标准库特殊设施
1 tuple类型
tuple是类似pair的模板,不同tuple类型的成员类型也不相同,但一个tuple可以有任意数量的成员
| 操作 | 描述 |
|---|---|
tuple<T1, T2, ..., Tn> t; |
t是一个tuple,成员数为n,第i个成员的类型为Ti |
tuple<T1, T2, ..., Tn> t(v1, v2, ..., vn); |
t是一个tuple,成员类型为T1...Tn,每个成员用对应的初始化vi进行初始化 |
make_tuple(v1,v2, ...,vn) |
返回一个用给定初始值初始化的tuple。tuple的类型从初始值的类型推断 |
t1 == t2 |
当两个tuple具有相同数量的成员且成员对应相等时,两者相等 |
t1 != t2 |
只要有一个成员不等,就停止比较 |
t1 relop t2 |
tuple的关系运算使用字典序,两个tuple必须具有相同数量的成员。使用<运算符比较t1的成员和t2中的成员 |
get<i> (t) |
返回t的第i个数据成员的引用,tuple的所有成员都是public |
tuple_size<tupleType>::value |
一个类模板,可以通过一个tuple类型来初始化。其有一个名为value的public constexpr static数据成员,类型为size_t,表示给定tuple类型中成员的数量 |
tuple_element<i, tupleType>::type |
一个类模板,可以通过一个整型常量和一个tuple类型来初始化。其有一个名为type的public成员,表示给定tuple类型中指定成员的类型 |
1.1 定义和初始化tuple
当定义一个tuple时,需要指出每个成员的类型:
tuple<size_t, size_t, size_t> threeD; //三个成员都设置为0
tuple<string, vector<double>, int, list<int>>
someVal("constants", {3.14, 2.718}, 42, {0,1,2,3,4,5})
tuple的这个构造函数是explicit的,因此必须使用直接初始化语法:
tuple<size_t, size_t, size_t> threeD{1,2,3}; //三个成员都设置为0
访问tuple的成员
要访问tuple的成员,使用一个名为get的标准库函数模板,同时传递给get一个tuple对象,其返回指定成员的引用:
auto book = get<0>(item); //返回item的第一个成员
auto book = get<1>(item); //返回item的第二个成员
auto book = get<2>(item)/cnt; //返回item的最后一个成员
get<2>(item) *= 0.8; //打折20%
注意:尖括号中的值必须是一个整型常量表达式,从0开始计数,意味着get<0>是第一个成员。
2 bitset类型
2.1 定义和初始化bitset
标准库定义bitset类,使得位运算的使用更为容易,其定义在头文件bitset中。
bitset类是一个类模板,类似array类,具有固定的大小,因此当定义一个bitset时,需要声明其包含多少个二进制位:
bitset<32> bitvec(1U); //32位;低位为1,其他位为0
大小必须是一个常量表达式。其中编号从0开始的二进制位被称为低位,编号到31结束的二进制位被称为高位
| 操作 | 说明 |
|---|---|
bitset<n> b; |
b有n位;每位均为0,此构造函数是一个constexpr |
bitset<n> b(u); |
b是unsigned long long值u的低n位的拷贝,若n超出类型范围,则b中超出类型的高位被置0 |
bitset<n> b(s, pos, m, zero, one); |
b是string从位置pos开始m个字符的拷贝。s只能包含字符zero或one;如果s包含任何其他字符,构造函数会抛出invalid——argument异常。 |
bitset<n> b(cp, pos, zero, one); |
与是一个函数相同,但从cp指向的字符数组中拷贝字符。若未提供m,则cp必须指向一个C风格字符串。若提供了m,则从cp开始必须至少有m个zero或one字符 |
接受一个string或一个字符指针的构造函数是explicit。
用unsigned值初始化bitset
当使用一个整型值来初始化bitset时,此值将被转换为unsigned long long类型并被当作位模式来处理。若bitset的大小大于一个unsigned long long中的二进制位数,则剩余的高位被置为0。若bitset的大小小于一个unsigned long long中的二进制位数,则只使用给定值中的低位,超出bitset大小的高位被丢弃:
//bitvecl比初始值小;初始值中的高位被丢弃
