版权声明:转载请注明出处 https://blog.csdn.net/weixin_39653948/article/details/83276057
这是我之前写的日志,觉得挺有意思,发给大家看看。以下为原文:
今天从微信看到了这个有意思的demo,作者是用python2.7写的,作者只留了源码,没有配置说明。我用python3.6跑,结果报了一大堆错误,主要问题是编码问题,一直提示无法写入文件。尝试了很多解决方法无果,功夫不负有心人,多次调试之后…跑通了。
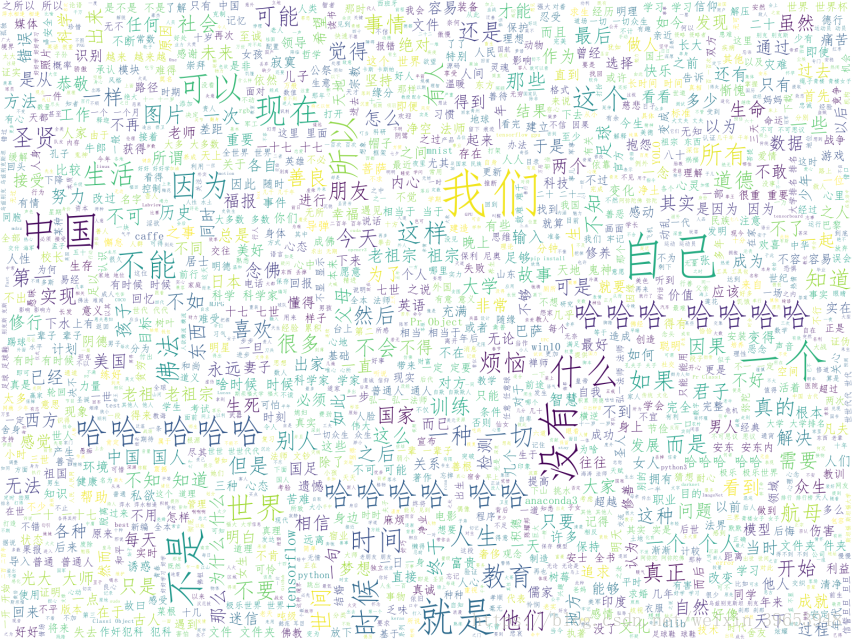
原文链接:http://mp.weixin.qq.com/s/7RjGT7vl9RsG9wac5rmhpw
1.流程:
- 安装火狐浏览器
# 打开anaconda prompt创建虚拟环境
conda create -n reptile-python python=3.6
conda install spyder
- 安装库
pip install selenium
pip install lxml
pip install wordcloud #生成词云
pip install matplotlib #生成词云图片
pip install jieba #这个库可用可不用,但因为中文一直显示不出来,加上这个库,就能显示中文。
- 遇到的错误:
1.NameError: name 'reload' is not defined
import sys
reload(sys)
改用:
import importlib
importlib.reload(sys)
2.AttributeError: module 'sys' has no attribute 'setdefaultencoding
Python3字符串默认编码unicode, 所以sys.setdefaultencoding 也不存在了
注释掉 sys.setdefaultencoding( "utf-8" ) 就好了
3.WebDriverException: 'geckodriver' executable needs to be in PATH.
