Slim提供了许多方便的操作,这些操作在神经网络层的更抽象层次上定义。 例如,将上面的代码与相应TF-Slim代码的调用进行比较:
input = ... net = slim.conv2d(input, 128, [3, 3], scope='conv1_1')
TF-Slim为构建神经网络的众多组件提供了标准实现。
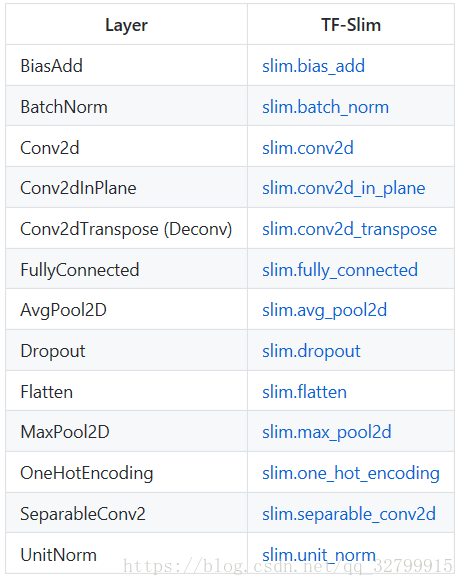
TF-Slim还提供了两种称为重复
repeat和stack堆栈的元操作,允许用户重复执行相同的操作。 例如,请考虑VGG网络中的以下片段,这些片段的层在连接层之间在一行中执行多个卷积:
net = ... net = slim.conv2d(net, 256, [3, 3], scope='conv3_1') net = slim.conv2d(net, 256, [3, 3], scope='conv3_2') net = slim.conv2d(net, 256, [3, 3], scope='conv3_3') net = slim.max_pool2d(net, [2, 2], scope='pool2')
为了减少重复,可以使用for循环:
net = ... for i in range(3): net = slim.conv2d(net, 256, [3, 3], scope='conv3_%d' % (i+1)) net = slim.max_pool2d(net, [2, 2], scope='pool2')
或者可以使用repeat操作:
net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], scope='conv3') net = slim.max_pool2d(net, [2, 2], scope='pool2')请注意,slim.repeat不仅适用于同一个参数,它还足够聪明地展开scopes,以便分配给每个后续调用slim.conv2d的scopes都附加下划线和迭代编号。 更具体地说,上例中的范围将被命名为'conv3 / conv3_1','conv3 / conv3_2'和'conv3 / conv3_3'。
此外,TF-Slim的slim.stack运算符允许调用者重复应用具有不同参数的相同操作来创建堆栈或塔层。 slim.stack还为每个创建的操作创建一个新的tf.variable_scope。 例如,一种创建多层感知器(MLP)的简单方法:
# Verbose way: x = slim.fully_connected(x, 32, scope='fc/fc_1') x = slim.fully_connected(x, 64, scope='fc/fc_2') x = slim.fully_connected(x, 128, scope='fc/fc_3') # Equivalent, TF-Slim way using slim.stack: slim.stack(x, slim.fully_connected, [32, 64, 128], scope='fc')
在这个例子中,slim.stack调用slim.fully_connected三次,将一次函数调用的输出传递给下一个。 然而,每次调用中隐藏单元的数量从32个变为64个。同样,可以使用堆栈来简化多个卷积塔:
# Verbose way: x = slim.conv2d(x, 32, [3, 3], scope='core/core_1') x = slim.conv2d(x, 32, [1, 1], scope='core/core_2') x = slim.conv2d(x, 64, [3, 3], scope='core/core_3') x = slim.conv2d(x, 64, [1, 1], scope='core/core_4') # Using stack: slim.stack(x, slim.conv2d, [(32, [3, 3]), (32, [1, 1]), (64, [3, 3]), (64, [1, 1])], scope='core')Scopes
除了TensorFlow(name_scope,variable_scope)中的scope机制类型外,TF-Slim还添加了一个名为arg_scope的新scope机制。 这个新的scope允许用户指定一个或多个
operations和一组
arguments,这些
arguments将被传递给arg_scope中定义的每个操作。 这个功能最好用例子来说明。 考虑下面的代码片段:
net = slim.conv2d(inputs, 64, [11, 11], 4, padding='SAME',
weights_initializer=tf.truncated_normal_initializer(stddev=0.01),
weights_regularizer=slim.l2_regularizer(0.0005), scope='conv1')
net = slim.conv2d(net, 128, [11, 11], padding='VALID',
weights_initializer=tf.truncated_normal_initializer(stddev=0.01),
weights_regularizer=slim.l2_regularizer(0.0005), scope='conv2')
net = slim.conv2d(net, 256, [11, 11], padding='SAME',
weights_initializer=tf.truncated_normal_initializer(stddev=0.01),
weights_regularizer=slim.l2_regularizer(0.0005), scope='conv3')
这三个卷积层共享许多相同的超参数。两个具有相同的填充,所有三个都具有相同的weights_initializer和weight_regularizer。 这段代码很难阅读,并且包含很多重复的值,这些值应该被分解出来。 一种解决方案是使用变量指定默认值:
padding = 'SAME'
initializer = tf.truncated_normal_initializer(stddev=0.01)