bitset<13> bitvecl1(0xbeef); //二进制位序列为1 1110 1110 1111
//bitvec2比初始值大;它的高位被置为0
bitset<20> bitvecl1(0xbeef); //二进制位序列为0000 1011 1110 1110 1111
//在64位机器中,long long 0ULL是个64个0比特,故~0ULL是64个1
bitset<128> bitvecl1(~0ULL); //0~63位为1;63~127位为0
从一个string初始化bitset
可以从一个string或一个字符数组指针来初始化bitset。两种情况下,字符都直接表示位模式。其中字符串中下标最小的字符对应高位。
bitset<32> bitvec("1100"); //2、3两位为1,剩余两位为0
如果string包含的字符数比bitset少,则bitset的高位被置为0
tip:string的下标编号与bitset恰好相反:string中下标最大的字符(最右字符)用来初始化bitset中的低位(下标为0的二进制位)
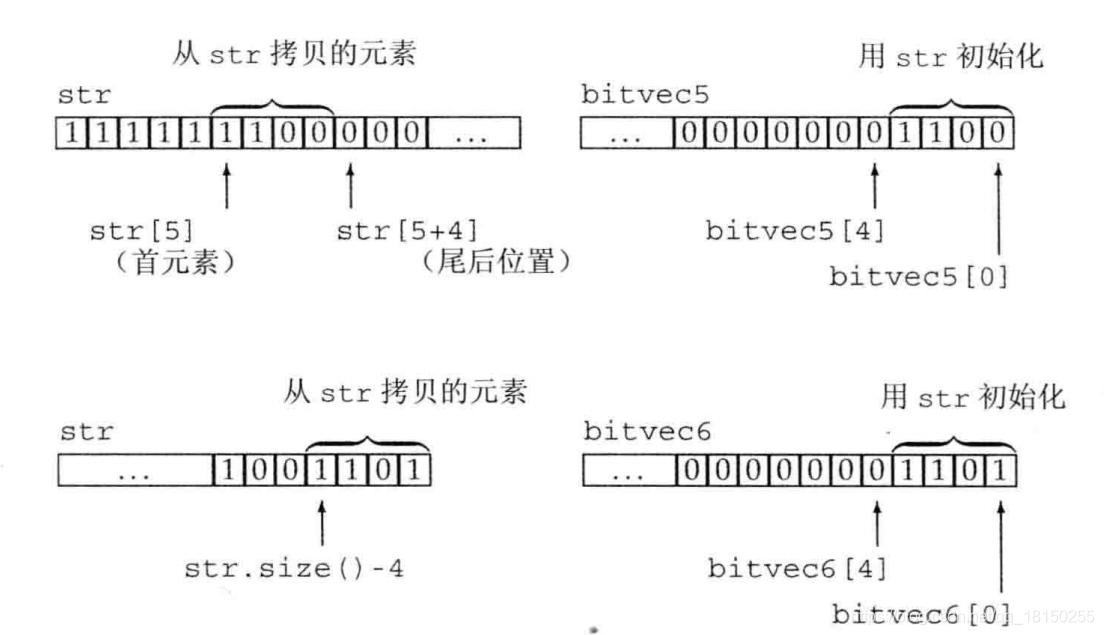
其它初始化方式:
string str("111111100000011001101");
bitset<32> bitvec5(str, 5, 4); //从str[5]开始的四个二进制位,1100
bitset<32> bitvec6(str, str.size() - 4); //使用最后四个字符
下图说明了上述拷贝过程:
2.2 bitset操作
bitset操作定义了多种检测或设置一个或多个二进制位的方法,其操作如下表:
| 操作 | 描述 |
|---|---|
b.any() |
b中是否存在置为的二进制位 |
b.all() |
b中所有位是否都置位了 |
b.none() |
b中不存在置位的二进制吗 |
b.count() |
b中置位的位数 |
b.size() |
一个constexpr,返回b中的位数 |
b.test(pos) |
若pos位置的位是置位的,则返回true,否则返回false |
b.set(pos, v) b.set() |
将位置pos处的位设置为bool值v。v默认为true,若未传递参数,则将b中所有位置位 |
b.reset(pos) b.reset() |
将位置pos处的位复位或将b中的所有位复位 |
b.flip(pos) b.flip() |
改变位置pos处的位的状态或改变b中每一位的状态 |
b[pos] |
访问b中位置pos处的位;若b是const的,则该位置位时b[pos]返回一个bool值true,否则返回false |
b.to_ulong() b.to_ullong() |
返回一个unsigned long或一个unsigned long long值,其位模式与b相同 |
b.to_string(zero, one) |
返回一个string,表示b中的位模式。 |
os << b |
将b中二进制位打印为字符1或0,打印到流os |
is >> b |
从is读取字符存入b。当下一个字符不是1或0时,或是已经读入b.size()个位时,读取过程停止 |
count、size、all、any和none等几个操作都不接受参数,返回整个bitset的状态。当bitset对象的一个或多个位置位(即,等于1)时,操作any返回true。相反,当所有位复位时,none返回true。新标准引入all操作,当所有位置位时返回true;操作count和size返回size_t类型的值,分别表示对象置位的位数或总位数。
提取bitset的值
to_ulong和to_ullong操作都返回一个值,保存了与bitset对象相同的位模式。若bitset中的值不能放入给定类型中,则这两个操作会抛出一个overflow_error异常。
3 正则表达式
正则表达式是一种描述字符序列的方法,一种极其强大的计算工具。RE库定义在头文件regex中,包含多个组件,如下表:
| 名称 | 描述 |
|---|---|
regex |
表示有一个正则表达式的类 |
regex_match |
将一个字符序列与一个正则表达式匹配 |
regex_search |
寻找第一个与正则表达式匹配的子序列 |
regex_replace |
使用给定格式替换一个正则表达式 |
sregex_iterator |
迭代器适配器,调用regex_search来遍历一个string中所有匹配的子串 |
smatch |
容器类,保存在string中搜索的结果 |
ssub_match |
string中匹配的子表达式的结果 |
| 参数 | 描述 |
|---|---|
(seq, m, r, mft) |
在字符序列seq中查找regex对象r中的正则表达式。seq可以是一个string、表示范围的一对迭代器以及一个指向空字符结尾的字符数组的指针 |
(seq, r, mft) |
m是一个match对象,用来保存匹配结果的相关细节。m和seq必须具有兼容的类型;mft是一个可选的regex_constants::match_flag_type值。 |
