向量化召回
向量化召回,主要通过模型来学习用户和物品的兴趣向量,并通过内积来计算用户和物品之间的相似性,从而得到最终的候选集。其中,比较经典的模型便是Youtube召回模型。在实际线上应用时,由于物品空间巨大,计算用户兴趣向量和所有物品兴趣向量的内积,耗时十分巨大,有时候会通过局部敏感Hash等方法来进行近似求解。
图嵌入
- ID类特征用one-hot编码有什么弊端?
1)高维稀疏问题:对于高维稀疏问题,若有N个物品,那么用户交互过的物品的可能情况共2^N种情况,为了使我们的模型更加具有可信度,所需要的样本数量是随着N的增加呈指数级增加的。
2)它无法反映ID之间的关系:对于同质信息来说,比如不同的物品,假设是iphon5和iphone6,以及iphone5和华为,在转换成one-hot编码后,距离是一样的,但是实际上,iphon5和iphone6的距离应该更近。对于异质信息,如物品ID和商铺ID,它们的距离甚至无法衡量,但实际上,一家卖苹果手机的商铺和苹果手机之间,距离应该更近。 - 基础的图嵌入算法如何应用到推荐系统中,介绍一下流程?
- 从用户的行为中抽取出序列
- 将所有得到的序列表示成有向带权图(所有用户得到一张图,而不是每个用户一张)
- 基于随机游走的方法产生一批序列
- 通过Skip-Gram的方法来学习每个商品的向量
- 抽取用户行为序列时有什么注意事项?
- 如果使用用户整个的行为历史序列,计算和空间存储资源耗费巨大
- 用户的兴趣在长时间内是会变化的,但是用户短时间内的兴趣是相同的
所以需要对用户的历史行为序列进行切割。这里以一小时为间隔,若两个商品的交互时间超过1小时,就进行切分。如E和D的时间间隔大于1小时,所以将序列切割为BE和DEF
- 从序列到有向图的过程中,如何对噪声信息过滤?
- 点击之后用户停留时间小于5s,这可能是用户的误点击,需要过滤。
- 太过活跃的用户进行过滤,比如三个月内购买了1000件以上的商品,点击了3500个以上的商品。
- 同一个ID,但是发生变化的商品需要过滤。
- 传统的图嵌入如何改进解决冷启动问题呢?
- 加入Side information,Graph Embedding with Side information (GES)。
计算如下,其中W0代表item embedding,W1,Wn代表每种Side information对应的embedding。

- 不同的side information权重应该是不同的,Enhanced Graph Embedding with Side information (EGES)。
比如一个购买了iphone的用户,倾向于查看mac或者ipad,更多的是因为他们都是苹果的牌子。计算公式改为:
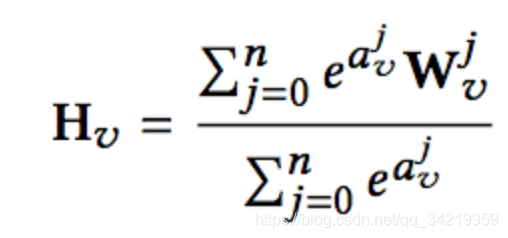
具体的内容查看GES和EGES的学习
双塔模型
- 简单介绍什么是双塔模型召回?
分别用复杂网络对“用户特征”和“物品特征”进行了embedding化,在最后的交叉层之前,用户特征和广告特征之间没有任何交互,这就形成了两个独立的“塔”,因此称为双塔模型。
双塔模型实质上是在学习用户和物品的Embedding,并通过Embedding的内积来计算二者的相似性。 - 双塔模型线上效率如何?
在完成双塔模型的训练后,可以把最终的用户embedding和广告embedding存入内存数据库。而在线上inference时,也不用复现复杂网络,只需要实现最后一层的逻辑,在从内存数据库中取出用户embedding和广告embedding之后,通过简单计算即可得到最终的预估结果。
在graph embedding技术已经非常强大的今天,利用embedding离线训练的方法已经可以融入大量user和item信息。那么利用预训练的embedding就可以大大降低线上预估模型的复杂度 - 在工业界大规模推荐系统中使用双塔模型,训练优化方面有啥思路嘛?
