一、格式化输入与输出
- 除了条件状态之外(见:https://blog.csdn.net/qq_41453285/article/details/104527480),每个iostream对象还维护一个格式状态来控制IO如何格式化的细节。格式状态控制格式化的某些方面,如整型值是几进制、浮点值的精度、一个输出元素的宽度等
- 操纵符:
- 标准库定义了一组操纵符来改变流的格式状态
- 一个操纵符是一个函数或是一个对象,会影响流的状态,并能用作输入和输出运算符的运算对象
- 很多操纵符改变格式状态:
- 操纵符用于两大类的输出控制:控制数值的输出形式以及控制补白的数量和位置
- 大多数改变格式状态的操纵符都是设置/复原成对的:一个操纵符用来将格式状态设置为一个新的值,而另一个用来将其复原


控制布尔值的格式化(boolalpha、noboolalpha)
- boolalpha操纵符:
- 默认的情况下,bool类型的值会打印0或1。如果使用boolalpha操纵符,那么bool类型的值会被打印为true或false
- 一旦设置了boolalpha,那么后续的流都会保持这个状态
- noboolalpha操纵符:用来取消boolalpha操纵符所设置的状态
- 例如,下面boolalpha操纵符用来设置bool类型的值打印为true或false:
std::cout << "default bool values: " << true << " " << false << std::endl;
std::cout << "alpha bool values: " << boolalpha << true << " " << false << std::endl;

- 例如,下面boolalpha与noboolalpha配合使用,在单词打印中使用true或false
bool get_status()
{
return 0;
}
int main()
{
bool bool_value = get_status();
std::cout << boolalpha << bool_value << noboolalpha << std::endl;
return 0;
}
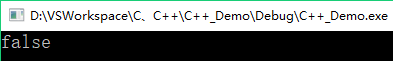
指定整型值的进制(hex、oct、dec)
- 默认情况下,整型值的输入输出使用十进制(dec操纵符)
- 可使用的操纵符如下:
- dex操纵符:将整型值改为十六进制打印
- oct操纵符:将整型值改为八进制打印
- dec操纵符:将整型值改为十进制打印(默认)
- 这些操纵符也会改变格式状态,后续的流都会保持这个状态

std::cout << "default: " << 20 << " " << 1024 << std::endl;
std::cout << "octal: " << oct << 20 << " " << 1024 << std::endl;
std::cout << "hex: " << hex << 20 << " " << 1024 << std::endl;
std::cout << "decimal: " << dec << 20 << " " << 1024 << std::endl;

在输出中指出进制(showbase、noshowbase、uppercase、nouppercase)
- 默认情况下,我们打印的数值不论是什么进制,都是为数字形式,不会有任何前导符
- showbase操纵符:
- 会在输出结果中显示进制
- 规则如下:
- 前导0x表示十六进制
- 前导0表示八进制
- 无前导符字符串表示十进制
- noshowbase操纵符:因为showbase会持久改变流的状态,因此noshowbase是用来恢复流的状态
- uppercase操纵符:在showbase的设置下,十六进制的0x中的x为小写的x,uppercase会将x改为大写的X;并且十六进制数字a-f以大写形式输出
- nouppercase操纵符:因为uppercase会持久改变流的状态,因此nouppercase是用来恢复流的状态
- 例如:
std::cout << showbase;
std::cout << "default: " << 20 << " " << 1024 << std::endl;
std::cout << "in octal: " << oct << 20 << " " << 1024 << std::endl;
std::cout << "in hex: " << hex << 20 << " " << 1024 << std::endl;
std::cout << "in decimal: " << dec << 20 << " " << 1024 << std::endl;
std::cout << noshowbase;

std::cout << showbase << uppercase << hex;
std::cout << "printed in hexadecimal: " << 20 << " " << 1024 << std::endl;
std::cout << noshowbase << nouppercase << dec;