3.1 使用正则表达式库
一个简单的示例如下:
//查找不在字符c之后的字符串ei
string pattern("[^c]ei");
//包含pattern的整个单词
pattern = "[[:alpha:]]*" + pattern + "[[:alpha:]]*";
regex r(pattern); //构造一个有查找模式的regex
smatch results; //定义一个对象保存搜索结果
//定义一个string保存与模式匹配和不匹配的文本
string test_str = "receipt freind thief receive";
//用r在test_str中查找与pattern匹配的子串
if (regex_search(test_str, results, r)) //如果有匹配子串
cout << results.str() << endl; //打印匹配的单词
//输出
freind
正则表达式[^c]表明我们希望匹配任意不是c的字符,而[^c]ei指出希望匹配这种字符后接ei的字符串。模式[[:alpha:]]匹配任意字母,符号+和*分别表示希望“一个或多个”或“零个或多个”匹配。因此[[:alpha:]]*将匹配零个或多个字母。
指定regex对象的选项
当定义一个regex或是对一个regex调用assign为其赋予新值时,可以指定其标志。
| 操作 | 描述 |
|---|---|
regex r(re) |
re表示一个正则表达式,可以是一个string、一个表示字符范围的迭代器对 |
regex r(re, f) |
一个指向空字符结尾的字符数组的指针等。f是指出对象如何处理的标志。 |
r1 = re |
将r1中的正则表达式替换为re,re表示一个正则表达式,可以是另一个regex对象、一个string、一个指向空字符结尾的字符数组的指针或是一个花括号包围的字符列表 |
r1.assign(re,f) |
与使用赋值运算符(=)效果相同;可选的标志f也与regex的构造函数中对应的参数含义相同 |
r.mark_count() |
r中子表达式的数目 |
r.flags() |
返回r的标志集 |
| 标志符 | 说明 |
|---|---|
icase |
在匹配过程中忽略大小写 |
nosubs |
不保存匹配的子表达式 |
optimize |
执行速度优先于构造速度 |
ECMAScript |
使用ECMA-262指定的语法 |
basic |
使用POSIX基本的正则表达式 |
extended |
使用POSIX扩展的正则表达式 |
awk |
使用POSIX版本的awk语言的语法 |
grep |
使用POSIX版本的grep语言的语法 |
egrep |
使用POSIX版本的egrep语言的语法 |
使用icase标志来查找具有特定扩展名的文件名,其示例如下:
//一个或多个字母或数字字符后接一个'.'再接"cpp"或"cxx"或"cc"
regex r("[[:alnum:]] + \\.(cpp|cxx|cc)$", regex::icase);
smatch results;
string filename;
while (cin >> filename)
if (regex_search(filename, results, r))
cout << results.str() << endl; //打印匹配结果
指定或使用正则表达式时的错误
| 类型 | 描述 |
|---|---|
error_collate |
无效的元素校对请求 |
error_ctype |
无效的字符类 |
error_escape |
无效的转义字符或无效的尾置转义 |
error_backref |
无效的向后引用 |
error_brack |
不匹配的方括号([或]) |
error_paren |
不匹配的小括号((或)) |
error_brace |
不匹配的花括号({或}) |
error_badbrace |
{}中无效的范围 |
error_range |
无效的字符范围(如[z-a]) |
error_space |
内存不足,无法处理此正则表达式 |
error_badrepeat |
重复字符(*、?、+或{)之前没有有效的正则表达式 |
error_complexity |
要求的匹配关于复杂 |
error_stack |
栈空间不足,无法处理匹配 |
正则表达式类和输入序列类型
在匹配时,输入可以是普通char数据或wchar_t数据,字符可以保存在标准库string中或是char数组中。其中匹配和迭代器类型比较特殊:smatch表示string类型的输入序列;cmatch表示字符数组序列;wsmatch表示宽字符串(wstring)输入;而wcmatch表示宽字符数组。
| 若输入序列类型 | 则使用正则表达式类 |
|---|---|
string |
regex、smatch、ssub_match和sregex_iterator |
