原博文地址https://blog.csdn.net/erfucun/article/details/52275369
本博文主要包括一下内容:
1,SparkStreaming on Kafka Direct工作原理机制2,SparkStreaming on Kafka Direct 案例实战
3,SparkStreaming on Kafka Direct源码解析
一:SparkStreaming on Kafka Direct工作原理机制:
1、Direct方式特点:
(1)Direct的方式是会直接操作kafka底层的元数据信息,这样如果计算失败了,可以把数据重新读一下,重新处理。即数据一定会被处理。拉数据,是RDD在执行的时候直接去拉数据。
(2)由于直接操作的是kafka,kafka就相当于你底层的文件系统。这个时候能保证严格的事务一致性,即一定会被处理,而且只会被处理一次。而Receiver的方式则不能保证,因为Receiver和ZK中的数据可能不同步,spark Streaming可能会重复消费数据,这个调优可以解决,但显然没有Direct方便。而Direct api直接是操作kafka的,spark streaming自己负责追踪消费这个数据的偏移量或者offset,并且自己保存到checkpoint,所以它的数据一定是同步的,一定不会被重复(这个地方要自己定义保存checkpoint的方法)。即使重启也不会重复,因为checkpoint了,但是程序升级的时候,不能读取原先的checkpoint,面对升级checkpoint无效这个问题,怎么解决呢?升级的时候读取我指定的备份就可以了,即手动的指定checkpoint也是可以的,这就再次完美的确保了事务性,有且仅有一次的事务机制。那么怎么手动checkpoint呢?构建SparkStreaming的时候,有getorCreate这个api,它就会获取checkpoint的内容,具体指定下这个checkpoint在哪就好了。或者如下:
private static JavaStreamingContext createContext(
String checkpointDirectory, SparkConf conf) {
// TODO Auto-generated method stub
System.out.println("Creating new context");
SparkConf sparkConf = conf;
JavaStreamingContext ssc = new JavaStreamingContext(sparkConf,Durations.seconds(5));
ssc.checkpoint(checkpointDirectory);
return ssc;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
而如果从checkpoint恢复后,如果数据累积太多处理不过来,怎么办?1)限速2)增强机器的处理能力3)放到数据缓冲池中。
(3)由于底层是直接读数据,没有所谓的Receiver,直接是周期性(Batch Intervel)的查询kafka,处理数据的时候,我们会使用基于kafka原生的Consumer api来获取kafka中特定范围(offset范围)中的数据。这个时候,Direct Api访问kafka带来的一个显而易见的性能上的好处就是,如果你要读取多个partition,Spark也会创建RDD的partition,这个时候RDD的partition和kafka的partition是一致的。而Receiver的方式,这2个partition是没任何关系的。这个优势是你的RDD,其实本质上讲在底层读取kafka的时候,kafka的partition就相当于原先hdfs上的一个block。这就符合了数据本地性。RDD和kafka数据都在这边。所以读数据的地方,处理数据的地方和驱动数据处理的程序都在同样的机器上,这样就可以极大的提高性能。不足之处是由于RDD和kafka的patition是一对一的,想提高并行度就会比较麻烦。提高并行度还是repartition,即重新分区,因为产生shuffle,很耗时。这个问题,以后也许新版本可以自由配置比例,不是一对一。因为提高并行度,可以更好的利用集群的计算资源,这是很有意义的。
(4)不需要开启wal机制,从数据零丢失的角度来看,极大的提升了效率,还至少能节省一倍的磁盘空间。从kafka获取数据,比从hdfs获取数据,因为zero copy的方式,速度肯定更快。
2、SparkStreaming on Kafka Direct与Receiver 的对比:
从高层次的角度看,之前的和Kafka集成方案(reciever方法)使用WAL工作方式如下:
1)运行在Spark workers/executors上的Kafka Receivers连续不断地从Kafka中读取数据,其中用到了Kafka中高层次的消费者API。
2)接收到的数据被存储在Spark workers/executors中的内存,同时也被写入到WAL中。只有接收到的数据被持久化到log中,Kafka Receivers才会去更新Zookeeper中Kafka的偏移量。
3)接收到的数据和WAL存储位置信息被可靠地存储,如果期间出现故障,这些信息被用来从错误中恢复,并继续处理数据。 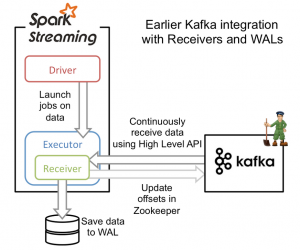
这个方法可以保证从Kafka接收的数据不被丢失。但是在失败的情况下,有些数据很有可能会被处理不止一次!这种情况在一些接收到的数据被可靠地保存到WAL中,但是还没有来得及更新Zookeeper中Kafka偏移量,系统出现故障的情况下发生。这导致数据出现不一致性:Spark Streaming知道数据被接收,但是Kafka那边认为数据还没有被接收,这样在系统恢复正常时,Kafka会再一次发送这些数据。
这种不一致产生的原因是因为两个系统无法对那些已经接收到的数据信息保存进行原子操作。为了解决这个问题,只需要一个系统来维护那些已经发送或接收的一致性视图,而且,这个系统需要拥有从失败中恢复的一切控制权利。基于这些考虑,社区决定将所有的消费偏移量信息只存储在Spark Streaming中,并且使用Kafka的低层次消费者API来从任意位置恢复数据。
为了构建这个系统,新引入的Direct API采用完全不同于Receivers和WALs的处理方式。它不是启动一个Receivers来连续不断地从Kafka中接收数据并写入到WAL中,而且简单地给出每个batch区间需要读取的偏移量位置,最后,每个batch的Job被运行,那些对应偏移量的数据在Kafka中已经准备好了。这些偏移量信息也被可靠地存储(checkpoint),在从失败中恢复可以直接读取这些偏移量信息。

需要注意的是,Spark Streaming可以在失败以后重新从Kafka中读取并处理那些数据段。然而,由于仅处理一次的语义,最后重新处理的结果和没有失败处理的结果是一致的。
因此,Direct API消除了需要使用WAL和Receivers的情况,而且确保每个Kafka记录仅被接收一次并被高效地接收。这就使得我们可以将Spark Streaming和Kafka很好地整合在一起。总体来说,这些特性使得流处理管道拥有高容错性,高效性,而且很容易地被使用。
二、SparkStreaming on Kafka Direct 案例实战:
1、源码信息如下:
package com.dt.spark.SparkApps.sparkstreaming;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaPairInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.KafkaUtils;
import kafka.serializer.StringDecoder;
import scala.Tuple2;
public class SparkStreamingOnKafkaDirect {
public static void main(String[] args) {
/* 第一步:配置SparkConf:
1,至少两条线程因为Spark Streaming应用程序在运行的时候至少有一条线程用于
不断地循环接受程序,并且至少有一条线程用于处理接受的数据(否则的话有线程用于处理数据,随着时间的推移内存和磁盘都会
不堪重负)
2,对于集群而言,每个Executor一般肯定不止一个线程,那对于处理SparkStreaming
应用程序而言,每个Executor一般分配多少Core比较合适?根据我们过去的经验,5个左右的Core是最佳的
(一个段子分配为奇数个Core表现最佳,例如3个,5个,7个Core等)
*/
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("SparStreamingOnKafkaReceiver");
/* SparkConf conf = new SparkConf().setMaster("spark://Master:7077").setAppName("SparStreamingOnKafkaReceiver");
