Spark中的Spark Streaming可以用于实时流项目的开发,实时流项目的数据源除了可以来源于日志、文件、网络端口等,常常也有这种需求,那就是实时分析处理MySQL中的增量数据。面对这种需求当然我们可以通过JDBC的方式定时查询Mysql,然后再对查询到的数据进行处理也能得到预期的结果,但是Mysql往往还有其他业务也在使用,这些业务往往比较重要,通过JDBC方式频繁查询会对Mysql造成大量无形的压力,甚至可能会影响正常业务的使用,在基本不影响其他Mysql正常使用的情况下完成对增量数据的处理,那就需要 Canal 了。 假设Mysql中 canal_test 库下有一张表 policy_cred ,需要统计实时统计 policy_status 状态为1的 mor_rate 的的变化趋势,并标注比率的风险预警等级。
1. Canal
Canal [kə'næl] 是阿里巴巴开源的纯java开发的基于数据库binlog的增量订阅&消费组件。Canal的原理是模拟为一个Mysql slave的交互协议,伪装自己为MySQL slave,向Mysql Master发送dump协议,然后Mysql master接收到这个请求后将binary log推送给slave(也就是Canal),Canal解析binary log对象。详细可以查阅Canal的官方文档[alibaba/canal wiki]。
1.1 Canal 安装
Canal的server mode在1.1.x版本支持的有TPC、Kafka、RocketMQ。本次安装的canal版本为1.1.2,Canal版本最后在1.1.1之后。server端采用MQ模式,MQ选用Kafka。服务器系统为Centos7,其他环境为:jdk8、Scala 2.11、Mysql、Zookeeper、Kafka。
1.1.1 准备
安装Canal之前我们先把如下安装好 Mysql a. 如果没有Mysql: 详细的安装过程可参考我的另一篇博客[Centos7环境下离线安装mysql 5.7 / mysql 8.0] b. 开启Mysql的binlog。修改/etc/my.cnf,在[mysqld]下添加如下配置,改完之后重启 Mysql/etc/init.d/mysql restart
[mysqld]
#添加这一行就ok
log-bin=mysql-bin
#选择row模式
binlog-format=ROW
#配置mysql replaction需要定义,不能和canal的slaveId重复
server_id=1 c. 创建一个Mysql用户并赋予相应权限,用于Canal使用
mysql> CREATE USER canal IDENTIFIED BY 'canal';
mysql> GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
mysql> GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
mysql> FLUSH PRIVILEGES;Zookeeper
因为安装Kafka时需要Zookeeper,例如ZK安装后地址为:cdh3:2181,cdh4:2181,cdh5:2181
Kafka 例如安装后的地址为:node1:9092,node2:9092,node3:9092 安装后创建一个Topic,例如创建一个 example
kafka-topics.sh --create --zookeeper cdh3:2181,cdh4:2181,cdh5:2181 --partitions 2 --replication-factor 1 --topic example1.1.2 安装Canal
1. 下载Canal 访问Canal的Release页 canal v1.1.2
wget https://github.com/alibaba/canal/releases/download/canal-1.1.2/canal.deployer-1.1.2.tar.gz2. 解压
注意 这里一定要先创建出一个目录,直接解压会覆盖文件
mkdir -p /usr/local/canal
mv canal.deployer-1.1.2.tar.gz /usr/local/canal/
tar -zxvf canal.deployer-1.1.2.tar.gz3. 修改instance 配置文件
vim $CANAL_HOME/conf/example/instance.properties,修改如下项,其他默认即可
## mysql serverId , v1.0.26+ will autoGen , 不要和server_id重复
canal.instance.mysql.slaveId=3
# position info。Mysql的url
canal.instance.master.address=node1:3306
# table meta tsdb info
canal.instance.tsdb.enable=false
# 这里配置前面在Mysql分配的用户名和密码
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset=UTF-8
# 配置需要检测的库名,可以不配置,这里只检测canal_test库
canal.instance.defaultDatabaseName=canal_test
# enable druid Decrypt database password
canal.instance.enableDruid=false
# 配置过滤的正则表达式,监测canal_test库下的所有表
canal.instance.filter.regex=canal_test\\..*
# 配置MQ
## 配置上在Kafka创建的那个Topic名字
canal.mq.topic=example
## 配置分区编号为1
canal.mq.partition=14. 修改canal.properties配置文件
vim $CANAL_HOME/conf/canal.properties,修改如下项,其他默认即可
# 这个是如果开启的是tcp模式,会占用这个11111端口,canal客户端通过这个端口获取数据
canal.port = 11111
# 可以配置为:tcp, kafka, RocketMQ,这里配置为kafka
canal.serverMode = kafka
# 这里将这个注释掉,否则启动会有一个警告
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
##################################################
######### MQ #############
