【2019.05】python 爬取Bilibili弹幕【大碗宽面】
- 大碗宽面 bilibili地址
https://www.bilibili.com/video/av49775093?from=search&seid=17341565034802837057
Chrome 调试找到弹幕url和cid
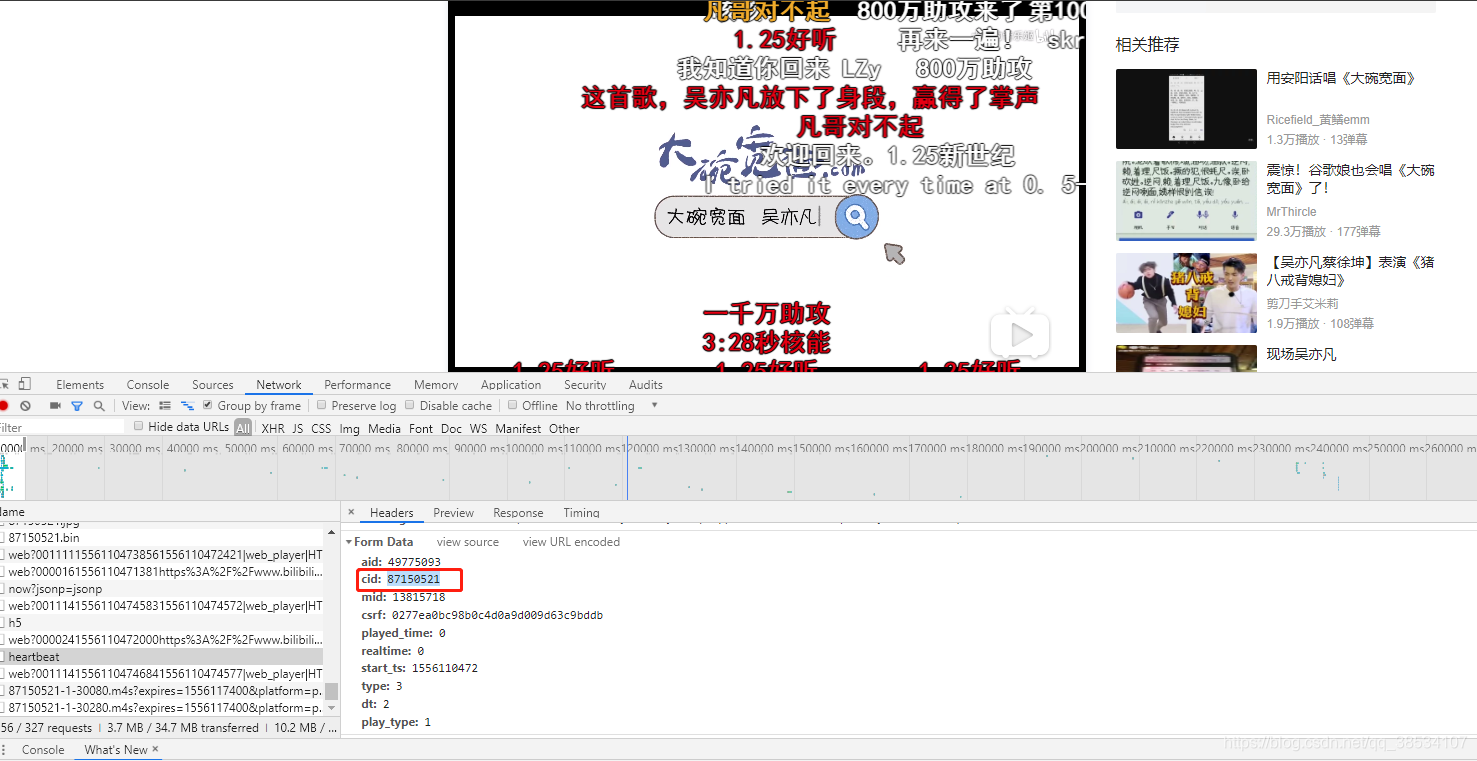
得到弹幕连接
http://comment.bilibili.com/87150521.xml
访问该链接可看到1000条弹幕数据,暂且就1000条吧,之后发现新的弹幕api再看看。

编码实现,将弹幕数据保存至本地csv文件中
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/4/24 21:06
# @Author : Paulson
# @File : 大碗宽面.py
# @Software: PyCharm
# @define : function
import requests
from bs4 import BeautifulSoup
import pandas as pd
class Spider(object):
def __init__(self):
self.url = "http://comment.bilibili.com/87150521.xml"
def get_html(self):
html = requests.get(self.url).content.decode('utf-8')
return html
def parse_xml(self):
html_data = self.get_html()
soup = BeautifulSoup(html_data, 'lxml')
results = soup.find_all('d')
comments = [comment.text for comment in results]
comment_dict = {'comments': comments}
df = pd.DataFrame(comment_dict)
df.to_csv('noodles.csv', encoding='utf-8')
if __name__ == '__main__':
s = Spider()
s.parse_xml()

看来大家都在向克鲁斯吴先生道歉
接下来对数据进行初步的处理,顺便做一个词云图。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/4/24 21:33
# @Author : Paulson
# @File : 大碗宽面Analysis.py
# @Software: PyCharm
# @define : function
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
import pandas as pd
import jieba
df = pd.read_csv('noodles.csv', header=None)
text = ''
for line in df[1]:
text += ' '.join(jieba.cut(line, cut_all=False))
backgroud_Image = plt.imread('kris.png')
# font_path 字体路径,拷贝到项目路径中,或者使用绝对路径。
# 如果不适用字体,可能会导致词云图中的字显示为‘口’或‘?’
wc = WordCloud(background_color='black', font_path='simsun.ttc',
max_words=2000, max_font_size=50, random_state=50,)
wc.generate_from_text(text)
# 看看词频高的有哪些,把无用信息去除
process_word = WordCloud.process_text(wc, text)
sort = sorted(process_word.items(), key=lambda e: e[1], reverse=True)
print(sort[:50])
# img_colors = ImageColorGenerator(backgroud_Image)
# wc.recolor(color_func=img_colors)
plt.imshow(wc)
plt.axis('off')
wc.to_file("wyfciyun.jpg")
print('生成词云成功!')
打印出词频前50的词
[('这个 面它', 81), ('面它 这个', 80), ('这个 大又圆你', 46), ('大又圆你 这个', 46), ('对不起', 38), ('凡哥', 37), ('好听', 32), ('对不起凡哥', 29), ('真的', 19), ('吴亦凡', 17), ('高能 前方', 15), ('前方 高能', 14), ('了凡哥', 12), ('大又圆你 看着', 12), ('看着 面又长', 12), ('这个 大又圆', 11), ('看着 大又圆你', 11), ('可爱', 9), ('对不起1', 9), ('演唱会', 9), ('啊啊啊', 9), ('了1', 8), ('进来', 8), ('哇哇 哇哇', 8), ('面又长 宽你', 8), ('宽你 看着', 8), ('对不起你', 6), ('感觉', 6), ('大又圆凡哥', 6), ('了你', 6), ('什么', 5), ('男人', 5), ('弹幕', 5), ('大碗', 5), ('吼吼 吼吼', 5), ('实力', 4), ('每天', 4), ('不错', 4), ('好听你', 4), ('了吴亦凡', 4), ('倍速', 4), ('徐坤', 4), ('还是', 4), ('凡凡', 4), ('的凡哥', 4), ('八百万', 4), ('了800W', 4), ('对不起吴亦凡', 4), ('这歌', 4), ('隔壁', 4)]
效果如下图