第二步:创建SparkStreamingContext,
1,这个是SparkStreaming应用春香所有功能的起始点和程序调度的核心
SparkStreamingContext的构建可以基于SparkConf参数也可以基于持久化的SparkStreamingContext的内容
来恢复过来(典型的场景是Driver崩溃后重新启动,由于SparkStreaming具有连续7*24
小时不间断运行的特征,所以需要Driver重新启动后继续上一次的状态,此时的状态恢复需要基于曾经的Checkpoint))
2,在一个Sparkstreaming 应用程序中可以创建若干个SparkStreaming对象,使用下一个SparkStreaming
之前需要把前面正在运行的SparkStreamingContext对象关闭掉,由此,我们获取一个重大的启发
我们获得一个重大的启发SparkStreaming也只是SparkCore上的一个应用程序而已,只不过SparkStreaming框架想运行的话需要
spark工程师写业务逻辑
*/
@SuppressWarnings("resource")
JavaStreamingContext jsc = new JavaStreamingContext(conf,Durations.seconds(10));
/* 第三步:创建SparkStreaming输入数据来源input Stream
1,数据输入来源可以基于File,HDFS,Flume,Kafka-socket等
2,在这里我们指定数据来源于网络Socket端口,SparkStreaming连接上该端口并在运行时候一直监听
该端口的数据(当然该端口服务首先必须存在,并且在后续会根据业务需要不断地数据产生当然对于SparkStreaming
应用程序的而言,有无数据其处理流程都是一样的);
3,如果经常在每个5秒钟没有数据的话不断地启动空的Job其实会造成调度资源的浪费,因为并没有数据发生计算
所以实际的企业级生成环境的代码在具体提交Job前会判断是否有数据,如果没有的话就不再提交数据
在本案例中具体参数含义:
第一个参数是StreamingContext实例,
第二个参数是zookeeper集群信息(接受Kafka数据的时候会从zookeeper中获取Offset等元数据信息)
第三个参数是Consumer Group
第四个参数是消费的Topic以及并发读取Topic中Partition的线程数
*/
Map<String,String> kafkaParameters = new HashMap<String,String>();
kafkaParameters.put("meteadata.broker.list",
"Master:9092;Worker1:9092,Worker2:9092");
Set<String> topics =new HashSet<String>();
topics.add("SparkStreamingDirected");
JavaPairInputDStream<String,String> lines = KafkaUtils.createDirectStream(jsc,
String.class, String.class,
StringDecoder.class, StringDecoder.class,
kafkaParameters,
topics);
/*
* 第四步:接下来就像对于RDD编程一样,基于DStream进行编程!!!原因是Dstream是RDD产生的模板(或者说类
* ),在SparkStreaming发生计算前,其实质是把每个Batch的Dstream的操作翻译成RDD的操作
* 对初始的DTStream进行Transformation级别处理
* */
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<Tuple2<String, String>,String>(){ //如果是Scala,由于SAM装换,可以写成val words = lines.flatMap{line => line.split(" ")}
@Override
public Iterable<String> call(Tuple2<String,String> tuple) throws Exception {
return Arrays.asList(tuple._2.split(" "));//将其变成Iterable的子类
}
});
// 第四步:对初始DStream进行Transformation级别操作