##################################################
canal.mq.servers = node1:9092,node2:9092,node3:9092
canal.mq.retries = 0
canal.mq.batchSize = 16384
canal.mq.maxRequestSize = 1048576
canal.mq.lingerMs = 1
canal.mq.bufferMemory = 33554432
# Canal的batch size, 默认50K, 由于kafka最大消息体限制请勿超过1M(900K以下)
canal.mq.canalBatchSize = 50
# Canal get数据的超时时间, 单位: 毫秒, 空为不限超时
canal.mq.canalGetTimeout = 100
# 是否为flat json格式对象
canal.mq.flatMessage = true
canal.mq.compressionType = none
canal.mq.acks = all
# kafka消息投递是否使用事务
#canal.mq.transaction = false5. 启动Canal
$CANAL_HOME/bin/startup.sh6. 验证
查看日志
启动后会在logs下生成两个日志文件:logs/canal/canal.log、logs/example/example.log,查看这两个日志,保证没有报错日志。
如果是在虚拟机安装,最好给2个核数以上。
确保登陆的系统的hostname可以ping通。
在Mysql数据库中进行增删改查的操作,然后查看Kafka的topic为 example 的数据
kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --from-beginning --topic example
7. 关闭Canal
不用的时候一定要通过这个命令关闭,如果是用kill或者关机,当再次启动依然会提示要先执行stop.sh脚本后才能再启动。
$CANAL_HOME/bin/stop.sh*1.2 Canal 客户端代码
如果我们不使用Kafka作为Canal客户端,我们也可以用代码编写自己的Canal客户端,然后在代码中指定我们的数据去向。此时只需要将canal.properties配置文件中的canal.serverMode值改为tcp。编写我们的客户端代码。
在Maven项目的pom中引入:
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.2</version>
</dependency>编写代码:
/**
* Canal客户端。
* 注意:canal服务端只会连接一个客户端,当启用多个客户端时,其他客户端是就无法获取到数据。所以启动一个实例即可
*
* @see <a href="https://github.com/alibaba/canal/wiki/ClientExample">官方文档:ClientSample代码</a>
*
* Created by yore on 2019/3/16 10:50
*/
public class SimpleCanalClientExample {
public static void main(String args[]) {
/**
* 创建链接
* SocketAddress: 如果提交到canal服务端所在的服务器上运行这里可以改为 new InetSocketAddress(AddressUtils.getHostIp(), 11111)
* destination 通服务端canal.properties中的canal.destinations = example配置对应
* username:
* password:
*/
CanalConnector connector = CanalConnectors.newSingleConnector(
new InetSocketAddress("node1", 11111),
"example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
int totalEmptyCount = 120;
while (emptyCount < totalEmptyCount) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
emptyCount = 0;
// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
System.out.println("empty too many times, exit");
} finally {
connector.disconnect();
}
}
private static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
/**
* 如果只对某些库的数据操作,可以加如下判断:
* if("库名".equals(entry.getHeader().getSchemaName())){
* //TODO option
* }
*
* 如果只对某些表的数据变动操作,可以加如下判断:
* if("表名".equals(entry.getHeader().getTableName())){
* //todo option
* }
*
*/
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<Column> columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}本地运行上述代码,我们修改Mysql数据中的数据,可在控制台中看到数据的改变:
empty count : 20
empty count : 21
empty count : 22
================> binlog[mysql-bin.000009:1510] , name[canal_test,customer] , eventType : INSERT
id : 4 update=true
name : spark update=true
empty count : 1
empty count : 2
empty count : 32. Spark