const char* |
regex、cmatch、csub_match和cregex_iterator |
wstring |
wregex、wsmatch、wssub_match和wsregex_iterator |
const wchar_t* |
wregex、wcmatch、wcsub_match和wcregex_iterator |
3.2 匹配与Regex迭代器类型
可以使用sregex_iterator来获得所有匹配
| 操作 | 描述 |
|---|---|
sregex_iterator it(b, e, r) |
一个sregex_iterator,遍历迭代器b和e表示string |
sregex_iterator end; |
sregex_iterator的尾后迭代器 |
*it it-> |
根据最后一个调用regex_iterator的结果,返回一个smatch对象的引用 |
++it it++ |
从输入序列当前匹配位置开始调用regex_search |
it1 == it2 it1 != it2 |
如果两个``sregex_iterator`都是尾后迭代器,则两者相等 |
| 操作 | 描述 |
|---|---|
m.ready() |
若已经通过调用regex_search或regex_match设置了m,则返回true |
m.size() |
若匹配则返回0;否则返回最近一次匹配的正则表达式中子表达式数目 |
m.empty() |
若m.size()为0,则返回true |
m.rprefix() |
一个ssub_match对象,表示当前匹配之前的序列 |
m.suffix() |
一个ssub_match对象,表示当前匹配之后的序列 |
m.format(...) |
见后续的表 |
m.length(n) |
第n个匹配的子表达式的大小 |
m.position(n) |
第n个子表达式距序列开始的距离 |
m.str(n) |
第n个子表达式匹配的string |
m[n] |
对应第n个子表达式的ssub_match对象 |
m.begin(), m.end() |
表示m中sub_match元素范围的迭代器 |
m.cbegin(), m.cend() |
cbegin和cend返回const_iterator |
3.3 使用子表达式
正则表达式的模式通常包含一个或多个子表达式,通常用括号表子表达式。
子表达式用于数据验证
ECMAScript正则表达式语言的一些特性:
- {d}表示单个数字而{d}{n}则表示一个n个数字的序列。(如,
\{d}{3}匹配三个数字的序列) - 在方括号中的字符集合表示匹配这些字符串中任意一个(如,
[-. ]匹配一个短横线或一个点或一个空格) - 后接‘?’的组件是可选的
- 类似C++,在模式中每次出现的
\的地方需要转义因此需要使用\\
示例如下:
string phone = "(\\()?(\\d{3})(\\))?([-.])?(\\d{3})([-.])?(\\d{4})"
1、"(\\()?表示区号部分可选的左括号
2、(\\d{3})表示区号
3、(\\))?表示区号部分可选的右括号
4、([-.])?表示区号部分可选的分隔符
5、(\\d{3})表示号码的下三位
6、([-.])?表示可选的分隔符
7、(\\d{4})表示号码的最后四位数字
使用子匹配操作
| 操作 | 描述 |
|---|---|
matched |
一个public bool数据成员,指出了此ssub_match是否匹配了public数据成员, |
first |
指向匹配序列首元素和尾后元素位置的迭代器,若未匹配 |
second |
则first和second是相等的 |
length() |
匹配的大小。若matched为false,则返回0 |
str() |
返回一个包含输入中匹配部分的string。若matched为false,则返回空string |
s = ssub |
将ssub_match对象ssub转化为string对象s |
3.4 使用regex_replace
当希望在输入序列中查找并替换一个正则表达式时,可以调用regex_raplace。下表描述了regex_replace,类似搜索函数,它接受一个输入字符序列和一个regex对象,不同的是,还接受一个描述期望输出形式的字符串。
| 操作 | 描述 |
|---|---|
m.format(dest, fmt, mft) |
使用格式字符串fmt生成格式化输出,匹配在m中,可选的match_flag_type标志在mft中。第一个版本写入迭代器dest指向的目的位置,并接受fmt参数 |
m.format(fmt, mft) |
第二个版本返回一个string保存输出,并接受fmt参数 |
regex_replace(dest, seq, r, fmt, mft) |
遍历seq,用regex_search查找与regex对象r匹配的子串,使用格式字符串fmt和可选的match_flag_type标志来生成输出 |
