问题
我们都知道MySQL中有锁,那么下面语句是运用了什么锁呢
select * from table where id = ? select * from table where id < ? select * from table where id = ? lock in share mode select * from table where id < ? lock in share mode select * from table where id = ? for update select * from table where id < ? for update
锁的类型
共享锁和排他锁
Shared Lock和 exclusive lock很好理解,
意向锁
InnoDB 支持多颗粒级别的锁定,它允许同时存在行锁和表锁。 举例 :
LOCK TABLES .... WRITE
上面语句对某个表上了 X 所,为了使它多颗粒级别锁定生效,InnoDB 使用了意向锁(intention locks), **意向锁是表级别的锁,它表示某个事务将会对该表中的行加锁(共享锁或是排他锁),有一下两种类型的意向锁 : **
- (intention shared lock)IS 表示某个事务想要给这个表上某些 rows 上共享锁
- (intention exclusive lock)IX 表示某个事务想要给这个表上某些 rows 上排他锁 这两种锁的语句分别是 :
SELECT ... LOCK IN SHARED MODE ; SELECT ... LOCK FOR UPDATE ;
意向锁遵循以下原则 :
- 一个事务在某个表中的一行上共享锁之前,它必须前获得 IS 锁或是更强的锁(?)
- 一个事务在某个表中的一行上共享锁之前,它必须前获得 IS 锁或是更强的锁(?)
锁的兼容性如下所示

记录锁(Record Locks)
记录锁锁住的是索引的,例如 :
SELECT c1 FROM t WHERE c1 = 10 FOR UPDATE ;
锁住的是c1 = 10 的索引,因为聚集索引的原因,索引和数据在一起的(子叶节点),所以相当于锁住的是行记录。
间隙锁(Gap Locks)
顾名思义就是锁住某个范围的行记录,间隙锁有可能锁住的是多条记录,也有可能是一条,Gap lock 的作用是阻止多个事务将记录插入到同一个范围内,而这会导致**幻读问题的产生。**例如:
//语句1 SELECT c1 FROM t WHERE c1 BETWEEN 10 AND 20 FOR UPDATE; //语句2 SELECT * FROM child WHERE id = 100;
而语句2中,假如 id 是主键,那么将不会使用间隙锁,因为主键本身就是唯一的。 如果需要显示关闭间隙锁,那么只要改变事务的隔离级别为 READ COMMITED .
Next-Key Locks
Next-key lock 可以认为是record lock和索引记录之前的间隙上的gap lock的组合。它在可重复读( REPEATABLE READ )中解决了幻读。 下面的例子就会看到这个组合是如何进行的。
CREATE TABLE z (a INT,b INT,PRIMARY KEY(a),KEY(b)); INSERT INTO z SELECT 1,1; INSERT INTO z SELECT 3,1; INSERT INTO z SELECT 5,3; INSERT INTO z SELECT 7,6; INSERT INTO z SELECT 10,8;

为什么是这样的呢 因为对于聚集索引,其仅对a等于5的索引加上Record Lock , 而对于辅助索引,其加上的是Next-Key Lock ,锁定的范围(1,3),特别需要注意的是,InnoDB存储引擎还会对辅助索引下一个键值加上 gap lock ,即还有一个辅助索引范围(3,6)的锁,索引某些操作会被 阻塞 。
一致性非锁定读
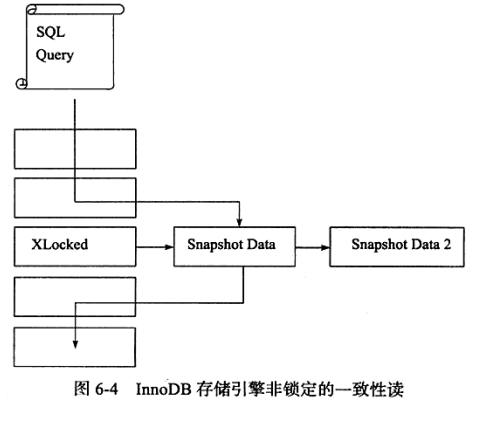
上面的图就是一致性非锁定读的过程,而实现这个过程就是 undo-log ,保存了多个版本的记录,使的不同事务读取到的都是不同记录,
一致性锁定读
某些情况为了保证读取数据逻辑的一致性,即当前读,那么可以使用如下语句 :
//上 X 锁 SELECT ... FOR UPDATE ; //上 S 锁 SELECT ... LOCK IN SHARE MODE ;