通过上一步我们已经能够获取到 canal_test 库的变化数据,并且已经可将将变化的数据实时推送到Kafka中,Kafka中接收到的数据是一条Json格式的数据,我们需要对 INSERT 和 UPDATE 类型的数据处理,并且只处理状态为1的数据,然后需要计算 mor_rate 的变化,并判断 mor_rate 的风险等级,0-75%为G1等级,75%-80%为R1等级,80%-100%为R2等级。最后将处理的结果保存到DB,可以保存到Redis、Mysql、MongoDB,或者推送到Kafka都可以。这里是将结果数据保存到了Mysql。
2.1 在Mysql中创建如下两张表:
-- 在canal_test库下创建表
CREATE TABLE `policy_cred` (
p_num varchar(22) NOT NULL,
policy_status varchar(2) DEFAULT NULL COMMENT '状态:0、1',
mor_rate decimal(20,4) DEFAULT NULL,
load_time datetime DEFAULT NULL,
PRIMARY KEY (`p_num`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 在real_result库下创建表
CREATE TABLE `real_risk` (
p_num varchar(22) NOT NULL,
risk_rank varchar(8) DEFAULT NULL COMMENT '等级:G1、R1、R2',
mor_rate decimal(20,4) ,
ch_mor_rate decimal(20,4),
load_time datetime DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;2.2 Spark代码开发:
2.2.1 在resources下new一个项目的配置文件my.properties
## spark
# spark://cdh3:7077
spark.master=local[2]
spark.app.name=m_policy_credit_app
spark.streaming.durations.sec=10
spark.checkout.dir=src/main/resources/checkpoint
## Kafka
bootstrap.servers=node1:9092,node2:9092,node3:9092
group.id=m_policy_credit_gid
# latest, earliest, none
auto.offset.reset=latest
enable.auto.commit=false
kafka.topic.name=example
## Mysql
mysql.jdbc.driver=com.mysql.jdbc.Driver
mysql.db.url=jdbc:mysql://node1:3306/real_result
mysql.user=root
mysql.password=123456
mysql.connection.pool.size=10
2.2.2 在pom.xml文件中引入如下依
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<scala.version>2.11.8</scala.version>
<spark.version>2.4.0</spark.version>
<canal.client.version>1.1.2</canal.client.version>
</properties>
<dependencies>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>${canal.client.version}</version>
<exclusions>
<exclusion>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark -->
<!-- spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- spark-streaming-kafka -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.51</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
</dependencies>2.2.3 在scala源码目录下的包下编写配置文件的工具类
package yore.spark
import java.util.Properties
/**
* Properties的工具类
*
* Created by yore on 2018-06-29 14:05
*/
object PropertiesUtil {
private val properties: Properties = new Properties
/**
*
* 获取配置文件Properties对象
*
* @author yore
* @return java.util.Properties
* date 2018/6/29 14:24
*/
def getProperties() :Properties = {
if(properties.isEmpty){
//读取源码中resource文件夹下的my.properties配置文件
val reader = getClass.getResourceAsStream("/my.properties")
properties.load(reader)
}
properties
}
/**
*
* 获取配置文件中key对应的字符串值
*
* @author yore
* @return java.util.Properties
* @date 2018/6/29 14:24
*/
def getPropString(key : String) : String = {
getProperties().getProperty(key)
}
/**
*
* 获取配置文件中key对应的整数值
*
* @author yore
* @return java.util.Properties
* @date 2018/6/29 14:24
*/
def getPropInt(key : String) : Int = {
getProperties().getProperty(key).toInt
}
/**
*
* 获取配置文件中key对应的布尔值
*
* @author yore
* @return java.util.Properties
* @date 2018/6/29 14:24
*/
def getPropBoolean(key : String) : Boolean = {
getProperties().getProperty(key).toBoolean