参考谷歌的论文《Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations》,应用采样修正的双塔模型
1)使用batch softmax optimization来训练模型。
2)使用frequency estimation来修正采样偏差,修正方法基于Multiple Hashings。
3)线上应用时使用hash等技术来提高检索效率。
4)对两侧得到的Embedding进行L2正则化。
5)通过对得到的内积除以一个超参数,使得softmax结果更加明显 - Embedding方面有什么改进思路?
用户的Embedding可以表征用户的兴趣,但是目前的大多数算法仅仅将用户的兴趣表示成单个的Embedding,这是不足以表征用户多种多样的兴趣的,同时容易造成头部效应。
在天猫的论文《Multi-Interest Network with Dynamic Routing for Recommendation at Tmall》中,提出了MIND,同时生成多个表征用户兴趣的Embedding,来提升召回阶段的效果
协同过滤
- 有哪些常用的协同过滤算法?做比较
基于用户和基于物品两种

新闻网站一般使用UserCF,而图书、电商网站一般使用ItemCF!UserCF的推荐更社会化,反映了用户所在的小型兴趣群体中物品的热门程度,而ItemCF的推荐更加个性化,反映了用户自己的兴趣传承。 - 实现上有什么注意的点?
- 热门惩罚
- 在效率上采用倒排索引
- 协同过滤有哪些不足?
在召回的时候,并不能真正的面向全量商品库来做检索,如itemCF方法,系统只能在用户历史行为过的商品里面找到侯选的相似商品来做召回,使得整个推荐结果的多样性和发现性比较差。这样做的结果就是,用户经常抱怨:为什么总给我推荐相同的东西!
深度树匹配
能否设计一套全新的推荐算法框架,它允许容纳任意先进的模型而非限定内积形式,并且能够对全库进行更好的检索。深度树匹配,就是从这个视角出发做的技术探索
- 简单介绍下深度树匹配的思想?
深度树匹配的核心是构造一棵兴趣树(平衡二叉树),其叶子结点是全量的物品,每一层代表一种细分的兴趣。 - 怎么基于树来实现高效的检索?
假设已经得到深度树的情况下,高效检索采用的是Beam-Search的方式:
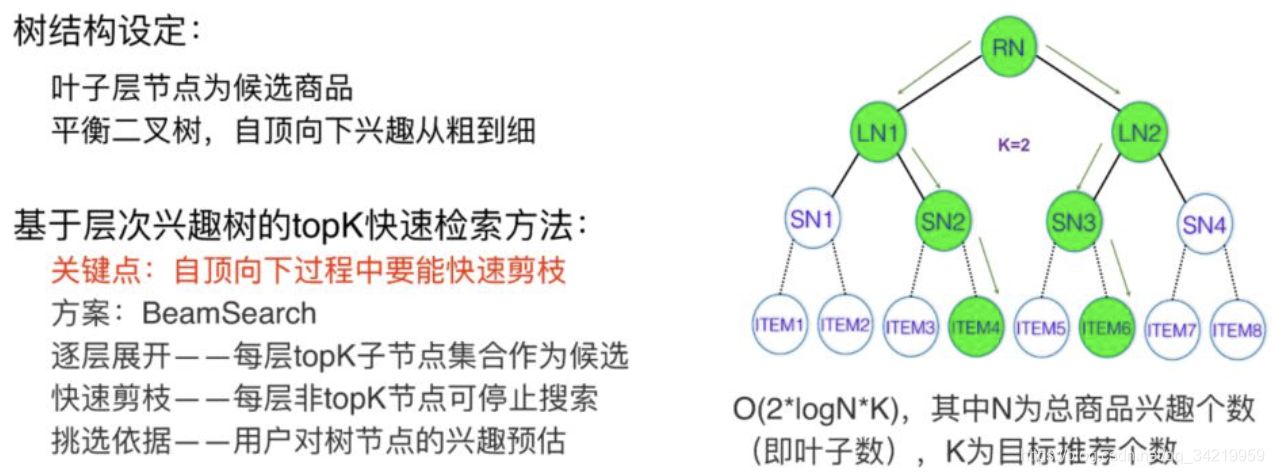
- 怎么在树上面做兴趣建模?