控制浮点数格式
- 我们可以控制浮点数输出三种格式:
- ①以多高精度(多少个数字)打印浮点值
- ②数值是因为十六进制、定点十进制、还是科学记数法形式
- ③对于没有小数部分的浮点值是否打印小数点
- 默认情况下:
- 浮点值按六位数字精度打印
- 如果浮点值没有小数部分,则不打印小数点
- 根据浮点数的值选择打印成定点十进制或科学记数法形式
①指定打印精度(precision、setprecision)
- 默认情况下,精度会控制打印的数字的总数。当打印时,浮点值会按当前精度进行四舍五入的操作。例如,如果当前精度为4,则3.14159会打印为3.142
- precision函数:为IO对象的成员函数。是重载的:
- 一个版本接受一个int值,将精度设置为此值,并返回旧精度值
- 一个版本无参数,返回当前精度制
- serprecision操纵符:接受一个参数,用来设置精度


#include <iostream>
#include <iomanip> //setprecision()
using namespace std;
int main()
{
std::cout << "Precision: " << std::cout.precision() << ",Value: " << sqrt(2.0) << std::endl;
std::cout.precision(12);
std::cout << "Precision: " << std::cout.precision() << ",Value: " << sqrt(2.0) << std::endl;
std::cout << setprecision(3);
std::cout << "Precision: " << std::cout.precision() << ",Value: " << sqrt(2.0) << std::endl;
return 0;
}

②指定浮点数记数法(scientific、fixed、hexfloat、defaultfloat)

- 相关操纵符如下:
- scientific操纵符:改变流的状态来使用科学记数法
- fixed操纵符:改变流的状态来使用定点十进制
- hexfloat操纵符:强制浮点数使用十六进制
- defaultfloat操纵符:恢复到默认状态——根据要打印的值选择记数法
- 这些操纵符会改变流的精度的默认函数含义:
- 在执行scientfic、fixed、hexfloat之后,精度值控制的是小数点后面的数字位数
- 而默认情况下精度值指定的是数字的总位数——即包括小数点前面的,也包括小数点后面的
- 使用fixed和scientific令我们可以按列打印数值,因为小数点距小数部分的距离是固定的
- 默认情况下,十六进制数字和科学记数法中的e都打印成小写形式。我们可以使用uppercase操纵符(见上)来打印这些字母的大写形式
- 例如:
std::cout << "default format: " << 100 * sqrt(2.0) << '\n' ;
std::cout << "scientific: " << scientific << 100 * sqrt(2.0) << '\n';
std::cout << "fixed decimal: " << fixed << 100 * sqrt(2.0) << '\n';
std::cout << "hexadecimal: " << hexfloat << 100 * sqrt(2.0) << '\n';
std::cout << "use defaults: " << defaultfloat << 100 * sqrt(2.0) << '\n';

③打印小数点(showpoint、noshowpoint)
- 默认情况下,当一个浮点值的小数部分为0时,不显示小数点
- showpoint操纵符:强制打印小数点
- noshowpoint操纵符:恢复默认行为
- 例如:
std::cout << 10.0 << std::endl;
std::cout << showpoint << 10.0 << noshowpoint << std::endl;

输出补白(setw、left、right、internal、setfil)
- 当按列打印数据时,我们常常需要非常精细地控制数据格式
- 标准库提供了下面的操纵符来完成所需的控制:
- setw操纵符:指定下一个数字或字符串值的最小空间
- left操纵符:表示左对齐输出
- right操纵符:表示右对齐输出,右对齐是默认格式
- internal操纵符:控制负数的符号的位置,它左对齐符号,右对齐值,用空格填满所有中间空间
- setfil操纵符:允许指定一个字符代替默认的空格来补白输出

int i = -16;
double d = 3.14159;
//补白第一列,使用输出中最小12个位置
std::cout << "i: " << setw(12) << i << "next col" << '\n';
std::cout << "d: " << setw(12) << d << "next col" << "\n\n";
//补白第一列,左对齐所有列
std::cout << left << "i: " << setw(12) << i << "next col" << '\n';
std::cout << "d: " << setw(12) << d << "next col" << "\n\n";
std::cout << right; //恢复正常对齐
//补白第一列,右对齐所有列
std::cout << right << "i: " << setw(12) << i << "next col" << '\n';
std::cout << "d: " << setw(12) << d << "next col" << "\n\n";
//补白第一列,但补在域的内部
std::cout << internal << "i: " << setw(12) << i << "next col" << '\n';
std::cout << "d: " << setw(12) << d << "next col" << "\n\n";
//补白第一列,用#作为补白字符
std::cout << setfill('#') << "i: " << setw(12) << i << "next col" << '\n';
std::cout << "d: " << setw(12) << d << "next col" << "\n\n";
std::cout << setfill(' '); //恢复正常的补白字符