}
}
2.2.4 在scala源码目录下的包下编写数据库操作的工具类
package yore.spark
import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet, SQLException}
import java.util.concurrent.LinkedBlockingDeque
import scala.collection.mutable.ListBuffer
/**
*
* Created by yore on 2018/11/14 20:34
*/
object JDBCWrapper {
private var jdbcInstance : JDBCWrapper = _
def getInstance() : JDBCWrapper = {
synchronized{
if(jdbcInstance == null){
jdbcInstance = new JDBCWrapper()
}
}
jdbcInstance
}
}
class JDBCWrapper {
// 连接池的大小
val POOL_SIZE : Int = PropertiesUtil.getPropInt("mysql.connection.pool.size")
val dbConnectionPool = new LinkedBlockingDeque[Connection](POOL_SIZE)
try
Class.forName(PropertiesUtil.getPropString("mysql.jdbc.driver"))
catch {
case e: ClassNotFoundException => e.printStackTrace()
}
for(i <- 0 until POOL_SIZE){
try{
val conn = DriverManager.getConnection(
PropertiesUtil.getPropString("mysql.db.url"),
PropertiesUtil.getPropString("mysql.user"),
PropertiesUtil.getPropString("mysql.password"));
dbConnectionPool.put(conn)
}catch {
case e : Exception => e.printStackTrace()
}
}
def getConnection(): Connection = synchronized{
while (0 == dbConnectionPool.size()){
try{
Thread.sleep(20)
}catch {
case e : InterruptedException => e.printStackTrace()
}
}
dbConnectionPool.poll()
}
/**
* 批量插入
*
* @param sqlText sql语句字符
* @param paramsList 参数列表
* @return Array[Int]
*/
def doBatch(sqlText: String, paramsList: ListBuffer[ParamsList]): Array[Int] = {
val conn: Connection = getConnection()
var ps: PreparedStatement = null
var result: Array[Int] = null
try{
conn.setAutoCommit(false)
ps = conn.prepareStatement(sqlText)
for (paramters <- paramsList) {
paramters.params_Type match {
case "real_risk" => {
println("$$$\treal_risk\t" + paramsList)
// // p_num, risk_rank, mor_rate, ch_mor_rate, load_time
ps.setObject(1, paramters.p_num)
ps.setObject(2, paramters.risk_rank)
ps.setObject(3, paramters.mor_rate)
ps.setObject(4, paramters.ch_mor_rate)
ps.setObject(5, paramters.load_time)
}
}
ps.addBatch()
}
result = ps.executeBatch
conn.commit()
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (ps != null) try {
ps.close()
} catch {
case e: SQLException => e.printStackTrace()
}
if (conn != null) try {
dbConnectionPool.put(conn)
} catch {
case e: InterruptedException => e.printStackTrace()
}
}
result
}
}
2.2.5 在scala源码目录下的包下编写Spark程序代码
package yore.spark
import com.alibaba.fastjson.{JSON, JSONArray, JSONObject}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable.ListBuffer
/**
*
* Created by yore on 2019/3/16 15:11
*/
object M_PolicyCreditApp {
def main(args: Array[String]): Unit = {
// 设置日志的输出级别
Logger.getLogger("org").setLevel(Level.ERROR)
val conf = new SparkConf()
.setMaster(PropertiesUtil.getPropString("spark.master"))
.setAppName(PropertiesUtil.getPropString("spark.app.name"))
// !!必须设置,否则Kafka数据会报无法序列化的错误
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
//如果环境中已经配置HADOOP_HOME则可以不用设置hadoop.home.dir