regularizer = slim.l2_regularizer(0.0005)
net = slim.conv2d(inputs, 64, [11, 11], 4,
padding=padding,
weights_initializer=initializer,
weights_regularizer=regularizer,
scope='conv1')
net = slim.conv2d(net, 128, [11, 11],
padding='VALID',
weights_initializer=initializer,
weights_regularizer=regularizer,
scope='conv2')
net = slim.conv2d(net, 256, [11, 11],
padding=padding,
weights_initializer=initializer,
weights_regularizer=regularizer,
scope='conv3')
该解决方案确保所有三个卷积共享完全相同的参数值,但不能完全减少代码混乱。 通过使用arg_scope,可以确保每个图层使用相同的值并简化代码:
with slim.arg_scope([slim.conv2d], padding='SAME',
weights_initializer=tf.truncated_normal_initializer(stddev=0.01)
weights_regularizer=slim.l2_regularizer(0.0005)):
net = slim.conv2d(inputs, 64, [11, 11], scope='conv1')
net = slim.conv2d(net, 128, [11, 11], padding='VALID', scope='conv2')
net = slim.conv2d(net, 256, [11, 11], scope='conv3')如示例所示,使用arg_scope可使代码更干净,更简单且更易于维护。 请注意,虽然参数值是在arg_scope中指定的,但它们可以在本地覆盖。 当
padding被设置为'SAME'时,第二个卷积用'VALID'的值覆盖它。
也可以嵌套arg_scopes并在同一scope内使用多个操作。 例如:
with slim.arg_scope([slim.conv2d, slim.fully_connected],
activation_fn=tf.nn.relu,
weights_initializer=tf.truncated_normal_initializer(stddev=0.01),
weights_regularizer=slim.l2_regularizer(0.0005)):
with slim.arg_scope([slim.conv2d], stride=1, padding='SAME'):
net = slim.conv2d(inputs, 64, [11, 11], 4, padding='VALID', scope='conv1')
net = slim.conv2d(net, 256, [5, 5],
weights_initializer=tf.truncated_normal_initializer(stddev=0.03),
scope='conv2')
net = slim.fully_connected(net, 1000, activation_fn=None, scope='fc')
在此例中,第一个arg_scope将相同的weights_initializer和weights_regularizer参数应用于其scope内的conv2d和fully_connected图层。 在第二个arg_scope中,仅指定了conv2d的其他缺省参数。
通过结合TF-Slim 的
Variables, Operations 和 scopes,我们可以用很少的代码行编写一个非常复杂的网络。例如,整个VGG体系结构可以通过以下代码片段来定义:
def vgg16(inputs):
with slim.arg_scope([slim.conv2d, slim.fully_connected],
activation_fn=tf.nn.relu,
weights_initializer=tf.truncated_normal_initializer(0.0, 0.01),
weights_regularizer=slim.l2_regularizer(0.0005)):
net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1')
net = slim.max_pool2d(net, [2, 2], scope='pool1')
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2')
net = slim.max_pool2d(net, [2, 2], scope='pool2')
net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], scope='conv3')
net = slim.max_pool2d(net, [2, 2], scope='pool3')
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv4')
net = slim.max_pool2d(net, [2, 2], scope='pool4')
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv5')
net = slim.max_pool2d(net, [2, 2], scope='pool5')
net = slim.fully_connected(net, 4096, scope='fc6')
net = slim.dropout(net, 0.5, scope='dropout6')
net = slim.fully_connected(net, 4096, scope='fc7')
net = slim.dropout(net, 0.5, scope='dropout7')
