1. 章节主要内容
奥卡姆剃刀原理
没有免费午餐(NFL)
1)首先解答一个大家都关系的基础问题:什么是机器学习?
为了解答这个问题,我们先来看看西瓜书中那个著名的例子:
傍晚小街路面上沁出微雨后的湿润,和煦的细风吹来,抬头看看天边的晚霞,嗯,明天又是一个好天气。走到水果摊旁,挑了个根蒂蜷缩、敲起来声音浊响的青绿西瓜,一边满心期待着皮薄肉厚瓤甜的爽落感,一边愉快地想着,这学期狠下了功夫,基础概念弄的清清楚楚,算法作业也是信手拈来,这门课成绩一定差不了
上面这段话简简单单,初看没有任何值得惊讶或好奇的内容,可如果我们深入的分析一下,会发现这段话描述了我们日常生活中各种随处可见的认知过程,那就是我们会根据各自经验去对事物进行预判。比如,和风和晚霞为什么就可以推断出明天是好天气呢?根蒂蜷缩、浊响声音、青绿色的西瓜为什么是个好西瓜呢?基础概念清楚、算法作业熟练为什么就会考出好成绩呢?
这些预判都是我们的大脑对日常生活中经验学习的结果。就拿买西瓜为例吧,因为经过多次的买西瓜经验,大脑通过学习,总结出一套瓜的外在特征(色泽、根蒂和敲响)和内在口味(好瓜、坏瓜)之间的关系模型,而这套关系模型可以被用在未来任意一次买瓜行动中来给我们提供相应的判断。
机器学习的本质说到底就和上边这个例子一样,只不过在计算机的世界,我们所说的经验就是一条条的数据罢了。机器在数据上进行学习,并总结出一套通用的规律。
那么关于“什么是机器学习”这个问题的答案,我们可以总结为:机器学习是致力于研究如何通过计算的手段,利用经验来改善系统自身性能的学科。其表现为对经验(数据)和结论(预测)之间关系的总结和归纳。
2)在理解了什么是机器学习了之后,我们想要更进一步的了解的是:机器学习算法到底是如何学习的?
在解答这个问题前,我们先了解一下科学推理的两大基本手段:归纳(induction)与演绎(deduction)。前者是从特殊到一般的“泛化”(generalization)过程,即从具体事实归结出一般性规律;后者是从一般到特殊的“特化”(specialization)过程,即从基础性原理推演出具体状况。
机器学习的过程其实就是上边的归纳过程,还是以挑西瓜为例

机器学习的过程就是从具体数据集中“泛化”的过程,即通过对训练集中瓜的学习以获得对没见过的瓜进行判断的能力。我们可以把学习过程看作一个在所有假设(hypothesis)组成的空间中进行搜索的过程,搜索目标是找到与训练集“匹配”(fit)的假设,即能够将训练集中的瓜判断正确的假设。
例如在表1.1的训练集上,我们可以找到匹配训练样本的假设列表,展示如下:
(色泽=*,根蒂=蜷缩,敲声=*) -> 好瓜 (1)
(色泽=*,根蒂=*,敲声=浊响) -> 好瓜 (2)
(色泽=*,根蒂=蜷缩,敲声=浊响) -> 好瓜 (3)
3)从上文中我们可以得知在同一个训练集上进行匹配,有可能会匹配出多个假设,那么机器学习的具体过程中算法的选择依据是什么呢?
在现实问题中我们常面临很大的假设空间,可学习过程是基于有限样本训练集进行的,因此,可能有多个假设与训练集一致,即存在着一个与训练集一致的“假设集合”,我们称之为“版本空间”,上边的假设(1)(2)(3)即在西瓜数据集上“泛化”出的假设空间。
那么当我们遇到一个新收来的瓜(色泽=青绿,根蒂=蜷缩,敲声=沉闷),那么我们该选用哪个假设来进行判断呢?如果使用假设(1)时,这是一个好瓜,可如果使用假设(2)(3)时,这就是一个坏瓜了。
这时候的选择偏好被称为“归纳偏好”,而任何一个有效的机器学习算法必有其归纳偏好,否则它必然被假设空间中等效的假设所迷惑,而无法产生确定的学习结果。
一种常用的、自然科学研究中最基本的“正确的”偏好原则是“奥卡姆剃刀”(Occam's razor)原则
奥卡姆剃刀原则:若有多个假设与观察一致,则选最简单的那个
事实上,归纳偏好对应了学习算法本身所做出的关于“什么样的模型更好”的假设。在具体的现实问题中,算法的归纳偏好是否与问题本身匹配,大多数时候直接决定了算法能否取得好的性能。
