分析排序算法的考虑因素:
1、排序算法的执行效率
- 时间复杂度
- 比较次数和交换(或移动)次数
2、排序算法的内存消耗
原地排序算法,就是特指空间复杂度是 O(1) 的排序算法
3、排序算法的稳定性
待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变。
一、递归
使用递归算法解决问题需要满足以下的条件
- 一个问题的解可以分解为几个子问题的解
- 这个问题分解之后的子问题,除了处理数据规模不同,求解思路相同
- 存在递归终止条件(python中的最大递归深度为1000次)
递归实现:
# 递归算法
def fn(n):
if n == 1:
return 1
else:
return fn(n-1)+1
练习题:用递归的方式输出l=[‘jack’,(‘tom’,23),‘rose’,(14,55,67)] 列表内的每一个元素
def dp(s):
if isinstance(s,(int,str)):
print(s)
else:
for item in s:
dp(item)
l=['jack',('tom',23),'rose',(14,55,67)]
dp(l)
代码中的 isinstance()函数:是判别参量的数据类型,返回值True或False
二、冒泡排序(Bubble Sort)
冒泡排序(英语:Bubble Sort)需要重复地遍历要排序的数列,一次比较相邻的两个元素,如果他们的顺序错误就把他们交换过来。遍历数列的工作是重复地进行直到没有再需要交换,该数列已经排序完成。
# 冒泡排序
def bubble_sort(alist):
for j in range(len(alist)-1, 0, -1): # -1 代表倒序遍历,步长为1
# j表示每次遍历需要比较的次数,是逐渐减小的
for i in range(j):
if alist[i] > alist[i+1]: # 相邻元素比较
alist[i], alist[i+1] = alist[i+1], alist[i] # 数值交换
li = [54,26,93,17,77,31,44,55,20]
bubble_sort(li)
print(li)
冒泡排序的时间复杂度:
最好情况下,要排序的数据已经是有序的了,我们只需要进行一次冒泡操作,就可以结束了,所以最好情况时间复杂度是 O(n)。
而最坏的情况是,要排序的数据刚好是倒序排列的,我们需要进行 n 次冒泡操作,所以最坏情况时间复杂度为 O(n^2)。
三、选择排序(selection sort)
工作原理:(数据互相交换移动类型算法)
首先在未排序的序列中找到最小(大)的元素,存放到排序序列的起始位置(相当于起始元素和最小元素交换位置),然后,再从剩余未排序列中寻找最小元素,然后放至已排序列的末尾,重复以上操作,直到所有元素都已经排序完成。
选择排序的主要优点与数据移动有关。如果某个元素位于正确的最终位置上,则它不会被移动,元素相同也不会改变两个的顺序,这样保证了算法的稳定性。选择排序每次交换一对元素,它们当中至少有一个将被移到其最终位置上,因此对n个元素的表进行排序总共进行至多n-1次交换(循环条件)。
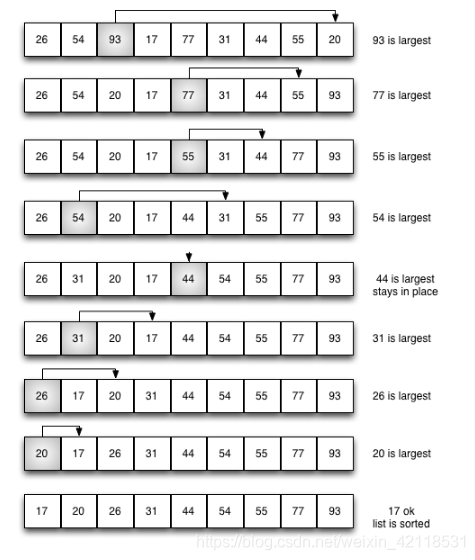
# 选择排序
'''
首先在未排序的序列中找到最小(大)的元素,存放到排序序列的起始位置(相当于起始元素和最小元素交换位置),然后,再从剩余未排序列中寻找最小元素,
然后放至已排序列的末尾,重复以上操作,直到所有元素都已经排序完成。
'''
li = [5,3,4,7,6,1,2,8,11,0,11,0,11.0]
def select_sort():
for i in range(len(li)-1): # 这里的范围是n-1 是因为排序完成操作需要n-1次循环次数
min_index = i # 最小元素的索引 初始值设定为起始元素
for j in range(min_index, len(li)): # 从min_index到末尾找到最小值
if li[j] < li[min_index]: # 如果列表中最小值不是j所指的元素 li[0]<li[min_index]
min_index = j # 交换最小元素的索引,使得min_index所指是未排序列表中的最小值
print("剩余未排序的列表元素中最小值:", li[min_index])
li[i], li[min_index] = li[min_index], li[i] # 最小元素和起始元素交换位置
print(li) # 输出每次排序后的序列
select_sort()
需要注意的是:选择排序算法对相同数据元素的处理,不能保证两元素顺序和未排序时相同,所以选择排序不是稳定的排序算法,时间复杂度为O(n^2)。
(选择排序的稳定性,和上面代码的if li[j] < li[min_index]: 语句有关,如果改为if li[j] <= li[min_index]: ,该选择排序就成为了稳定算法。)
选择排序优化
选择排序是循环一次找一个值,其实我们可以每次找2个值,一个最大和一个最小,这样就快了一半。