net = slim.fully_connected(net, 1000, activation_fn=None, scope='fc8')
return net
训练Tensorflow模型需要一个模型,一个损失函数,梯度计算和一个反复迭代计算损失,计算梯度然后更新权重的训练例程。 TF-Slim提供了常见的损失函数和一组运行train和evaluation例程的辅助函数。
损失函数最小化。对于分类问题,这通常是跨分类的真实分布和预测概率分布之间的交叉熵。对于回归问题,这通常是预测值和真值之间的平方和差异。
某些模型(如多任务学习模型)需要同时使用多种损失函数。 换句话说,最终被最小化的损失函数是各种其他损失函数的总和。 例如,考虑预测图像中的场景类型以及每个像素的相机深度的模型。 该模型的损失函数将是分类损失和深度预测损失的总和。
TF-Slim提供了一种机制,通过loss model来定义和跟踪损失功能。
import tensorflow as tf import tensorflow.contrib.slim.nets as nets vgg = nets.vgg # Load the images and labels. images, labels = ... # Create the model. predictions, _ = vgg.vgg_16(images) # Define the loss functions and get the total loss. loss = slim.losses.softmax_cross_entropy(predictions, labels)
在这个例子中,我们从创建模型开始(使用TF-Slim的VGG实现),并添加标准分类损失。 现在,让我们看看产生多个输出的多任务模型的情况:
# Load the images and labels. images, scene_labels, depth_labels = ... # Create the model. scene_predictions, depth_predictions = CreateMultiTaskModel(images) # Define the loss functions and get the total loss. classification_loss = slim.losses.softmax_cross_entropy(scene_predictions, scene_labels) sum_of_squares_loss = slim.losses.sum_of_squares(depth_predictions, depth_labels) # The following two lines have the same effect: total_loss = classification_loss + sum_of_squares_loss total_loss = slim.losses.get_total_loss(add_regularization_losses=False)
在这个例子中,我们有两个损失,slim.losses.softmax_cross_entropy和slim.losses.sum_of_squares。 我们可以通过将它们相加(total_loss)或通过调用slim.losses.get_total_loss()来获得全部损失。当通过TF-Slim损失函数时,TF-Slim将损失添加到特殊的TensorFlow损失函数集合中。 可以手动管理全部损失,或允许TF-Slim管理它们。
如果你想让TF-Slim为你管理损失但是有自定义损失函数呢?loss_ops.py也有一个功能,将这种损失添加到TF-Slims集合中。 例如:
# Load the images and labels. images, scene_labels, depth_labels, pose_labels = ... # Create the model. scene_predictions, depth_predictions, pose_predictions = CreateMultiTaskModel(images) # Define the loss functions and get the total loss. classification_loss = slim.losses.softmax_cross_entropy(scene_predictions, scene_labels) sum_of_squares_loss = slim.losses.sum_of_squares(depth_predictions, depth_labels) pose_loss = MyCustomLossFunction(pose_predictions, pose_labels) slim.losses.add_loss(pose_loss) # Letting TF-Slim know about the additional loss. # The following two ways to compute the total loss are equivalent: regularization_loss = tf.add_n(slim.losses.get_regularization_losses()) total_loss1 = classification_loss + sum_of_squares_loss + pose_loss + regularization_loss # (Regularization Loss is included in the total loss by default). total_loss2 = slim.losses.get_total_loss()在这个例子中,我们可以再次手动产生总损失函数,或者让TF-Slim知道额外损失,并让TF-Slim处理损失。
TF-Slim为learning.py中的模型提供了一套简单但强大的工具。 这些功能包括train model,可以重复计算损失,计算梯度并将模型保存到磁盘,以及用于梯度操作的多种便利功能。例如,一旦我们指定了模型,损失函数和优化方案,我们可以调用slim.learning.create_train_op和slim.learning.train来执行优化:
g = tf.Graph()