System.setProperty("hadoop.home.dir", "/Users/yoreyuan/soft/hadoop-2.9.2")
val ssc = new StreamingContext(conf, Seconds(PropertiesUtil.getPropInt("spark.streaming.durations.sec").toLong))
ssc.sparkContext.setLogLevel("ERROR")
ssc.checkpoint(PropertiesUtil.getPropString("spark.checkout.dir"))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> PropertiesUtil.getPropString("bootstrap.servers"),
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> PropertiesUtil.getPropString("group.id"),
"auto.offset.reset" -> PropertiesUtil.getPropString("auto.offset.reset"),
"enable.auto.commit" -> (PropertiesUtil.getPropBoolean("enable.auto.commit"): java.lang.Boolean)
)
val topics = Array(PropertiesUtil.getPropString("kafka.topic.name"))
val kafkaStreaming = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
kafkaStreaming.map[JSONObject](line => { // str转成JSONObject
println("$$$\t" + line.value())
JSON.parseObject(line.value)
}).filter(jsonObj =>{ // 过滤掉非 INSERT和UPDATE的数据
if(null == jsonObj || !"canal_test".equals(jsonObj.getString("database")) ){
false
}else{
val chType = jsonObj.getString("type")
if("INSERT".equals(chType) || "UPDATE".equals(chType)){
true
}else{
false
}
}
}).flatMap[(JSONObject, JSONObject)](jsonObj => { // 将改变前和改变后的数据转成Tuple
var oldJsonArr: JSONArray = jsonObj.getJSONArray("old")
val dataJsonArr: JSONArray = jsonObj.getJSONArray("data")
if("INSERT".equals(jsonObj.getString("type"))){
oldJsonArr = new JSONArray()
val oldJsonObj2 = new JSONObject()
oldJsonObj2.put("mor_rate", "0")
oldJsonArr.add(oldJsonObj2)
}
val result = ListBuffer[(JSONObject, JSONObject)]()
for(i <- 0 until oldJsonArr.size ) {
val jsonTuple = (oldJsonArr.getJSONObject(i), dataJsonArr.getJSONObject(i))
result += jsonTuple
}
result
}).filter(t => { // 过滤状态不为1的数据,和mor_rate没有改变的数据
val policyStatus = t._2.getString("policy_status")
if(null != policyStatus && "1".equals(policyStatus) && null!= t._1.getString("mor_rate")){
true
}else{
false
}
}).map(t => {
val p_num = t._2.getString("p_num")
val nowMorRate = t._2.getString("mor_rate").toDouble
val chMorRate = nowMorRate - t._1.getDouble("mor_rate")
val riskRank = gainRiskRank(nowMorRate)
// p_num, risk_rank, mor_rate, ch_mor_rate, load_time
(p_num, riskRank, nowMorRate, chMorRate, new java.util.Date)
}).foreachRDD(rdd => {
rdd.foreachPartition(p => {
val paramsList = ListBuffer[ParamsList]()
val jdbcWrapper = JDBCWrapper.getInstance()
while (p.hasNext){
val record = p.next()
val paramsListTmp = new ParamsList
paramsListTmp.p_num = record._1
paramsListTmp.risk_rank = record._2
paramsListTmp.mor_rate = record._3
paramsListTmp.ch_mor_rate = record._4
paramsListTmp.load_time = record._5
paramsListTmp.params_Type = "real_risk"
paramsList += paramsListTmp
}
/**
* VALUES(p_num, risk_rank, mor_rate, ch_mor_rate, load_time)
*/
val insertNum = jdbcWrapper.doBatch("INSERT INTO real_risk VALUES(?,?,?,?,?)", paramsList)
println("INSERT TABLE real_risk: " + insertNum.mkString(", "))
})
})
ssc.start()
ssc.awaitTermination()