控制输入格式(skipws、noskipws)
- 默认情况下,输入运算符会忽略空白符(空格符、制表符、换行符、换纸符、回车符)
- skipws操纵符:输入运算符忽略空白符(默认采用)
- noskipws操纵符:令输入运算符读取空白符
- 例如:
//输入a b c,那么while会循环3次,读取abc,跳过中间的空白字符
char ch;
while (std::cin >> ch)
std::cout << ch;

//输入a b c,那么while会循环8次,读取abc和中间的空白符
char ch;
std::cin >> noskipws;
while (std::cin >> ch)
std::cout << ch;
std::cin >> skipws;

二、未格式化的输入/输出操作
- 上面介绍的都是格式化IO操作。标准库还提供了一些底层操作,支持未格式化IO操作,这些操作允许我们将一个流当作一个无解释的字节序列来处理
单字节操作
- 这几个操作每次一个字节地处理流
- 例如,我们使用get和put来读取和写入一个字符,下面的代码会保留输入中的空白符(与设置noskipws操纵符功能一样)
char ch;
while (std::cin.get(ch))
std::cout.put(ch);


将字符放回输入流(peek、unget、putback)
- 有时我们需要读取一个字符才能知道还未准备处理它。在这种情况下我们希望将字符放回流中
- 标准库提供了三种方法退回字符,差别如下:
- peek:返回输入流中下一个字符的副本,但不会将它从流中删除,peek返回的值仍然保留在流中
- unget:使得输入流向后移动,从而最后读取的值又回到流中。即使我们不知道最后从流中读取什么值,仍然可以调用unget
- putback:更特殊版本的unget;它退回从流中读取的最后一个值,但它接受一个参数,此参数必须与最后读取的值相同
- 一般情况下,在读取下一个值之前,标准库保证我们可以退回最多一个值。即,标准库不保证在中间不进行读取操作的情况下能连续调用putback或unget
从输入操作返回的int值(peek、get())
- 函数peek和无参的get版本都以int类型从输入流返回一个字符。这有些令人吃惊,可能这些函数返回一个char看起来会自然一些
- 这些函数返回int的原因:可以返回文件尾标记。我们使用char范围中的每个值来表示一个真实字符,因此,取值范围中没有额外的值可以用来表示文件尾
- 返回int的函数将它们要返回的字符先转换为unsigned char,然后再将结果提升到int:
- 因此,即使字符集中有字符映射到负值,这些操作返回的int也是正值。而标准库使用负值表示文件尾,这样就可以保证与任何合法字符的值都不同
- 头文件cstdio定义了一个名为ROF的const,我们可以用它检测从get返回的值是否到达文件尾。例如:
char ch;
//循环读取,到达文件尾之后结束循环
while ((ch = std::cin.get()) != EOF)
std::cout.put(ch);
多字节操作
- 一些未格式化IO一次处理大块数据。如果速度是要考虑的问题,那么这些操作很重要,但类似其他底层操作,这些操作也很容易出错

- get()和getline()函数接受相同的参数,但是它们的行为却不相同。在两个函数中,sink参数都是一个char数组,用来保存数据,两个函数都一直读取数据,直至下面的条件之一发生:
- 已读取size-1个字符
- 遇到了文件尾
- 遇到了分隔符
- 两个函数的差别是处理分隔符的方式:
- get将分隔符留作istream中的下一个字符
- getline则读取并丢弃分隔符
- 无论哪个函数都不会将分隔符保存在sink中

确定读取了多少个字符(gcount)
- 某些操作从输入读取未知个数的字符。我们可以调用gcount来确定最后一个未格式化输入操作读取了多少个字符
- 应该在任何后续未格式化输入操作之前调用gcount。特别是,将字符退回流的单字符操作也属于未格式化输入操作
- 如果在调用gcount之前调用peek、unget或putback,则gcount的返回值为0