# Create the model and specify the losses...
...
total_loss = slim.losses.get_total_loss()
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
# create_train_op ensures that each time we ask for the loss, the update_ops
# are run and the gradients being computed are applied too.
train_op = slim.learning.create_train_op(total_loss, optimizer)
logdir = ... # Where checkpoints are stored.
slim.learning.train(
train_op,
logdir,
number_of_steps=1000,
save_summaries_secs=300,
save_interval_secs=600):
在本例中,train_op提供了slim.learning.train,用于(a)计算损失和(b)计算梯度,进行参数优化。 logdir为checkpoints和events文件的存储目录。训练1000次。最后,save_summaries_secs=300表示我们将每隔5分钟计算summaries,save_interval_secs = 600表示我们将每10分钟保存一次模型checkpoint。
import tensorflow as tf
import tensorflow.contrib.slim.nets as nets
slim = tf.contrib.slim
vgg = nets.vgg
...
train_log_dir = ...
if not tf.gfile.Exists(train_log_dir):
tf.gfile.MakeDirs(train_log_dir)
with tf.Graph().as_default():
# Set up the data loading:
images, labels = ...
# Define the model:
predictions = vgg.vgg_16(images, is_training=True)
# Specify the loss function:
slim.losses.softmax_cross_entropy(predictions, labels)
total_loss = slim.losses.get_total_loss()
tf.summary.scalar('losses/total_loss', total_loss)
# Specify the optimization scheme:
optimizer = tf.train.GradientDescentOptimizer(learning_rate=.001)
# create_train_op that ensures that when we evaluate it to get the loss,
# the update_ops are done and the gradient updates are computed.
train_tensor = slim.learning.create_train_op(total_loss, optimizer)
# Actually runs training.
slim.learning.train(train_tensor, train_log_dir)
从
Checkpoint 恢复变量
模型训练完成后,可以使用tf.train.Saver()从一个给定的checkpoint恢复变量来恢复它。对于很多情况,tf.train.Saver()提供了一个简单的机制来恢复所有或部分变量。
# Create some variables.
v1 = tf.Variable(..., name="v1")
v2 = tf.Variable(..., name="v2")
...
# Add ops to restore all the variables.
restorer = tf.train.Saver()
# Add ops to restore some variables.
restorer = tf.train.Saver([v1, v2])
# Later, launch the model, use the saver to restore variables from disk, and
# do some work with the model.
with tf.Session() as sess:
# Restore variables from disk.
restorer.restore(sess, "/tmp/model.ckpt")
print("Model restored.")
# Do some work with the model
...
恢复变量
或 选择保存或恢复部分变量可以在
Variables看到更多细节
部分恢复模型
通常需要在全新的数据集上对预先训练好的模型进行微调。在此情况下,可以使用TF-Slim的辅助函数来选择要恢复的变量子集:
# Create some variables.
v1 = slim.variable(name="v1", ...)
v2 = slim.variable(name="nested/v2", ...)
...