举个例子,在下边回归学习的1.3图示中,每个训练样本是图中的一个点,要习得一个和训练集一致的模型,相当于找到一条穿过所有训练样本点的曲线。显然,这样的曲线有很多条。如果使用奥卡姆剃刀偏好原则的话,更为平滑的曲线A会比曲线B要好。
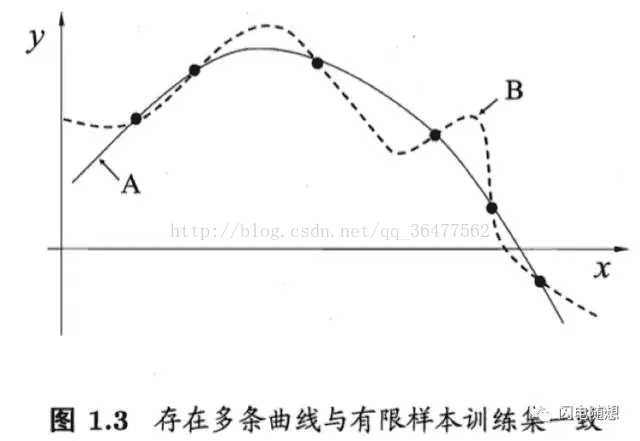
可实际情况,A曲线却并不一定比B曲线好,因为用来训练的样本只是全量数据的一部分,真正的数据到底是更贴近曲线A还是曲线B是无法得知的。如图1.4所示,真实的数据是两种情况都有可能出现。换言之,对于一个学习算法a,若它在某些问题上比学习算法b好,则必然存在另一些问题,在那里b比a好。
Wolpert在1996年提出的“没有免费的午餐”定理(No Free Lunch Theorem,简称NFL定理)证明了无论学习算法a多聪明、学习算法b多笨拙,它们的期望性能都相同。
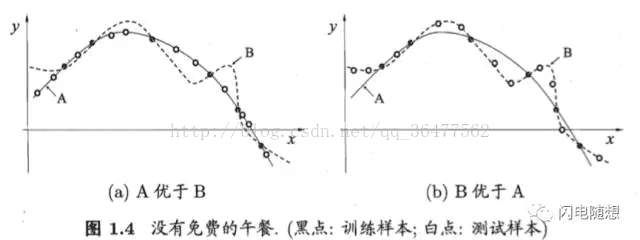
可NFL定理有一个重要前提:所有“问题”出现的机会相同、或所有问题同等重要。但实际情况并不是这样的,很多时候,我们只关注自己正在试图解决的问题。比如,要找到快速从A地到B地的算法,如果我们考虑A地是南京鼓楼、B地是南京新街口,那么“骑自行车”是很好的解决方案;但是这个方案对A地是南京鼓楼、B地是北京新街口的情形显然很糟糕,但我们对此并不关心。
所以,NFL定理最重要的寓意,是让我们清楚意识到,脱离具体问题,空泛地谈论“什么学习算法更好”毫无意义,因为若考虑所有潜在的问题,则所有的算法都一样好。针对具体问题选择具体的算法和归纳偏好才是正确的做法。
2.基础概念
1) 基本术语
为了便于理解,我在这里将场景定为上文中提到的挑西瓜的例子
数据集(data set):记录的集合(西瓜的描述集合)
“示例”(instance)或“样本”(sample):数据集中的一条记录,是关于一个事件或对象的描述。(每个示例代表对一个西瓜的描述)
“属性”(attribute)或“特征”(feature):反映对象某方面的表现或性质的事项。(根蒂、敲声、色泽)
“属性值”(attribute value):属性的具体取值。(例如色泽的取值可以为:青绿、乌黑)
“属性空间”(attribute space)、“样本空间”(sample space)或“输入空间”:属性张成的空间。(根蒂、敲声、色泽张成一个关于西瓜的三维空间)
“特征向量”(feature vector):属性空间中的每一个,向量点代表一个具体的对象。这个向量点就是特征向量
标签(label):我们建立的预测。(是不是“好瓜”)
分类(classification):预测的是离散值。(好瓜、坏瓜)
回归(regression):预测的是连续值。(西瓜成熟度:0.95、0.37)
聚类(clustering):对数据集进行分组,分组结果预先不知。
监督学习(supervised learning):有标记信息的学习任务,代表是分类和回归。
非监督学习(unsupervised learning):没有标记信息的学习任务,代表是聚类。
2)奥卡姆剃刀原则
奥卡姆剃刀原则是在产品设计、行为偏好、流程设计等各种各样领域中都反复出现的概念,(据我理解)其本质意思是简单能表示的东西,就不要做得复杂。该原则在本章节中被使用在了偏好选择上,即“若有多个假设与观察一致,则选最简单的那个”
3. 总结
通过本章学习,我们可以得到:
1)如果说计算机科学是研究关于“算法”的学问,那么类似的,可以说机器学习是研究关于“学习算法”的学问。
2)机器学习的本质是构建起输入和输出之间的关系模型,并利用这个关系模型来解决未知的情况。
3)机器学习的学习过程是对数据集的泛化过程
4)并没有绝对好的机器学习算法,脱离具体问题,空泛地谈论“什么学习算法更好”毫无意义,因为若考虑所有潜在的问题,则所有的算法都一样好。
5)针对具体问题选择具体的算法和归纳偏好才是正确的做法。