补充
改变隔离级别
set @@tx_isolation\G; set session transaction isolation level read committed
ANSI隔离级别
“美国国家标准化组织(ANSI)”是一个核准多种行业标准的组织。SQL作为关系型数据库所使用的标准语言,最初是基于IBM的实现在1986年被批准的。1987年,“国际标准化组织(ISO)”把ANSI SQL作为国际标准。
这一节主要是总结参考文章下关于“ANSI隔离级别”阐述关于 Snapshot Isolation 这一隔离级别功能作用。 下面是关于隔离级别可以阻止某些现象。
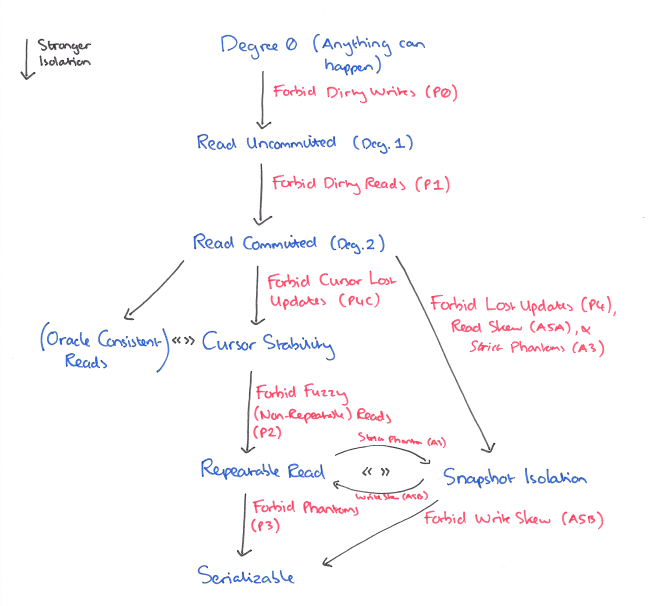
图表的形式如下 :

Snapshot Isolation 和 Repeatable 隔离级别的关系
But Snapshot Isolation and Repeatable Read are incomparable. Snapshot Isolation permits Write Skew, which Repeatable Read does not, and Repeatable Read permits some Phantoms which are not permitted under Snapshot Isolation.
Snapshot Isolation 和 Repeatable Read 是不具比较性的,Snapshot Isolation 允许 Write Skew ,而 Repeatable Read 是不允许出现的;Repeatable Read 是允许出现一些幻读的现象,而在 Snapshot Isolation 是不允许的。
什么是 Write Skew
在下面的 “MySQL中的 Write Skew” 有涉及到,所以这里补充什么是 Write Skew
Write Skew 例子一
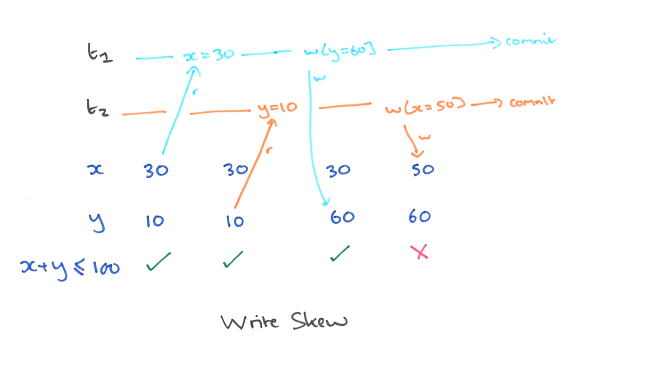 本来数据库中的 x + y <= 100 的(假如事务的修改都要保持 x+y<=100),于是 t1 先读到 x = 30 ,然后write,将y改为60 ;而t2 在此时读到y=10,于是将x改为50 ,于是 最后 x + y > 100 ,之前 x + y <= 100 破坏了,这种关系被破坏的原因,主要的操作都是先读再更新的(read-write),update的操作也是 read-update ,那么MySQL 如何解决的呢?
本来数据库中的 x + y <= 100 的(假如事务的修改都要保持 x+y<=100),于是 t1 先读到 x = 30 ,然后write,将y改为60 ;而t2 在此时读到y=10,于是将x改为50 ,于是 最后 x + y > 100 ,之前 x + y <= 100 破坏了,这种关系被破坏的原因,主要的操作都是先读再更新的(read-write),update的操作也是 read-update ,那么MySQL 如何解决的呢?
MySQL(innodb)为了解决这个问题,强行把 read 分成了 snapshot read(快照读)和 locking read (当前读)。在 UPDATE 或者 SELECT ... FOR UPDATE 的时候,innodb 引擎实际执行的是当前读,在扫描过程中加上行锁和区间锁(gap locks,next-key locks),相当于变相提升到了 serializable 隔离级别,从而消除了 write skew 。从实用角度看,这个解法还是很赞的。既解决了 UPDATE write-skew 问题,又保证了绝大多数场景 SELECT 的性能,特殊情况还可以用 SELECT ... FOR UPDATE,完美。但是,,,,MySQL(innodb)当前读的机制本身和 snapshot 是矛盾的。加锁保护的一定是数据最新版本。例如,如果在快照读之后再执行一次当前读,则读到的数据内容不一定能保证一致,因此会有这样的现象:
(现象描述见下面)
MySQL(innodb)的选择是允许在快照读之后执行当前读,并且更新 snapshot 镜像的版本。严格来说,这个结果违反了 repeatable read 隔离级别,,但是 who cares 呢,毕竟官方都说了:“This is not a bug but an intended and documented behavior.”