# Get list of variables to restore (which contains only 'v2'). These are all
# equivalent methods:
variables_to_restore = slim.get_variables_by_name("v2")
# or
variables_to_restore = slim.get_variables_by_suffix("2")
# or
variables_to_restore = slim.get_variables(scope="nested")
# or
variables_to_restore = slim.get_variables_to_restore(include=["nested"])
# or
variables_to_restore = slim.get_variables_to_restore(exclude=["v1"])
# Create the saver which will be used to restore the variables.
restorer = tf.train.Saver(variables_to_restore)
with tf.Session() as sess:
# Restore variables from disk.
restorer.restore(sess, "/tmp/model.ckpt")
print("Model restored.")
# Do some work with the model
...
从checkpoint恢复变量时,Saver会将变量名称定位到checkpoint文件中,并将它们映射到当前graph中的变量。 上面,我们通过传递一个变量列表来创建一个saver。 在这种情况下,要在每个提供的变量的var.op.name中隐式地获取要在checkpoint文件中定位的变量的名称。
当checkpoint文件中的变量名称与graph中的变量名称匹配时,此函数可以很好地工作。但是,有时我们想从一个checkpoint恢复一个模型,该checkpoint的变量名称与当前graph中的名称不同。在这种情况下,我们必须为Saver提供一个从每个checkpoint变量名映射到每个graph变量的字典。 考虑下面的例子,通过一个简单的函数获取checkpoint变量名称:
# Assuming than 'conv1/weights' should be restored from 'vgg16/conv1/weights'
def name_in_checkpoint(var):
return 'vgg16/' + var.op.name
# Assuming than 'conv1/weights' and 'conv1/bias' should be restored from 'conv1/params1' and 'conv1/params2'
def name_in_checkpoint(var):
if "weights" in var.op.name:
return var.op.name.replace("weights", "params1")
if "bias" in var.op.name:
return var.op.name.replace("bias", "params2")
variables_to_restore = slim.get_model_variables()
variables_to_restore = {name_in_checkpoint(var):var for var in variables_to_restore}
restorer = tf.train.Saver(variables_to_restore)
with tf.Session() as sess:
# Restore variables from disk.
restorer.restore(sess, "/tmp/model.ckpt")
考虑一下我们有预先训练好的VGG16模型的。 该模型在ImageNet数据集上进行了训练,该数据集有1000个类。 但是,我们想将其应用于仅有20个类别的Pascal VOC数据集。 为此,我们可以使用不包括最后一层的预先训练的模型的值来初始化我们的新模型:
# Load the Pascal VOC data image, label = MyPascalVocDataLoader(...) images, labels = tf.train.batch([image, label], batch_size=32) # Create the model predictions = vgg.vgg_16(images) train_op = slim.learning.create_train_op(...) # Specify where the Model, trained on ImageNet, was saved. model_path = '/path/to/pre_trained_on_imagenet.checkpoint' # Specify where the new model will live: log_dir = '/path/to/my_pascal_model_dir/' # Restore only the convolutional layers: variables_to_restore = slim.get_variables_to_restore(exclude=['fc6', 'fc7', 'fc8']) init_fn = assign_from_checkpoint_fn(model_path, variables_to_restore) # Start training. slim.learning.train(train_op, log_dir, init_fn=init_fn)
一旦我们训练了一个模型(或者甚至在模型忙于训练时),我们希望看到模型在实践中的表现如何。 选择一组评估指标,评估指标将评估模型的性能,以及实际加载数据的评估代码,执行inference,将结果与实际情况进行比较并记录评估分数。 该步骤可以执行一次或定期重复。
我们将metrics定义为不是损失函数的性能度量(损失在训练期间直接进行优化),但我们仍然对评估模型感兴趣。 例如,我们可能希望尽量减少对数损失,但我们的metrics可能是F1分数(测试准确性)或iou(这是不可区分的,因此不能用作损失)。
TF-Slim提供了一系列度量操作,使评估模型变得简单。 抽象地说,计算度量值可以分为三部分:
- Initialization: initialize the variables used to compute the metrics.
- Aggregation: perform operations (sums, etc) used to compute the metrics.
- Finalization: (optionally) perform any final operation to compute metricvalues. For example, computing means, mins, maxes, etc.
