文章目录
程序的翻译环境和执行环境
在ANSI C的任何一种实现中,存在两个不同的环境。
第1种是翻译环境,在这个环境中源代码被转换为可执行的机器指令。
第2种是执行环境,它用于实际执行代码。
翻译环境
一个完整的程序有时候需要多个文件共同组成。
编译:组成一个程序的每个源文件通过编译过程分别转换成目标代码(object code)。
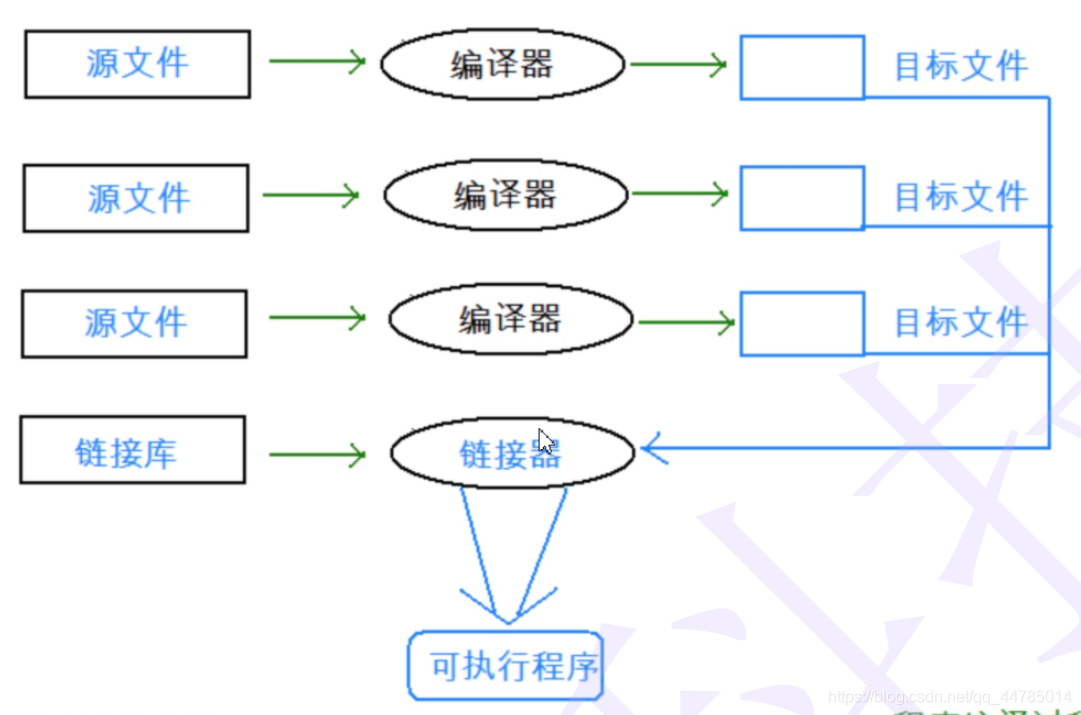
链接:每个目标文件由链接器(linker)捆绑在一起,形成一个单一而完整的可执行程序。
链接器同时也会引入标准C函数库中任何被该程序所用到的函数,而且它可以搜索程序员个人的程序库,将其需要的函数也链接到程序中
运行环境
- 程序必须载入内存中。在有操作系统的环境中:一般这个由操作系统完成。在独立的环境中,程序的载入必须由手工安排,也可能是通过可执行代码置入只读内存来完成。
- 程序的执行便开始。接着便调用main函数。
- 开始执行程序代码。这个时候程序将使用一个运行时堆栈(stack),存储函数的局部变量和返回地址。程序同时也可以使用静态(static)内存,存储于静态内存中的变量在程序的整个执行过程一直保留他们的值。
- 终止程序。正常终止main函数,也有可能是意外终止
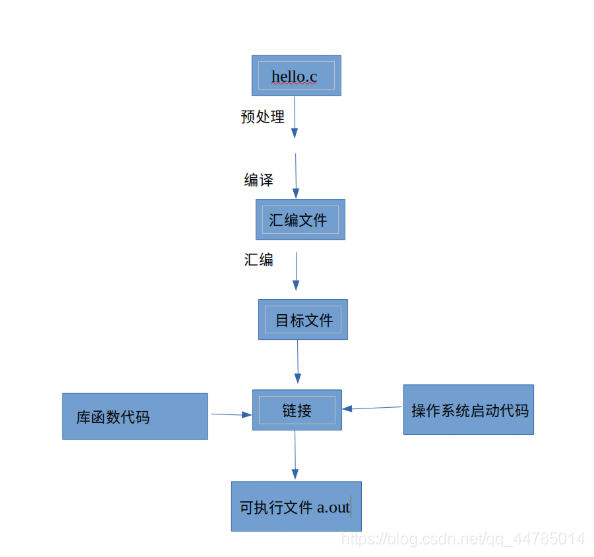
由于一般windows的编译器上常常都是一键编译,我们无法看到具体的过程,所以以linux
的调试流程来解释整个流程,分为四个阶段:
1.预处理 gcc -E [filename].c -o [filename].i
功能:展开头文件/宏替换/去掉注释/条件编译
文件后缀变化 .c -> .i
2.编译 gcc -S [filename].c-o [filename].s
功能:检查语法(语法分析/词法分析/语义分析/符号汇总)/生成汇编代码