regex_replace(seq, r, fmt, mft) |
第二个版本返回一个string,保存输出,且seq既可以是一个string也可以是一个指向空字符结尾的字符数组的指针 |
,现希望在替换字符串中使用第二个、第五个和第七个子表达式,而忽略第一个、第三个、第四个和第六个子表达式。用一个符号$后跟子表达式的索引号来表示一个特定的子表达式:
string fmt = "$2.$5.$7"; //将号码格式改为ddd.ddd.dddd
string phone = "(\\()?(\\d{3})(\\))?([-.])?(\\d{3}([-.]))?(\\d{4})"
regex r(phone);
string number = "(908) 555-1800"
cout << regex_replace(number, r, fmt)<< endl;
//程序输出为:
908.555.1800
用来控制匹配和格式的标志
标准库定义了用来在替换过程中控制匹配或格式的标志,下表列出了这些标志。这些标志可以传递给函数regex_search或regex_match或者类smatch的format成员。均定义在regex_constants::match_flag_type中,其中使用时需要添加限定符:
using std::regex_constants::format_no_copy;
using namespace std::regex_constants;
| 标志 | 描述 |
|---|---|
match_default |
等价于format_default |
match_not_bol |
不将首字符作为行首处理 |
match_not_eol |
不将尾字符作为行尾处理 |
match_not_bow |
不将首字符作为单词首处理 |
match_not_eow |
不将尾字符作为单词尾处理 |
match_any |
如果存在多余一个匹配,则可返回任意一个匹配 |
match_not_null |
不匹配如何空序列 |
match_continuous |
匹配必须从输入的首字符开始 |
match_prev_avail |
输入序列包含第一个匹配之前的内容 |
format_default |
用ECMAScript规则替换字符串 |
format_sed |
用POSIXsed规则替换字符串 |
format_no_copy |
不输出输入序列中为匹配的部分 |
format_first_only |
只替换子表达式的第一次出现 |
使用格式标志
默认情况下,regex_replace输出整个输入序列,未与正则表达式匹配的部分会原样输出;匹配的部分按格式字符串指定的格式输出。在regex_replace调用中指定format_no_copy来改变这种默认行为:
//只生成电话号码:使用新的格式字符串
string fmt2 = "$2.$5.$7 "; //在最后一部分号码后放置空格作为分隔符
//通知regex_replace只拷贝它替换的版本
cout << regex_replace(s, r, fmt2, format_no_copy) << endl;
4 随机数
定义在random中的随机数库通过一组协作的类来解决这些问题:随机数引擎和随机数分布。
4.1 随机数引擎和分布
随机数引擎是函数对象类,其定义了一个调用运算符,该运算符不接受参数并返回一个随机unsigned整数。通过调用一个随机数引擎对象来生成原始随机数,示例如下:
default_random_engine e; //生成随机无符号数
for (size_t i = 0; i < 10; ++i)
//e()"调用"对象来生成下一个随机数
cout << e() << " ";
| 操作 | 描述 |
|---|---|
Engine e; |
默认构造函数;使用该引擎类型默认的种子 |
Engine e(s); |
使用整型值s作为种子 |
e.seed(s) |
使用种子s重置引擎的状态 |
e.min() e.max() |
此引擎可生成的最小和最大值 |
Engine::result_type |
此引擎生成的unsigned整型类型 |
e.discard(u) |
将引擎推进u步;u的类型为unsigned long long |
分布类型和引擎
为了得到一个指定范围内的数,使用一个分布类型的对象:
//生成0到9之间(包含)均匀分布的随机数
uniform_int_distribution<unsigned> u(0, 9);
default_random_engine e; //生成无符号随机整数
for (size_t i = 0; i < 10; ++i)
cout << u(e) << " ";
引擎生成一个数值序列
即使生成的数看起来是随机的,但对于一个给定的发生器,每次运行程序都会返回相同的数值序列。改变此现象的方法:将引擎和关联的分布对象定义为static
//返回一个vector,包含100个均匀分布的随机数