}
def gainRiskRank(rate: Double): String = {
var result = ""
if(rate>=0.75 && rate<0.8){
result = "R1"
}else if(rate >=0.80 && rate<=1){
result = "R2"
}else{
result = "G1"
}
result
}
}
/**
* 结果表对应的参数实体对象
*/
class ParamsList extends Serializable{
var p_num: String = _
var risk_rank: String = _
var mor_rate: Double = _
var ch_mor_rate: Double = _
var load_time:java.util.Date = _
var params_Type : String = _
override def toString = s"ParamsList($p_num, $risk_rank, $mor_rate, $ch_mor_rate, $load_time)"
}
3. 测试
启动 ZK、Kafka、Canal。 在 canal_test 库下的 policy_cred 表中插入或者修改数据, 然后查看 real_result 库下的 real_risk 表中结果。 更新一条数据时Kafka接收到的json数据如下(这是canal投送到Kafka中的数据格式,包含原始数据、修改后的数据、库名、表名等信息):
{
"data": [
{
"p_num": "1",
"policy_status": "1",
"mor_rate": "0.8800",
"load_time": "2019-03-17 12:54:57"
}
],
"database": "canal_test",
"es": 1552698141000,
"id": 10,
"isDdl": false,
"mysqlType": {
"p_num": "varchar(22)",
"policy_status": "varchar(2)",
"mor_rate": "decimal(20,4)",
"load_time": "datetime"
},
"old": [
{
"mor_rate": "0.5500"
}
],
"sql": "",
"sqlType": {
"p_num": 12,
"policy_status": 12,
"mor_rate": 3,
"load_time": 93
},
"table": "policy_cred",
"ts": 1552698141621,
"type": "UPDATE"
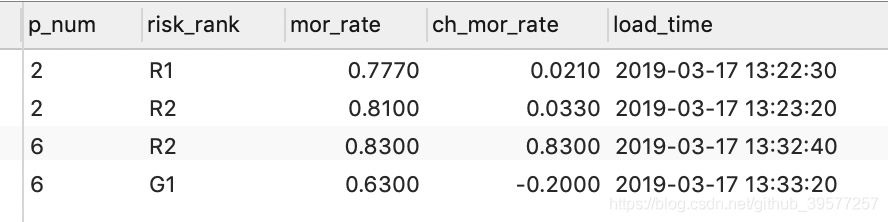
}查看Mysql中的结果表
4、出现的问题
在开发Spark代码是有时项目可能会引入大量的依赖包,依赖包之间可能就会发生冲突,比如发生如下错误:
Exception in thread "main" java.lang.NoSuchMethodError: io.netty.buffer.PooledByteBufAllocator.<init>(ZIIIIIIIZ)V
at org.apache.spark.network.util.NettyUtils.createPooledByteBufAllocator(NettyUtils.java:120)
at org.apache.spark.network.client.TransportClientFactory.<init>(TransportClientFactory.java:106)
at org.apache.spark.network.TransportContext.createClientFactory(TransportContext.java:99)
at org.apache.spark.rpc.netty.NettyRpcEnv.<init>(NettyRpcEnv.scala:71)
at org.apache.spark.rpc.netty.NettyRpcEnvFactory.create(NettyRpcEnv.scala:461)
at org.apache.spark.rpc.RpcEnv$.create(RpcEnv.scala:57)
at org.apache.spark.SparkEnv$.create(SparkEnv.scala:249)
at org.apache.spark.SparkEnv$.createDriverEnv(SparkEnv.scala:175)
at org.apache.spark.SparkContext.createSparkEnv(SparkContext.scala:257)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:424)
at org.apache.spark.streaming.StreamingContext$.createNewSparkContext(StreamingContext.scala:838)
at org.apache.spark.streaming.StreamingContext.<init>(StreamingContext.scala:85)
at yore.spark.M_PolicyCreditApp$.main(M_PolicyCreditApp.scala:33)
at yore.spark.M_PolicyCreditApp.main(M_PolicyCreditApp.scala)我们可以在项目的根目录下的命令窗口中输人:mvn dependency:tree -Dverbose> dependency.log
然后可以在项目根目录下生产一个dependency.log文件,查看这个文件,在文件中搜索 io.netty 关键字,找到其所在的依赖包:
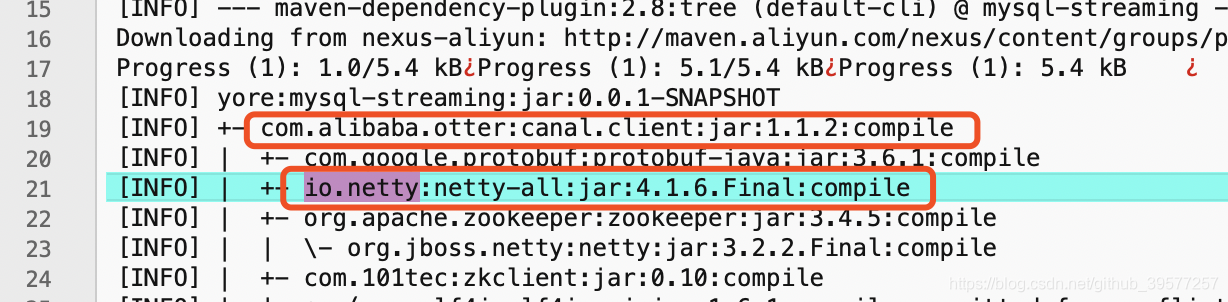
然就在canal.client将io.netty排除掉
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>${canal.client.version}</version>
<exclusions>
<exclusion>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
</exclusion>
</exclusions>
</dependency>查看项目完整代码可访问我的GitHub上这个项目的连接: 「基于Spark Streaming + Canal + Kafka对Mysql增量数据实时进行监测分析」
