访问flyai.club,一键创建你的人工智能项目
作者 | 程序猿tx
https://juejin.im/post/5af7ef69f265da0b9b0769cb
当年的我还是那么风华正茂、幽默风趣...
言归正传,本次使用的是
selenium模拟登录+BeautifulSoup4爬取数据+wordcloud生成词云图
BeautifulSoup安装
pip install beautifulsoup4
下表列出了主要的解析器,以及它们的优缺点:
selenium模拟登录
使用selenium模拟登录QQ空间,安装pip install selenium
我用的是chrom浏览器,webdriver.Chrome(),获取Chrome浏览器的驱动。
这里还需要下载安装对应浏览器的驱动,否则在运行脚本时,会提示chromedriver executable needs to be in PATH错误,用的是mac,网上找的一篇下载驱动的文章,https://blog.csdn.net/zxy987872674/article/details/53082896
同理window的也一样,下载对应的驱动,解压后,将下载的**.exe 放到Python的安装目录,例如 D:\python 。 同时需要将Python的安装目录添加到系统环境变量里。
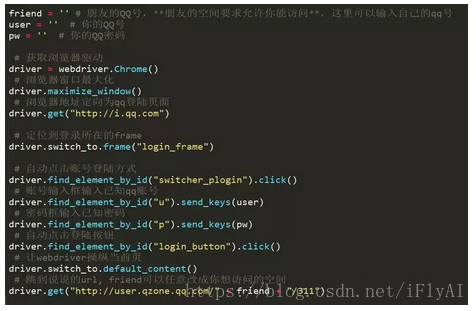
qq登录页http://i.qq.com,利用webdriver打开qq空间的登录页面
driver = webdriver.Chrome()
driver.get("http://i.qq.com")
打开之后右击检查查看页面元素,发现帐号密码登录在login_frame里,先定位到所在的frame,driver.switch_to.frame("login_frame") ,再自动点击 帐号密码登录 按钮,自动输入帐号密码登录,并且打开说说页面,详细代码如下
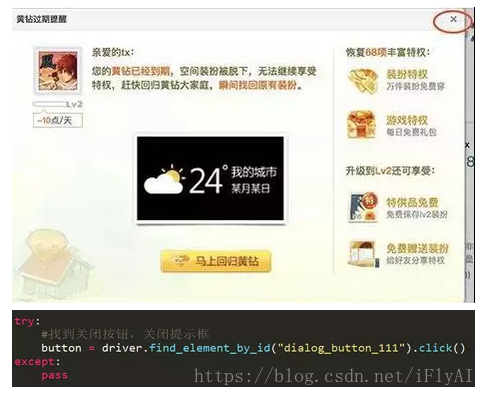
这个时候可以看到已经打开了qq说说的页面了,注意 部分空间打开之后会出现一个提示框,需要先模拟点击事件关闭这个提示框
同时因为说说内容是动态加载的,需要自动下拉滚动条,加载出全部的内容,再模拟点击 下一页 加载内容。
BeautifulSoup爬取说说
F12查看内容,可以找到说说在feed_wrap这个<div>,<ol>里面的<li>标签数组里面,具体每条说说内容在<div> class="bd"的<pre>标签中。
至此QQ说说已经爬取下来,并且保存在了qq_word文件里
词云图
使用wordcloud包生成词云图,
pip install wordcloud
这里还可以使用jieba分词,我并没有使用,因为我觉得qq说说的句子读起来才有点感觉,个人喜好,用jieba分词可以看到说说高频次的一些词语。
设置下wordcloud的一些属性,注意 这里要设置font_path属性,否则汉字会出现乱码。
这里还有个要提醒的是,如果使用了虚拟环境的,不要在虚拟环境下运行以下脚本,否则可能会报错
我就遇到了这种情况,deactivate 退出了虚拟环境再跑的
至此,爬取qq说说内容,并生成词云图。
— End —