vector<unsigned> good_randVec()
{
//由于希望引擎和分布对象保存状态,因此应将
//其定义为static的,从而每次调用都生成新的数
static default_random_engine e;
static uniform_int_distribution<unsigned> u(0, 9);
vector<unsigned> ret;
for(size_t i = 0; i < 100; ++i)
ret.push_back(u(e));
return ret;
}
由于e和u是static的,因此其在函数调用之间会保持住状态。
Tips:一个给定的随机数发生器一直会生成相同的随机数序列。若一个函数定义了局部的随机数发生器,应该将其(包括引擎和分布对象)定义的static的,否则,每次调用函数都会生成相同的序列。
设置随机数发生器种子
可以通过设置不同的种子来生成不同的随机结果,为引擎设置种子有两种方式:在创建引擎对象时提供种子,或者调用引擎的seed成员:
default_random_engine e1; //使用默认种子
default_random_engine e2(2147483646); //使用给定的种子值
default_random_engine e3; //使用默认种子值
e3.seed(32767); //调用seed设置一个新种子值
4.2 其他随机数分布
使用新标准库设施,可以获得随机浮点数,示例如下:
default_random_engine e; //生成无符号随机整数
//0到1(包含)的均匀分布
uniform_real_distribution<double> u(0, 1);
for (size_t i = 0; i < 10; ++i)
cout << u(e) << " ";
| 操作 | 描述 |
|---|---|
Dist d; |
默认构造函数,分布类型的构造函数是explicit的 |
d(e) |
根据d的分布式类型生成一个随机数序列 |
d.min() d.max() |
返回d(e)能生成的最小值和最大值 |
d.reset() |
重建d的状态,使得随后d的使用不依赖于d已经生成的值 |
生成非均匀分布的随机数
由于normal_distribution生成浮点值,可使用cmath头文件中的lround函数将每个随机数舍入到最接近的整数。示例如下:
default_random_engine e; //生成随机整数
normal_distribution<> n(4, 1.5); //均值4,标准差1.5
vector<unsigned> vals(9); //9个元素均为0
for(size_t i = 0; i != 200; ++i)
{
unsigned v = lround(n(e)); //舍入到最接近的整数
}
bernouli_distribution类
bernouli_distribution分布不接受模板参数,此分布总是返回一个bool值,其返回true的概率是一个常数,默认值是0.5。可修改其概率:
bernouli_distribution b(.55);
5 IO库
5.1 格式化输入与输出
标准库定义了一组操作符来修改流的格式状态。操作符用于两大类输出控制:控制数值的输出形式以及控制补白的数量和位置。
控制布尔值的格式
操作符改变对象的格式状态的例子,通过对流使用boolalpha操作符来改变输出格式:
cout << "default bool values: " << true << " " << false
<< "\nalpha bool values: " << boolalpha
<< true << " " << false << endl;
//执行结果如下:
default bool values: 1 0
alpha bool values: true false
设置和取消格式状态
bool bool_val = get_status();
cout << boolalpha //设置cout的内部状态
<< bool_val
<< noboolalpha; //将内部状态恢复为默认格式
指定整型值的进制
在默认情况下,整型值的输入输出使用十进制。可以使用操作符hex、oct和dec将其改为十六进制、八进制或是改回十进制:
cout << "default" << 20 << " " << 1024 << endl;
cout << "octal" << oct << 20 << " " << 1024 << endl;
cout << "hex" << hex << 20 << " " << 1024 << endl;
cout << "decimal" << dec << 20 << " " << 1024 << endl;
在输出中指出进制
使用showbase操作符,打印进制。当对流应用showbase操作符时,会在输出结果显示进制,遵循与整型常量中指定进制相同的规范:
- 前导0x表示十六进制
- 前导0表示八进制