三、流随机访问
- 各种流类型通常都支持对流中数据的随机访问。标准库提供了一对函数,来定位(seek)到流中给定的位置,以及高度(tell)我们当前位置

- 虽然标准库为所有流类型都定义了seek和tell函数,但是它们是否会做有意义的事情依赖于流绑定到哪个设备(控制台、文件还是string)。在大多数系统中,绑定到cin、cout、cerr、clog的流不支持随机访问,在运行时对这些流调用seek和tell函数会出错,将流置于一个无效状态
- 因此,下面讨论的内容只适用于fstream和sstream类型
seek和tell函数
- 为了支持随机访问,IO类型维护一个标记来确定下一个读写操作要在哪里进行
- seek:将标记定位到给定位置
- tell:返回标记的当前位置
- 每个函数有两个版本:一对用于输入流(函数名以g结尾),一对用于输出流(函数名以p结尾)
- 因此:
- 因为ifstream和istringstream继承于istream,所以ifstream和istringstream只能使用g版本
- 因为ofstream和ostringstream继承于ostream,所以ofstream和ostringstream只能使用p版本
- 因为fstream和stirngstream继承于iostream,所以fstream和stirngstream既可以使用g版本也可以使用p版本

只有一个标记
- 标准库区分seek和tell函数的“放置”和“获得”这一特性可能会导致误解。即使标准库进行了区分,但它在一个流中值维护单一的标记——并不存在独立的读标记和写标记:
- 当我们处理一个只读或只写的流时,两种版本的区别不是很明显。因为它们只能单独使用p和g版本的函数
- fstream和stringstream类型既可以写也可以读,但是,在这两种类型中,标记也是唯一的

重定位标记(seek)
- seek函数有两个版本:
- 一个版本移动到文件中的“绝对”地址
- 另一个版本移动到一个给定位置的指定偏移量
- new_position参数和offset参数的数据类型分别为pos_type和off_type,这两个数据类型都是机器相关的,分别定义在头文件istream和ostream中
- pos_type:表示一个文件位置
- off_type:表示距当前位置的一个偏移量(既可以是正也可以是负值)

访问标记
- 函数tellg和tellp返回一个pos_type值,表示流的当前位置
- tell函数通常用来记住一个位置,以便稍后再定位回来:
std::ostringstream writeStr;
std::ostringstream::pos_type mark = writeStr.tellp();//记住当前写位置
//...一些列操作
//操作完成之后回到最初的位置
if (cancelEntry)
writeStr.seekp(mark);
读写同一文件
- 下面是一个演示案例,我们读取一个文件,然后在文件末尾加上新的一行,这一行包含每行的相对起始位置
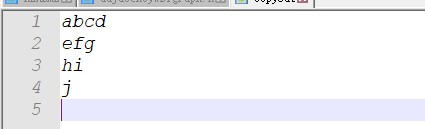
- 例如(其中包含换行符):

- 下面是代码,程序逐行读取文件,对每一行,我们将递增技术器,将刚刚读取的一行长度加到计数器上:
#include <iostream>
#include <string>
#include <fstream>
#include <sstream>
#include <vector>
#include <iomanip>
using namespace std;
int main()
{
//打开一个文件
fstream inOut("copyOut", fstream::ate | fstream::in | fstream::out);
if (!inOut) {
std::cerr << "Unable to open file!" << std::endl;
return EXIT_FAILURE;
}
auto end_mark = inOut.tellg(); //打开文件之后,光标位于文件末尾,此处记住文件尾位置
inOut.seekg(0, fstream::beg); //将光标的移动到文件最开始
size_t cnt = 0; //字节数累加器
string line; //保存一行数据
while ((inOut) && (inOut.tellg() != end_mark) && getline(inOut, line))
{
cnt += line.size() + 1; //累加器数值,1代表换行符
auto mark = inOut.tellg(); //重新记录当前光标位置
inOut.seekp(0, fstream::end); //移动到文件尾部
inOut << cnt; //将数值写入
if (mark != end_mark) //如果不是最后一行,打印一个分隔符
inOut << " ";
inOut.seekg(mark); //恢复读位置
}
//定位到文件尾部,写入一个换行符
inOut.seekp(0, fstream::end);
inOut << "\n";
return 0;
}