例如,要计算mean_absolute_error,需要将两个变量(count和total)初始化为零。 计算所有预测值和标签的绝对值之差,求和,总数除以计数以获得平均值。
以下示例演示了用于声明metrics的API。 由于metrics通常是在与训练集不同的测试集上进行评估的,因此我们假定我们使用的是测试数据:
images, labels = LoadTestData(...) predictions = MyModel(images) mae_value_op, mae_update_op = slim.metrics.streaming_mean_absolute_error(predictions, labels) mre_value_op, mre_update_op = slim.metrics.streaming_mean_relative_error(predictions, labels) pl_value_op, pl_update_op = slim.metrics.percentage_less(mean_relative_errors, 0.3)创建度量标准会返回两个值:value_op和update_op。 value_op是一个幂等操作,返回metric的当前值。 update_op是执行上述步骤以及返回metric的操作。
跟踪每个value_op和update_op可能会很费力。 为了解决这个问题,TF-Slim提供了两个方便的函数:
# Aggregates the value and update ops in two lists:
value_ops, update_ops = slim.metrics.aggregate_metrics(
slim.metrics.streaming_mean_absolute_error(predictions, labels),
slim.metrics.streaming_mean_squared_error(predictions, labels))
# Aggregates the value and update ops in two dictionaries:
names_to_values, names_to_updates = slim.metrics.aggregate_metric_map({
"eval/mean_absolute_error": slim.metrics.streaming_mean_absolute_error(predictions, labels),
"eval/mean_squared_error": slim.metrics.streaming_mean_squared_error(predictions, labels),
})
import tensorflow as tf
import tensorflow.contrib.slim.nets as nets
slim = tf.contrib.slim
vgg = nets.vgg
# Load the data
images, labels = load_data(...)
# Define the network
predictions = vgg.vgg_16(images)
# Choose the metrics to compute:
names_to_values, names_to_updates = slim.metrics.aggregate_metric_map({
"eval/mean_absolute_error": slim.metrics.streaming_mean_absolute_error(predictions, labels),
"eval/mean_squared_error": slim.metrics.streaming_mean_squared_error(predictions, labels),
})
# Evaluate the model using 1000 batches of data:
num_batches = 1000
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
for batch_id in range(num_batches):
sess.run(names_to_updates.values())
metric_values = sess.run(names_to_values.values())
for metric, value in zip(names_to_values.keys(), metric_values):
print('Metric %s has value: %f' % (metric, value))
TF-Slim提供一个评估模块(evaluation.py),其中包含用于使用metric_ops.py模块中的指标编写模型评估脚本的帮助函数。 这些功能包括定期运行评估,评估各批数据的指标以及打印和汇总指标结果。 例如:
import tensorflow as tf
slim = tf.contrib.slim
# Load the data
images, labels = load_data(...)
# Define the network
predictions = MyModel(images)
# Choose the metrics to compute:
names_to_values, names_to_updates = slim.metrics.aggregate_metric_map({
'accuracy': slim.metrics.accuracy(predictions, labels),
'precision': slim.metrics.precision(predictions, labels),
'recall': slim.metrics.recall(mean_relative_errors, 0.3),
})
# Create the summary ops such that they also print out to std output:
summary_ops = []
for metric_name, metric_value in names_to_values.iteritems():
op = tf.summary.scalar(metric_name, metric_value)
op = tf.Print(op, [metric_value], metric_name)
summary_ops.append(op)
num_examples = 10000
batch_size = 32
num_batches = math.ceil(num_examples / float(batch_size))
# Setup the global step.
slim.get_or_create_global_step()
output_dir = ... # Where the summaries are stored.
eval_interval_secs = ... # How often to run the evaluation.
slim.evaluation.evaluation_loop(
'local',
checkpoint_dir,
log_dir,
num_evals=num_batches,
eval_op=names_to_updates.values(),
summary_op=tf.summary.merge(summary_ops),
eval_interval_secs=eval_interval_secs)