- 无前导字符串表示十进制
示例如下:
cout << showbase; //当打印整型值时显示进制
cout << "default" << 20 << " " << 1024 << endl;
cout << "in octal" << oct << 20 << " " << 1024 << endl;
cout << "in hex" << hex << 20 << " " << 1024 << endl;
cout << "in decimal" << dec << 20 << " " << 1024 << endl;
cout << noshowbase; //恢复流状态
默认情况下,十六进制值会以小写打印前导字符也是小写的x,可以通过使用uppercase操作符来输出大写的X并将十六进制数字a-f以大写输出:
cout << uppercase << showbase << hex
<< "printed in hexadecimal:" << 20 << " " << 1024 << endl;
<< nouppercase << noshowbase << dec << endl;
控制浮点数格式
可以控制浮点数输出三种格式:
- 以多高精度(多少个数字)打印浮点值
- 数值是打印为十六进制、定点十进制还是科学计数法形式
- 对于没有小数部分的浮点值是否打印小数点
默认情况下,浮点值按六位数字精度打印;非常大和非常小的值打印为科学计数法形式,其他值打印为定点十进制形式。
指定打印精度
可以通过调用IO对象的precision成员或使用setprecision操作符来改变精度,该函数定义在头文件iomanip中。
以下示例展示了控制浮点值打印精度的不同方法:
//cout.precison返回当前精度值
cout << "Precision: " << cout.precision()
<< ", Value:" << sqrt(2.0) << endl;
cout.precision(12); //将打印精度设置为12位数字
cout << "Precision: " << cout.precision()
<< ", Value:" << sqrt(2.0) << endl;
//使用setprecision操作符将打印精度设置为3位数字
cout << setprecision(3);
cout << "Precision: " << cout.precision()
<< ", Value:" << sqrt(2.0) << endl;
| 操作符 | 描述 |
|---|---|
boolalpha |
将true和false输出为字符串 |
noboolalpha |
将true和false输出为1, 0 |
showbase |
对整型值输出表示进制的前缀 |
noshowbase |
不生成表示进制的前缀 |
showpoint |
对浮点值总是显示小数点 |
noshowpoint |
只有当浮点值包含小数部分是才显示小数点 |
showpos |
对非负数显示+ |
noshowpos |
对非负数不显示+ |
uppercase |
在十六进制值值打印0X,在科学计数法中打印E |
nouppercase |
在十六进制值值打印0x,在科学计数法中打印e |
dec |
整数值显示为十进制 |
hex |
整数值显示为十六进制 |
otc |
整数值显示为八进制 |
left |
在值的右侧添加填充字符 |
right |
在值的左侧添加填充字符 |
internal |
在符号和值之间添加填充字符 |
fixed |
浮点值显示为定点十进制 |
scientific |
浮点值显示为科学计数法 |
hexfloat |
浮点值显示为十六进制(C++新特性) |
defaultfloat |
重置浮点数格式为十进制(C++新特性) |
unitbuf |
每次输出操作后都刷新缓冲区 |
nounitbuf |
恢复正常的缓冲区刷新方式 |
skipws |
输入运算符跳过空白符 |
noskipws |
输入运算符不跳过空白符 |
flush |
刷新ostream缓冲区 |
ends |
插入空字符,然后刷新ostream缓冲区 |
endl |
插入换行,然后刷新ostream缓冲区 |
| 操作符 | 描述 |
|---|---|
setfill(ch) |
用ch填充空白 |
setprecision(ch) |
将浮点精度设置为n |
setw(ch) |
读或写值的宽度为w个字符 |
setbase(ch) |
将整数输出被b进制 |
5.2 未格式化的输入/输出操作
单字节操作
有几个未格式化操作每次一个字节地处理流。会读取而不是忽略空白符。例如:使用未格式化IO操作get和put来读取和写入一个字符,示例如下:
char ch;
while(cin.get(ch))
cout.put(ch);
| 操作 | 描述 |
|---|---|
is.get(ch) |
从istream is读取下一个字节存入字符ch中。返回is |