//在单词拆分的基础上对每个单词进行实例计数为1,也就是word => (word ,1 )
JavaPairDStream<String,Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word,1);
}
});
//对每个单词事例技术为1的基础上对每个单词在文件中出现的总次数
JavaPairDStream<String,Integer> wordsCount = pairs.reduceByKey(new Function2<Integer,Integer,Integer>(){
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
// TODO Auto-generated method stub
return v1 + v2;
}
});
/*
* 此处的print并不会直接出发Job的支持,因为现在一切都是在SparkStreaming的框架控制之下的
* 对于spark而言具体是否触发真正的JOb运行是基于设置的Duration时间间隔的
* 诸位一定要注意的是Spark Streaming应用程序要想执行具体的Job,对DStream就必须有output Stream操作
* output Stream有很多类型的函数触发,类print,savaAsTextFile,scaAsHadoopFiles等
* 其实最为重要的一个方法是foreachRDD,因为SparkStreaming处理的结果一般都会放在Redis,DB
* DashBoard等上面,foreach主要就是用来完成这些功能的,而且可以自定义具体的数据放在哪里!!!
* */
wordsCount.print();
// SparkStreaming 执行引擎也就是Driver开始运行,Driver启动的时候位于一条新线程中的,当然
// 其内部有消息接受应用程序本身或者Executor中的消息
jsc.start();
jsc.close();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
接下来的步骤为:
(1)首先在安装了zookeeper机器上的bin目录下启动zookeeper服务:
(2)接下来在各个机器上启动Kafka服务,在Kafkabin目录下:
1) nohup ./kafka-server-start.sh ../config/server.properties &
2) ./kafka-topic.sh –create –zookeeper Master:2181,Worker1:2181,Worker2:2181 –replication-factor 3 –pertitions 1 –topic SaprkStreamingDirected
3)./kafka -console -producer.sh –broker-list Master:9092,Worker1:9092,Worker2:9092 –topic SparkStreamingDirected
(3)在控制台上输入数据
(4)此时你就可以在eclipse控制台上观察到值
三、SparkStreaming on Kafka Direct源码解析
1、首先我们在KafkaUtils中看到createDirectStream的源码注释写的非常的纤细,主要包括你可以访问offset,怎样访问offset,通过foreach暴露我们需要的RDD等等
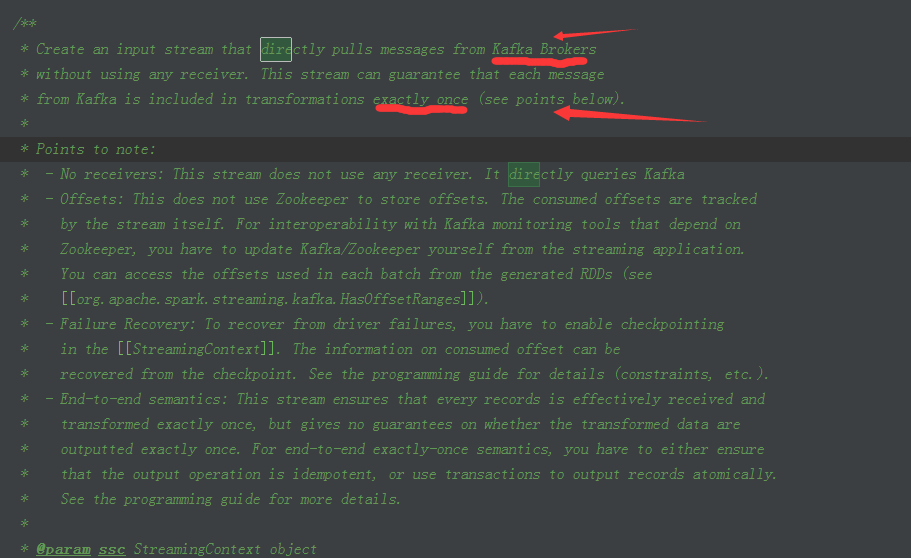
2、在这里我们可以看到各个参数信息说明的非常详细:

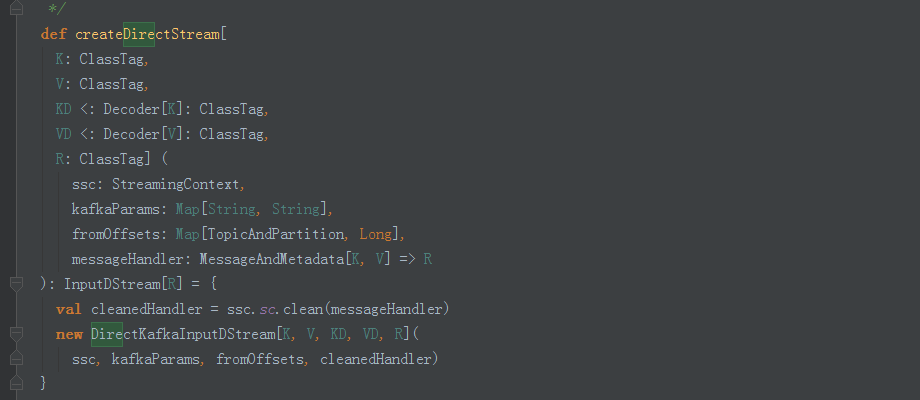
3、我们看到创建了DirectKafkaInputStream
4、在DirectKafakaInputStream中我们可以看到它创建了DirectKafkaInputDStreamcheckpointData:
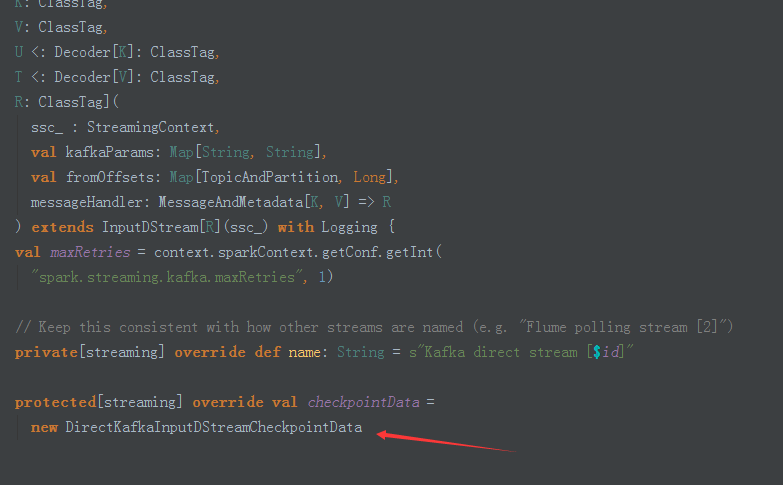
5、通过DirectKafkaInputDStreamcheckpointData,这里我们可以看到,我们可以自定义checkpoint:

更多源码希望大家自己去看。
补充说明:
使用Spark Streaming可以处理各种数据来源类型,如:数据库、HDFS,服务器log日志、网络流,其强大超越了你想象不到的场景,只是很多时候大家不会用,其真正原因是对Spark、spark streaming本身不了解。