首先需要将树建立为一棵最大堆树。
构造最大堆树可以举个简单的例子,假设用户对叶子层 ITEM6 这样一个节点是感兴趣的,那么它的兴趣是 1,同层其他的节点兴趣为 0,父节点递归

在每一层构建一定的正负样本,通过构建模型来学习用户对于每一层节点的兴趣偏好。注意的是,每层的偏好都要学习,也就是说每层都要构建一个模型。 - 兴趣树如何构建?
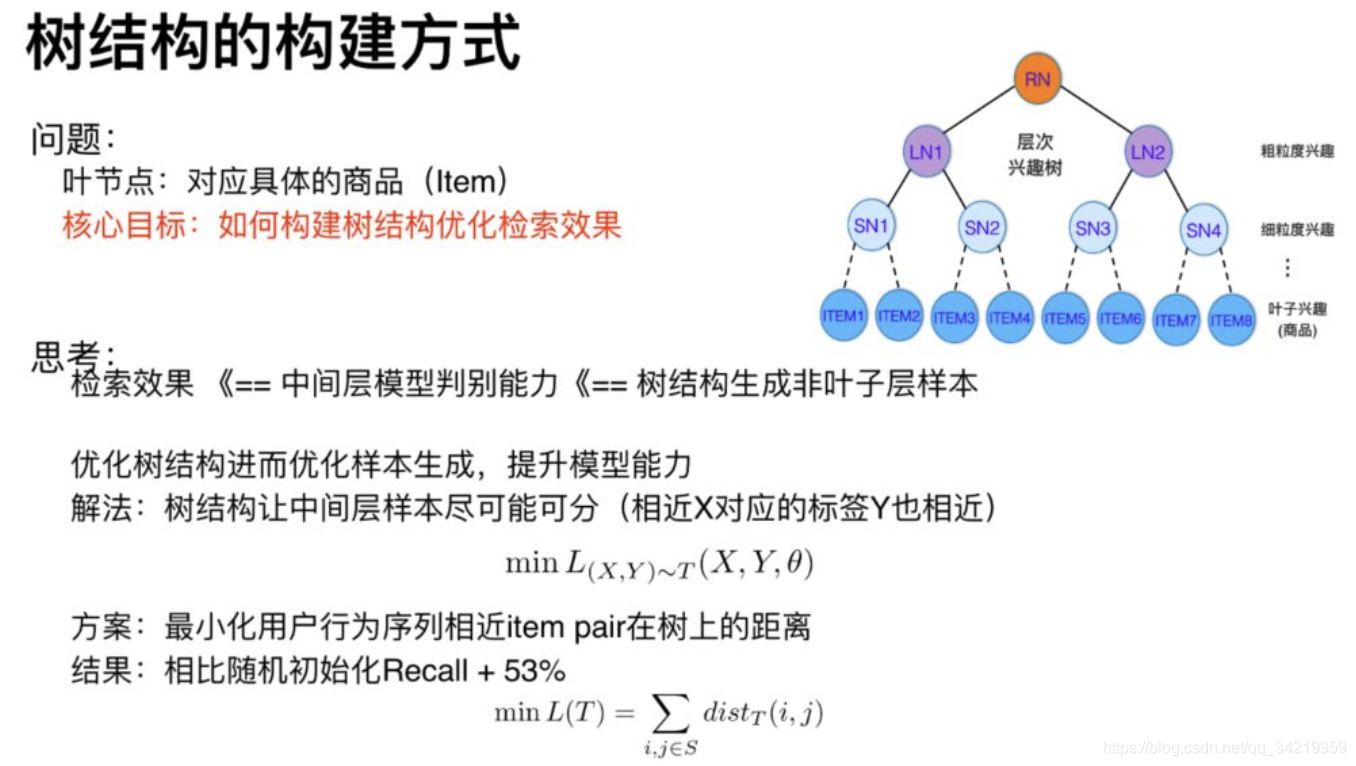
方案总结来说,就是最小化用户行为序列中相近的item-pair在树上的距离。假设用户的行为序列为A-》B-》D-》C,那么我们希望(A,B),(B,D),(D,C)在树上的距离越近越好。两个叶子结点的距离通过其最近的公共祖先确定。