os.put(ch) |
将字符ch输出到ostream os。返回os |
is.get() |
将is下一个字节作为int返回 |
is.putback(ch) |
将字符ch放回is,返回is |
is.unget() |
将is向后移动一个字节。返回is |
is.peek() |
将下一个字节作为int返回,但不从流中删除它 |
将字符放回输入流
将字符放回流中,标准库提供了三种方法退回字符,但有着细微的差别:
- peek返回输入流中下一个字符的副本,但不会将它从流中删除,peek返回的值仍然留在流中
- unget使得输入流向后移动,从而最后读取的值又回到流中
- putback是特殊版本的unget:它退回从流中读取的最后一个值,但接受一个参数,此参数必须与最后读取的值相同。
从输入操作返回的int值
这些函数返回一个int的引用是:可以返回文件尾标记。返回int的函数将它们要返回的字符先转换为unsigned char,然后再将结果提升到int。而标准库使用负值表示文件尾,这样就可以保证与任何合法字符的值都不同。头文件cstdio定义了一个名为EOF的const,可以用它来检测从get返回的值是否是文件尾,而不必记忆表示文件的实际数值。用一个int来保存从这些函数返回的值:
int ch; //注意!!!这里使用一个int,而不是char来保存get()的返回值
//循环读取并输出输入中的所有数据
while ((ch = cin.get()) != EOF)
cout.put(ch);
多字节操作
| 操作 | 描述 |
|---|---|
is.get(sink, size, delim) |
从is中读取最多size个字节,并保存到以sink为起始地址的字符数组中。直到遇到字符delim或读取了size个字节或遇到文件尾时停止 |
is.getline(sink, size, delim) |
与接受三个参数的get版本类似,但会读取并丢弃delim |
is.read(sink, size) |
读取最多size个字节,存入字符数组sink中。返回is |
is.gcount() |
返回上一个未格式化读取操作从is读取的字节数 |
os.write(source, size) |
将字符数组source中的size个字节写入os。返回os |
is.ignore(size, delim) |
读取并忽略最多size个字符,包括delim |
get和getline 函数接受相同的参数,两者行为类似但不同。两个函数都一直读取数据,直至下面条件之一发生:
- 已读取了size - 1个字符
- 遇到了文件尾
- 遇到了分隔符
两个函数的差别是处理分隔符的方式:get将分隔符留作istream中的下一个字符,而getline则读取并丢弃分隔符。
确定读取了多少个字符
某些操作从输入读取未知个数的字节,可以通过调用gcount来确定最后一个未格式化输入操作读取了多少个字符。如果在调用gcount之前调用了peek、unget或putback,则gcount的返回值为0。
5.3 流随机访问
seek和tell函数
通过函数seek可以将标记seek到一个给定位置来重定位它;而函数tell则表明标记的当前位置。
| 函数操作 | 描述 |
|---|---|
tellg() |
返回一个输入流中(tellg())或输出流中(tellp()) |
tellp() |
标记的当前位置 |
seekg(pos) |
在一个输入流或输出流中将标记重定位到给定的绝对地址 |
seekp(pos) |
pos通常是前一个tellg或tellp返回的值 |
seekp(off, from) |
在一个输入流或输出流中将标记定位到from之前或之后off个字符 |
seekg(off, from) |
from可以是beg(偏移量相对流开始的位置)、cur(当前)、end(结尾) |
重定位标记
seek函数有两个版本:一个移动到文件中的”绝对“地址;另外一个移动到一个给定位置的指定偏移量:
//将标记移动到一个固定位置
seekg(new_position); //将读标记移动到指定的pos_type类型的位置
seekp(new_position); //将写标记移动到指定的pos_type类型的位置
//移动到给定起始点之前或之后指定的偏移位置
seekg(offset, from); //将读标记移动到距from偏移量为offset的位置
seekg(offset, from); //将写标记移动到距from偏移量为offset的位置
访问标记
函数tellg和tellp返回一个pos_type值,表示流的当前位置。示例如下:
//记住当前写位置
ostringstream writeStr; //输出stringstream
ostringstream::pos_type mark = writeStr.tellp(); //输出stringstream
//...
if (cancelEntry)
//回到刚才记住的位置
writeStr.seekp(mark);