作者:in355hz
链接:https://www.zhihu.com/question/334408495/answer/881317999
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
什么现象呢?
CREATE TABLE char_encode (
glyph CHAR(1) NOT NULL,
codepoint TINYINT(3) NOT NULL
) ENGINE=InnoDB
INSERT INTO char_encode VALUES ('a', 97), ('b', 98);
SESSION-1>SHOW SESSION VARIABLE LIKE 'tx_isolation'
tx_isolation | REPEATABLE-READ
SESSION-1>START TRANSACTION;
SESSION-1>SELECT * FROM char_encode;
a | 97
b | 98
SESSION-2>SHOW SESSION VARIABLE LIKE 'tx_isolation'
tx_isolation | REPEATABLE-READ
SESSION-2>START TRANSACTION;
SESSION-2>SELECT * FROM char_encode;
a | 97
b | 98
SESSION-2>UPDATE char_encode SET codepoint = 100 WHERE glyph = 'a';
1 Rows affected;
SESSION-2>SELECT * FROM char_encode;
a | 100
b | 98
//ok, as expected, a tx can always see its OWN changes
SESSION-2>COMMIT;
SESSION-1>SELECT * FROM char_encode WHERE glyph = 'a';
a | 97 //Perfect! as expected; even though session-2 committed, its not part of my snapshot
SESSION-1>UPDATE char_encode SET codepoint = codepoint + 1 WHERE glyph = 'a';
1 Rows affected;
SESSION-1>SELECT * FROM char_encode WHERE glyph = 'a';
a | 101 //Huh?? It was just 97 an instance ago in my snapshot ==> 97 + 1 = 98 last time I checked
可以认为 update 是先执行 select ... for update 然后进行的更新
补充2 (转载)
下面几个问题是来自 怎么面试程序员的MySQL水平?张三毛的,感觉挺有意思的,特此转载过过来学习 。
问题1 :考察数据隔离和事务
有一张表user_count,这个表记录的是不同国家用户的个数。现在如下代码会在以上四个级别的隔离中分别执行一次,请问结果分别是什么?注意,以下代码是在5000个线程中执行的,所以是并发执行的。 数据样例: +--------+--------+ | region | number | +--------+--------+ | us | 0 | | cn | 0 | +--------+--------+ 代码: @dec_multi_thread_run(5000) def do(): try: #步骤一: get old num from table num = "select number from user_count where region = 'cn'" #步骤二: update to new value "update user_count set number = %s where region = 'cn' " % (num +1) except: rollback() else: commit()
结果如下 :
read uncommitted,3271 read committed,2638 repeatable read,2551 serializable,3052
如何使数量等于 5000 呢? 答 : select 语句后面加一个for update就解决问题了。当然直接 update 不要 select 也行。 (为什么可以思考一下)
问题2 : 索引
有一个user表,id是自增主键,记录的是用户的信息。数据量是1000万行,请建立索引并优化用到的查询。 +--------+--------------+----------+----------+--------------+ | id | country \ user_name \ sex \ create_time | +--------+--------------+----------+----------+--------------+ | 1 | cn | alice | female | 1559476160 | | 2 | us | bob | male | 1559476170 | 用到的查询语句 -- 查找叫Alice的人 select * from user where user_name = "alice"; -- 查找国家是us叫Alice的人 select * from user where country = "us" and user_name = "alice"; -- 查找所有叫Alice的女性 select * from user where sex = "female" and user_name = "alice"; -- 展示最新注册的10个用户 select * from user order by create_time desc limit 10;
答 : 最优解是只用一个联合索引(user_name, country)并调整一下语句2和语句3的查询顺序,username放在前面。 针对第一个语句,只查询user_name也能利用到联合索引。针对语句2完美利用了联合索引。针对语句三不用对sex建立索引,因为区分度太低没有意义。针对语句4自增id默认就是按照时间递增的,所以没有必要再增加索引了。
参考资料
- https://dev.mysql.com/doc/refman/5.7/en/innodb-locking.html#innodb-shared-exclusive-locks
- https://blog.acolyer.org/2016/02/24/a-critique-of-ansi-sql-isolation-levels/ (很不错的文章,推荐一看)
- https://zhuanlan.zhihu.com/p/67818300
- https://www.cnblogs.com/rjzheng/p/9950951.html
- https://bugs.mysql.com/bug.php?id=63870
- https://zhuanlan.zhihu.com/p/67818300