如果是使用selenium3.X版本的,火狐浏览器需要网上下载geckodriver,
这给出Windows64位下载地址:https://pan.baidu.com/s/1gfP8CON,
其他系统的以及最新的geckodriver可以到:https://github.com/mozilla/geckodriver/releases下载/
在Windows下,下载好软件直接解压,然后复制geckodriver.exe(或chromedriver.exe)到任何已添加到【环境变量的文件夹】即可
我放在了创建的虚拟环境中 D:\anaconda3\envs\reptile-python
其它都是编码问题导致的:
UnicodeEncodeError: 'gbk' codec can't encode character '\u2217' in position 240: illegal multibyte sequence
解决方案:
两个脚本中的
with open('qq_word.txt','a') as f:
text= open("{}.txt".format(filename)).read()
分别修改为
with open('qq_word.txt','a',encoding='gb18030',errors='ignore') as f:
text= open("{}.txt".format(filename),encoding='gb18030',errors='ignore').read()
文件名打开错误
修改词云脚本中的
text= open("{}.txt".format(filename),encoding='gb18030',errors='ignore').read()
为
text= open("qq_word.txt".format(filename),encoding='gb18030',errors='ignore').read()
注意要在同级目录下
2.爬虫源码:
# -*- coding: utf-8 -*-
"""
Created on Thu Mar 22 22:24:56 2018
@author: chopin
"""
#coding:utf-8
import time
from selenium import webdriver
from lxml import etree
import sys
import io
import importlib
importlib.reload(sys)
friend = '' # 朋友的QQ号,朋友的空间要求允许你能访问
user = '' # 你的QQ号
pw = '' # 你的QQ密码
#获取浏览器驱动
driver = webdriver.Firefox()
# 浏览器窗口最大化
driver.maximize_window()
# 浏览器地址定向为qq登陆页面
driver.get("http://i.qq.com")
# 所以这里需要选中一下frame,否则找不到下面需要的网页元素
driver.switch_to.frame("login_frame")
# 自动点击账号登陆方式
driver.find_element_by_id("switcher_plogin").click()
# 账号输入框输入已知qq账号
driver.find_element_by_id("u").send_keys(user)
# 密码框输入已知密码
driver.find_element_by_id("p").send_keys(pw)
# 自动点击登陆按钮
driver.find_element_by_id("login_button").click()
# 让webdriver操纵当前页
driver.switch_to.default_content()
# 跳到说说的url, friend你可以任意改成你想访问的空间
driver.get("http://user.qzone.qq.com/" + friend + "/311")
next_num = 0 # 初始“下一页”的id
while True:
# 下拉滚动条,使浏览器加载出动态加载的内容,
# 我这里是从1开始到6结束 分5 次加载完每页数据
for i in range(1,6):
height = 20000*i#每次滑动20000像素
strWord = "window.scrollBy(0,"+str(height)+")"
driver.execute_script(strWord)
time.sleep(4)
# 很多时候网页由多个<frame>或<iframe>组成,webdriver默认定位的是最外层的frame,
# 所以这里需要选中一下说说所在的frame,否则找不到下面需要的网页元素
driver.switch_to.frame("app_canvas_frame")
selector = etree.HTML(driver.page_source)
divs = selector.xpath('//*[@id="msgList"]/li/div[3]')
#这里使用 a 表示内容可以连续不清空写入
with open('qq_word.txt','a',encoding='gb18030',errors='ignore') as f:
for div in divs:
qq_name = div.xpath('./div[2]/a/text()')
qq_content = div.xpath('./div[2]/pre/text()')
qq_time = div.xpath('./div[4]/div[1]/span/a/text()')
qq_name = qq_name[0] if len(qq_name)>0 else ''
qq_content = qq_content[0] if len(qq_content)>0 else ''
qq_time = qq_time[0] if len(qq_time)>0 else ''
print(qq_name,qq_time,qq_content)
f.write(qq_content+"\n")
# 当已经到了尾页,“下一页”这个按钮就没有id了,可以结束了
if driver.page_source.find('pager_next_' + str(next_num)) == -1:
break
# 找到“下一页”的按钮,因为下一页的按钮是动态变化的,这里需要动态记录一下
driver.find_element_by_id('pager_next_' + str(next_num)).click()
# “下一页”的id
next_num += 1
# 因为在下一个循环里首先还要把页面下拉,所以要跳到外层的frame上
driver.switch_to.parent_frame()
3.生成词云源码:
# -*- coding: utf-8 -*-
"""
Created on Fri Mar 23 00:55:08 2018
@author: chopin
"""
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
#生成词云
def create_word_cloud(filename):
text= open("qq_word.txt".format(filename),encoding='gb18030',errors='ignore').read()
# 结巴分词
wordlist = jieba.cut(text, cut_all=True)
wl = " ".join(wordlist)
# 设置词云
wc = WordCloud(
# 设置背景颜色
background_color="white",
# 设置最大显示的词云数
max_words=2000,
# 这种字体都在电脑字体中,一般路径
font_path='C:\Windows\Fonts\simfang.ttf',
height= 1200,
width= 1600,
# 设置字体最大值
max_font_size=100,
# 设置有多少种随机生成状态,即有多少种配色方案
random_state=30,
)
myword = wc.generate(wl) # 生成词云
# 展示词云图
plt.imshow(myword)
plt.axis("off")
plt.show()
wc.to_file('py_book.png') # 把词云保存下
if __name__ == '__main__':
create_word_cloud('word_py')