.i -> .s
错误时 报编译错误
3.汇编 gcc -c [filename].c-o [filename].o
转成二进制的机器码(系统内核只认识0和1)
.s -> .o
4.链接 gcc [filename].o -o[filename]
对之前的声明去实现,合并目标文件、库文件,合并符号表/符号表的重定位。
错误时 报链接错误
#define
#define 机制包括了一个规定,允许把参数替换到文本中,这种实现通常称为宏(macro)或定义宏(definemacro)
#define MAX 1000 //定义标识符
宏通常被应用于执行简单的运算。比如在两个数中找出较大的一个。
#define MAX(a, b) ((a)>(b)?(a):(b)) //定义函数功能的宏 //括号一定要记得多用
#undef
这条指令用于移除一个宏定义。
#undef MAX
#define 替换规则
在程序中扩展#define定义符号和宏时,需要涉及几个步骤。
- 在调用宏时,首先对参数进行检查,看看是否包含任何由#define定义的符号。如果是,它们首先被替换。
- 替换文本随后被插入到程序中原来文本的位置。对于宏,参数名被他们的值替换。
- 最后,再次对结果文件进行扫描,看看它是否包含任何由#define定义的符号。如果是,就重复上述处理过程。
注意:
- 宏参数和#define 定义中可以出现其他#define定义的变量。但是对于宏,不能出现递归。
- 当预处理器搜索#define定义的符号的时候,字符串常量的内容并不被搜索
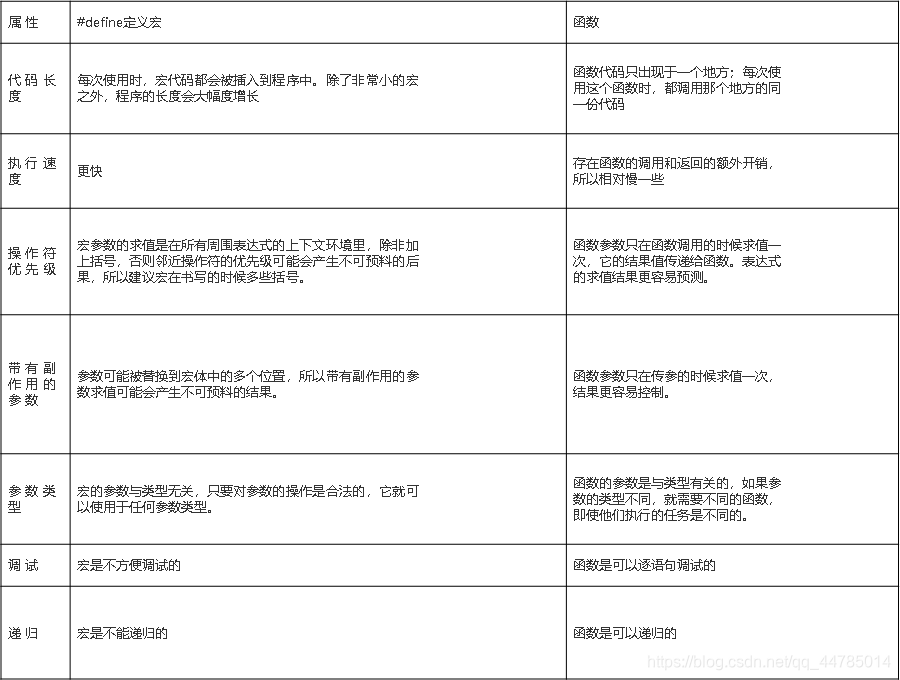
宏和函数的对比
命名约定
一般来讲函数的宏的使用语法很相似。所以语言本身没法帮我们区分二者。 那我们平时的一个习惯是:把宏名全部大写 函数名不要全部大写
